Page¶
Class representing a document page. A page object is created by Document.load_page() or, equivalently, via indexing the document like doc[n] - it has no independent constructor.
There is a parent-child relationship between a document and its pages. If the document is closed or deleted, all page objects (and their respective children, too) in existence will become unusable (“orphaned”): If a page property or method is being used, an exception is raised.
Several page methods have a Document counterpart for convenience. At the end of this chapter you will find a synopsis.
Note
Many times in this chapter we are using the term coordinate. It is of high importance to have at least a basic understanding of what that is and that you feel comfortable with the section Coordinates.
Modifying Pages¶
Changing page properties and adding or changing page content is available for PDF documents only.
In a nutshell, this is what you can do with PyMuPDF:
Modify page rotation and the visible part (“cropbox”) of the page.
Insert images, other PDF pages, text and simple geometrical objects.
Add annotations and form fields.
Note
Methods require coordinates (points, rectangles) to put content in desired places. Please be aware that these coordinates must always be provided relative to the unrotated page (since v1.17.0). The reverse is also true: except Page.rect, resp. Page.bound() (both reflect when the page is rotated), all coordinates returned by methods and attributes pertain to the unrotated page.
So the returned value of e.g. Page.get_image_bbox() will not change if you do a Page.set_rotation(). The same is true for coordinates returned by Page.get_text(), annotation rectangles, and so on. If you want to find out, where an object is located in rotated coordinates, multiply the coordinates with Page.rotation_matrix. There also is its inverse, Page.derotation_matrix, which you can use when interfacing with other readers, which may behave differently in this respect.
Note
If you add or update annotations, links or form fields on the page and immediately afterwards need to work with them (i.e. without leaving the page), you should reload the page using Document.reload_page() before referring to these new or updated items.
Reloading the page is generally recommended – although not strictly required in all cases. However, some annotation and widget types have extended features in PyMuPDF compared to MuPDF. More of these extensions may also be added in the future.
Releoading the page ensures all your changes have been fully applied to PDF structures, so you can safely create Pixmaps or successfully iterate over annotations, links and form fields.
Method / Attribute |
Short Description |
|---|---|
PDF only: add a caret annotation |
|
PDF only: add a circle annotation |
|
PDF only: add a file attachment annotation |
|
PDF only: add a text annotation |
|
PDF only: add a “highlight” annotation |
|
PDF only: add an ink annotation |
|
PDF only: add a line annotation |
|
PDF only: add a polygon annotation |
|
PDF only: add a multi-line annotation |
|
PDF only: add a rectangle annotation |
|
PDF only: add a redaction annotation |
|
PDF only: add a “squiggly” annotation |
|
PDF only: add a “rubber stamp” annotation |
|
PDF only: add a “strike-out” annotation |
|
PDF only: add a comment |
|
PDF only: add an “underline” annotation |
|
PDF only: add a PDF Form field |
|
PDF only: a list of annotation (and widget) names |
|
PDF only: a list of annotation (and widget) xrefs |
|
return a generator over the annots on the page |
|
PDF only: process the redactions of the page |
|
PDF only: remove page content outside a rectangle |
|
rectangle of the page |
|
PDF only: bounding boxes of vector graphics |
|
PDF only: delete an annotation |
|
PDF only: delete an image |
|
PDF only: delete a link |
|
PDF only: delete a widget / field |
|
PDF only: draw a cubic Bezier curve |
|
PDF only: draw a circle |
|
PDF only: draw a special Bezier curve |
|
PDF only: draw a line |
|
PDF only: draw an oval / ellipse |
|
PDF only: connect a point sequence |
|
PDF only: draw a quad |
|
PDF only: draw a rectangle |
|
PDF only: draw a circular sector |
|
PDF only: draw a squiggly line |
|
PDF only: draw a zig-zagged line |
|
locate tables on the page |
|
get vector graphics on page |
|
PDF only: get list of referenced fonts |
|
PDF only: get bbox and matrix of embedded image |
|
get list of meta information for all used images |
|
PDF only: improved version of |
|
PDF only: get list of referenced images |
|
PDF only: return the label of the page |
|
get all links |
|
create a page image in raster format |
|
create a page image in SVG format |
|
extract the page’s text |
|
extract text contained in a rectangle |
|
create a TextPage with OCR for the page |
|
create a TextPage for the page |
|
PDF only: get list of referenced xobjects |
|
PDF only: insert a font for use by the page |
|
PDF only: insert an image |
|
PDF only: insert a link |
|
PDF only: insert text |
|
PDF only: insert html text in a rectangle |
|
PDF only: insert a text box |
|
return a generator of the links on the page |
|
PDF only: load a specific annotation |
|
PDF only: load a specific field |
|
return the first link on a page |
|
PDF only: create a new Shape |
|
PDF only: change the colorspace of objects |
|
PDF only: set page rotation to 0 |
|
PDF only: replace an image |
|
search for a string |
|
PDF only: modify |
|
PDF only: modify |
|
PDF only: modify the |
|
PDF only: modify |
|
PDF only: set page rotation |
|
PDF only: modify |
|
PDF only: display PDF page image |
|
PDF only: modify a link |
|
return a generator over the fields on the page |
|
write one or more TextWriter objects |
|
displacement of the |
|
the page’s |
|
the page’s |
|
the page’s |
|
the page’s |
|
PDF only: get coordinates in unrotated page space |
|
first Annot on the page |
|
first Link on the page |
|
first widget (form field) on the page |
|
bottom-right point of |
|
the page’s |
|
page number |
|
owning document object |
|
rectangle of the page |
|
PDF only: get coordinates in rotated page space |
|
PDF only: page rotation |
|
PDF only: translate between PDF and MuPDF space |
|
PDF only: page |
Class API
- class Page¶
- bound()¶
Determine the rectangle of the page. Same as property
Page.rect. For PDF documents this usually also coincides withmediaboxandcropbox, but not always. For example, if the page is rotated, then this is reflected by this method – thePage.cropboxhowever will not change.- Return type:
- add_caret_annot(point)¶
PDF only: Add a caret icon. A caret annotation is a visual symbol normally used to indicate the presence of text edits on the page.
- Parameters:
point (point_like) – the top left point of a 20 x 20 rectangle containing the MuPDF-provided icon.
- Return type:
- Returns:
the created annotation. Stroke color blue = (0, 0, 1), no fill color support.

Show/hide history
New in v1.16.0
- add_text_annot(point, text, icon='Note')¶
PDF only: Add a comment icon (“sticky note”) with accompanying text. Only the icon is visible, the accompanying text is hidden and can be visualized by many PDF viewers by hovering the mouse over the symbol.
- Parameters:
point (point_like) – the top left point of a 20 x 20 rectangle containing the MuPDF-provided “note” icon.
text (str) – the commentary text. This will be shown on double clicking or hovering over the icon. May contain any Latin characters.
icon (str) – choose one of “Note” (default), “Comment”, “Help”, “Insert”, “Key”, “NewParagraph”, “Paragraph” as the visual symbol for the embodied text [4]. (New in v1.16.0)
- Return type:
- Returns:
the created annotation. Stroke color yellow = (1, 1, 0), no fill color support.
- add_freetext_annot(rect, text, *, fontsize=11, fontname='helv', text_color=0, fill_color=None, border_width=0, dashes=None, callout=None, line_end=PDF_ANNOT_LE_OPEN_ARROW, opacity=1, align=TEXT_ALIGN_LEFT, rotate=0, richtext=False, style=None)¶
PDF only: Add text in a given rectangle. Optionally, the appearance of a “callout” shape can be requested by specifying two or three point-like objects – see below.
- Parameters:
rect (rect_like) – the rectangle into which the text should be inserted. Text is automatically wrapped to a new line at box width. Text portions not fitting into the rectangle will be invisible without warning.
text (str) – the text. May contain any mixture of Latin, Greek, Cyrillic, Chinese, Japanese and Korean characters. If
richtext=True(see below), the string is interpreted as HTML syntax. This adds a plethora of ways for attractive effects.fontsize (float) – the
fontsize. Default is 11. Ignored ifrichtext=True.fontname (str) –
The font name. Default is “Helv”. Ignored if
richtext=True, otherwise the following restritions apply:Accepted alternatives are “Helv” (Helvetica), “Cour” (Courier), “TiRo” (Timnes-Roman), “ZaDb” (ZapfDingBats) and “Symb” (Symbol). The name may be abbreviated to the first two characters, like “Co” for “Cour”, lower case accepted.
Bold or italic variants of the fonts are not supported.
text_color (list,tuple,float) – the text color. Default is black. Ignored if
richtext=True.fill_color (list,tuple,float) – the fill color. This is used for
rectand the end point of the callout lines when applicable. Default isNone.border_color (list,tuple,float) – This parameter only has an effect if
richtext=True. Otherwise,text_coloris used.border_width (float) – the width of border and
calloutlines. Default is 0 (no border), in which case callout lines may still appear with some hairline width, depending on the PDF viewer used. In any case, this value must be positive to see a border line.dashes (list,tuple) – a list of floats specifying how border and callout lines should be dashed. Default is
None.callout (list,tuple) – a list / tuple of two or three
point_likeobjects, which will be interpreted as end point [, knee point] and start point (in this sequence) of up to two line segments, converting this annotation into a call-out shape.line_end (int) – the line end symbol of the call-out line. It is drawn at the first point specified in the
calloutlist. Default is an open arrow. For possible values see Annotation Line Ending Styles.opacity (float) – a float
0 <= opacity < 1turning the annotation transparent. Default is no transparency.align (int) – text alignment, one of TEXT_ALIGN_LEFT, TEXT_ALIGN_CENTER, TEXT_ALIGN_RIGHT - justify is not supported. Ignored if
richtext=True.rotate (int) – the text orientation. Accepted values are integer multiples of 90°. Invalid entries receive a rotation of 0.
richtext (bool) – treat
textas HTML syntax. This allows to achieve bold, italic, arbitrary text colors, font sizes, text alignment including justify and more - as far as the PDF subset of HTML and styling instructions supports this. This is similar to what happens inPage.insert_htmlbox(). The base library will for example pull in required fonts if it encounters characters not contained in the standard ones. Some parameters are ignored if this option is set, as mentioned above. Default isFalse.style (str) – supply optional HTML styling information in CSS syntax. Ignored if
richtext=False.
- Return type:
- Returns:
the created annotation.
Show/hide history
Changed in v1.19.6: add border color parameter
- add_file_annot(point, buffer_, filename, ufilename=None, desc=None, icon='PushPin')¶
PDF only: Add a file attachment annotation with a “PushPin” icon at the specified location.
- Parameters:
pos (point_like) – the top-left point of a 18x18 rectangle containing the MuPDF-provided “PushPin” icon.
buffer (bytes,bytearray,BytesIO) –
the data to be stored (actual file content, any data, etc.).
Changed in v1.14.13: io.BytesIO is now also supported.
filename (str) – the filename to associate with the data.
ufilename (str) – the optional PDF unicode version of filename. Defaults to filename.
desc (str) – an optional description of the file. Defaults to filename.
icon (str) – choose one of “PushPin” (default), “Graph”, “Paperclip”, “Tag” as the visual symbol for the attached data [4]. (New in v1.16.0)
- Return type:
- Returns:
the created annotation. Stroke color yellow = (1, 1, 0), no fill color support.
- add_ink_annot(list)¶
PDF only: Add a “freehand” scribble annotation.
- Parameters:
list (sequence) – a list of one or more lists, each containing
point_likeitems. Each item in these sublists is interpreted as a Point through which a connecting line is drawn. Separate sublists thus represent separate drawing lines.- Return type:
- Returns:
the created annotation in default appearance black =(0, 0, 0),line width 1. No fill color support.
- add_line_annot(p1, p2)¶
PDF only: Add a line annotation.
- Parameters:
p1 (point_like) – the starting point of the line.
p2 (point_like) – the end point of the line.
- Return type:
- Returns:
the created annotation. It is drawn with line (stroke) color red = (1, 0, 0) and line width 1. No fill color support. The annot rectangle is automatically created to contain both points, each one surrounded by a circle of radius 3 * line width to make room for any line end symbols.
- add_rect_annot(rect)¶
- add_circle_annot(rect)¶
PDF only: Add a rectangle, resp. circle annotation.
- Parameters:
rect (rect_like) – the rectangle in which the circle or rectangle is drawn, must be finite and not empty. If the rectangle is not equal-sided, an ellipse is drawn.
- Return type:
- Returns:
the created annotation. It is drawn with line (stroke) color red = (1, 0, 0), line width 1, fill color is supported.
Redactions¶
- add_redact_annot(quad, text=None, fontname=None, fontsize=11, align=TEXT_ALIGN_LEFT, fill=(1, 1, 1), text_color=(0, 0, 0), cross_out=True)¶
PDF only: Add a redaction annotation. A redaction annotation identifies an area whose content should be removed from the document. Adding such an annotation is the first of two steps. It makes visible what will be removed in the subsequent step,
Page.apply_redactions().- Parameters:
quad (quad_like,rect_like) – specifies the (rectangular) area to be removed which is always equal to the annotation rectangle. This may be a
rect_likeorquad_likeobject. If a quad is specified, then the enveloping rectangle is taken.text (str) – text to be placed in the rectangle after applying the redaction (and thus removing old content). (New in v1.16.12)
fontname (str) – the font to use when
textis given, otherwise ignored. Only CJK and the PDF Base 14 Fonts are supported. Apart from this, the same rules apply as forPage.insert_textbox()– which is what the methodPage.apply_redactions()internally invokes.fontsize (float) – the
fontsizeto use for the replacing text. If the text is too large to fit, several insertion attempts will be made, gradually reducing thefontsizeto no less than 4. If then the text will still not fit, no text insertion will take place at all. (New in v1.16.12)align (int) – the horizontal alignment for the replacing text. See
insert_textbox()for available values. The vertical alignment is (approximately) centered.fill (sequence) – the fill color of the rectangle after applying the redaction. The default is white = (1, 1, 1), which is also taken if
Noneis specified. To suppress a fill color altogether, specifyFalse. In this cases the rectangle remains transparent. (New in v1.16.12)text_color (sequence) – the color of the replacing text. Default is black = (0, 0, 0). (New in v1.16.12)
cross_out (bool) – add two diagonal lines to the annotation rectangle. (New in v1.17.2)
- Return type:
- Returns:
the created annotation. Its standard appearance looks like a red rectangle (no fill color), optionally showing two diagonal lines. Colors, line width, dashing, opacity and blend mode can now be set and applied via
Annot.update()like with other annotations. (Changed in v1.17.2)

Show/hide history
New in v1.16.11
- apply_redactions(images=PDF_REDACT_IMAGE_PIXELS | 2, graphics=PDF_REDACT_LINE_ART_REMOVE_IF_COVERED | 1, text=PDF_REDACT_TEXT_REMOVE | 0)¶
PDF only: Remove all content contained in any redaction rectangle on the page.
This method applies and then deletes all redactions from the page.
- Parameters:
images (int) – How to redact overlapping images. The default
PDF_REDACT_IMAGE_PIXELS | 2blanks out overlapping pixels.PDF_REDACT_IMAGE_NONE | 0ignores, andPDF_REDACT_IMAGE_REMOVE | 1completely removes images overlapping any redaction annotation. OptionPDF_REDACT_IMAGE_REMOVE_UNLESS_INVISIBLE | 3only removes images that are actually visible.graphics (int) – How to redact overlapping vector graphics (also called “line-art” or “drawings”). The default
PDF_REDACT_LINE_ART_REMOVE_IF_COVERED | 1removes any overlapping vector graphics.PDF_REDACT_LINE_ART_NONE | 0ignores, andPDF_REDACT_LINE_ART_REMOVE_IF_TOUCHED | 2removes graphics fully contained in a redaction annotation. When removing line-art, please be aware that stroked vector graphics (i.e. type “s” or “sf”) have a larger wrapping rectangle than one might expect: first of all, at least 50% of the path’s line width have to be added in each direction to truly include all of the drawing. If a so-called “miter limit” is provided (see page 121 of the PDF specification), the enlarging value ismiter * width / 2. So, when letting everything default (width = 1, miter = 10), the redaction rectangle should be at least 5 points larger in every direction.text (int) – Whether to redact overlapping text. The default
PDF_REDACT_TEXT_REMOVE | 0removes all characters whose boundary box overlaps any redaction rectangle. This complies with the original legal / data protection intentions of redaction annotations. Other use cases however may require to keep text while redacting vector graphics or images. This can be achieved by settingtext=True|PDF_REDACT_TEXT_NONE | 1. This does not comply with the data protection intentions of redaction annotations. Do so at your own risk.
- Returns:
Trueif at least one redaction annotation has been processed,Falseotherwise.
Note
Text contained in a redaction rectangle will be physically removed from the page (assuming
Document.save()with a suitable garbage option) and will no longer appear in e.g. text extractions or anywhere else. All redaction annotations will also be removed. Other annotations are unaffected.All overlapping links will be removed. If the rectangle of the link was covering text, then only the overlapping part of the text is being removed. Similar applies to images covered by link rectangles.
The overlapping parts of images will be blanked-out for default option
PDF_REDACT_IMAGE_PIXELS(changed in v1.18.0). Option 0 does not touch any images and 1 will remove any image with an overlap.For option
images=PDF_REDACT_IMAGE_REMOVEonly this page’s references to the images are removed - not necessarily the images themselves. Images are completely removed from the file only, if no longer referenced at all (assuming suitable garbage collection options).For option
images=PDF_REDACT_IMAGE_PIXELSa new image of format PNG is created, which the page will use in place of the original one. The original image is not deleted or replaced as part of this process, so other pages may still show the original. In addition, the new, modified PNG image currently is stored uncompressed. Do keep these aspects in mind when choosing the right garbage collection method and compression options during save.Text removal is done by character: A character is removed if its bbox has a non-empty overlap with a redaction rectangle (changed in MuPDF v1.17). Depending on the font properties and / or the chosen line height, deletion may occur for undesired text parts. Using
Tools.set_small_glyph_heights()with aTrueargument before text search may help to prevent this.Redactions are a simple way to replace single words in a PDF, or to just physically remove them. Locate the word “secret” using some text extraction or search method and insert a redaction using “xxxxxx” as replacement text for each occurrence.
Be wary if the replacement is longer than the original – this may lead to an awkward appearance, line breaks or no new text at all.
For a number of reasons, the new text may not exactly be positioned on the same line like the old one – especially true if the replacement font was not one of CJK or PDF Base 14 Fonts.
Show/hide history
New in v1.16.11
Changed in v1.16.12: The previous mark parameter is gone. Instead, the respective rectangles are filled with the individual fill color of each redaction annotation. If a text was given in the annotation, then
insert_textbox()is invoked to insert it, using parameters provided with the redaction.Changed in v1.18.0: added option for handling images that overlap redaction areas.
Changed in v1.23.27: added option for removing graphics as well.
Changed in v1.24.2: added option
keep_textto leave text untouched.
- add_polyline_annot(points)¶
- add_polygon_annot(points)¶
PDF only: Add an annotation consisting of lines which connect the given points. A Polygon’s first and last points are automatically connected, which does not happen for a PolyLine. The rectangle is automatically created as the smallest rectangle containing the points, each one surrounded by a circle of radius 3 (= 3 * line width). The following shows a ‘PolyLine’ that has been modified with colors and line ends.
- Parameters:
points (list) – a list of
point_likeobjects.- Return type:
- Returns:
the created annotation. It is drawn with line color black, line width 1 no fill color but fill color support. Use methods of Annot to make any changes to achieve something like this:

- add_underline_annot(quads=None, start=None, stop=None, clip=None)¶
- add_strikeout_annot(quads=None, start=None, stop=None, clip=None)¶
- add_squiggly_annot(quads=None, start=None, stop=None, clip=None)¶
- add_highlight_annot(quads=None, start=None, stop=None, clip=None)¶
PDF only: These annotations are normally used for marking text which has previously been somehow located (for example via
Page.search_for()). But this is not required: you are free to “mark” just anything.Standard (stroke only – no fill color support) colors are chosen per annotation type: yellow for highlighting, red for striking out, green for underlining, and magenta for wavy underlining.
All these four methods convert the arguments into a list of Quad objects. The annotation rectangle is then calculated to envelop all these quadrilaterals.
Note
search_for()delivers a list of either Rect or Quad objects. Such a list can be directly used as an argument for these annotation types and will deliver one common annotation for all occurrences of the search string:>>> # prefer quads=True in text searching for annotations! >>> quads = page.search_for("pymupdf", quads=True) >>> page.add_highlight_annot(quads)
Note
Obviously, text marker annotations need to know what is the top, the bottom, the left, and the right side of the area(s) to be marked. If the arguments are quads, this information is given by the sequence of the quad points. In contrast, a rectangle delivers much less information – this is illustrated by the fact, that 4! = 24 different quads can be constructed with the four corners of a rectangle.
Therefore, we strongly recommend to use the
quadsoption for text searches, to ensure correct annotations. A similar consideration applies to marking text spans extracted with the “dict” / “rawdict” options ofPage.get_text(). For more details on how to compute quadrilaterals in this case, see section “How to Mark Non-horizontal Text” of FAQ.- Parameters:
quads (rect_like,quad_like,list,tuple) – the location(s) – rectangle(s) or quad(s) – to be marked. (Changed in v1.14.20) A list or tuple must consist of
rect_likeorquad_likeitems (or even a mixture of either). Every item must be finite, convex and not empty (as applicable). Set this parameter toNoneif you want to use the following arguments (Changed in v1.16.14). And vice versa: if notNone, the remaining parameters must beNone.start (point_like) – start text marking at this point. Defaults to the top-left point of clip. Must be provided if
quadsisNone. (New in v1.16.14)stop (point_like) – stop text marking at this point. Defaults to the bottom-right point of clip. Must be used if
quadsisNone. (New in v1.16.14)clip (rect_like) – only consider text lines intersecting this area. Defaults to the page rectangle. Only use if
startandstopare provided. (New in v1.16.14)
- Return type:
Annot or
None(changed in v1.16.14).- Returns:
the created annotation. If quads is an empty list, no annotation is created (changed in v1.16.14).
Note
You can use parameters start, stop and clip to highlight consecutive lines between the points start and stop (starting with v1.16.14). Make use of clip to further reduce the selected line bboxes and thus deal with e.g. multi-column pages. The following multi-line highlight on a page with three text columns was created by specifying the two red points and setting clip accordingly.

- cluster_drawings(clip=None, drawings=None, x_tolerance=3, y_tolerance=3, final_filter=True)¶
Cluster vector graphics (synonyms are line-art or drawings) based on their geometrical vicinity. The method walks through the output of
Page.get_drawings()and joins paths whosepath["rect"]are closer to each other than some tolerance values (given in the arguments). The result is a list of rectangles that each wrap things like tables (with gridlines), pie charts, bar charts, etc.- Parameters:
clip (rect_like) – only consider paths inside this area. The default is the full page.
drawings (list) – (optional) provide a previously generated output of
Page.get_drawings(). IfNonethe method will execute the method.y_tolerance (float x_tolerance /) – Assume vector graphics to be close enough neighbors for belonging to the same rectangle. Default is 3 points.
final_filter (bool) – If
True(default), the method will to remove rectangles having width or height smaller than the respective tolerance value. IfFalseno such filtering is done.
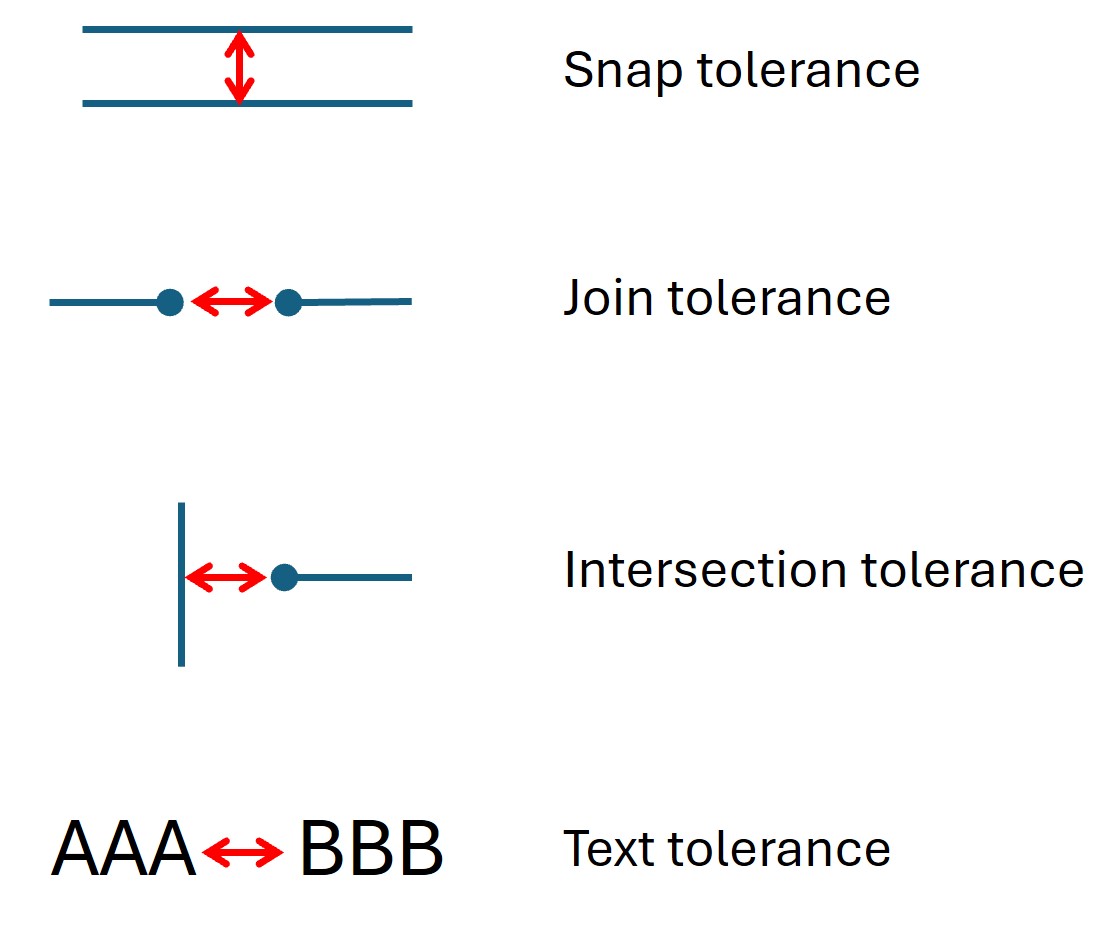
- find_tables(clip=None, strategy=None, vertical_strategy=None, horizontal_strategy=None, vertical_lines=None, horizontal_lines=None, snap_tolerance=None, snap_x_tolerance=None, snap_y_tolerance=None, join_tolerance=None, join_x_tolerance=None, join_y_tolerance=None, edge_min_length=3, min_words_vertical=3, min_words_horizontal=1, intersection_tolerance=None, intersection_x_tolerance=None, intersection_y_tolerance=None, text_tolerance=None, text_x_tolerance=None, text_y_tolerance=None, add_lines=None, add_boxes=None, paths=None)¶
Find tables on the page and return an object with related information. Typically, the default values of the many parameters will be sufficient. Adjustments should ever only be needed in corner case situations.
- Parameters:
clip (rect_like) – specify a region to consider within the page rectangle and ignore the rest. Default is the full page.
strategy (str) –
Request a table detection strategy. Valid values are “lines”, “lines_strict” and “text”.
Default is “lines” which uses all vector graphics on the page to detect grid lines.
Strategy “lines_strict” ignores borderless rectangle vector graphics. Sometimes single text pieces have background colors which may lead to false columns or lines. This strategy ignores them and can thus increase detection precision.
If “text” is specified, text positions are used to generate “virtual” column and / or row boundaries. Use
min_words_*to request the number of words for considering their coordinates.Use parameters
vertical_strategyandhorizontal_strategyinstead for a more fine-grained treatment of the dimensions.horizontal_lines (sequence[floats]) – y-coordinates of rows. If provided, there will be no attempt to identify additional table rows. This influences table detection.
vertical_lines (sequence[floats]) – x-coordinates of columns. If provided, there will be no attempt to identify additional table columns. This influences table detection.
min_words_vertical (int) – relevant for vertical strategy option “text”: at least this many words must coincide to establish a virtual column boundary.
min_words_horizontal (int) – relevant for horizontal strategy option “text”: at least this many words must coincide to establish a virtual row boundary.
snap_tolerance (float) – Any two horizontal lines whose y-values differ by no more than this value will be snapped into one. Accordingly for vertical lines. Default is 3. Separate values can be specified instead for the dimensions, using
snap_x_toleranceandsnap_y_tolerance.join_tolerance (float) – Any two lines will be joined to one if the end and the start points differ by no more than this value (in points). Default is 3. Instead of this value, separate values can be specified for the dimensions using
join_x_toleranceandjoin_y_tolerance.edge_min_length (float) – Ignore a line if its length does not exceed this value (points). Default is 3.
intersection_tolerance (float) – When combining lines into cell borders, orthogonal lines must be within this value (points) to be considered intersecting. Default is 3. Instead of this value, separate values can be specified for the dimensions using
intersection_x_toleranceandintersection_y_tolerance.text_tolerance (float) – Characters will be combined into words only if their distance is no larger than this value (points). Default is 3. Instead of this value, separate values can be specified for the dimensions using
text_x_toleranceandtext_y_tolerance.add_lines (tuple,list) – Specify a list of “lines” (i.e. pairs of
point_likeobjects) as additional, “virtual” vector graphics. These lines may help with table and / or cell detection and will not otherwise influence the detection strategy. Especially, in contrast to parametershorizontal_linesandvertical_lines, they will not prevent detecting rows or columns in other ways. These lines will be treated exactly like “real” vector graphics in terms of joining, snapping, intersecting, minimum length and containment in thecliprectangle. Similarly, lines not parallel to any of the coordinate axes will be ignored.add_boxes (tuple,list) – Specify a list of rectangles (
rect_likeobjects) as additional, “virtual” vector graphics. These rectangles may help with table and / or cell detection and will not otherwise influence the detection strategy. Especially, in contrast to parametershorizontal_linesandvertical_lines, they will not prevent detecting rows or columns in other ways. These rectangles will be treated exactly like “real” vector graphics in terms of joining, snapping, intersecting, minimum length and containment in thecliprectangle.paths (list) – list of vector graphics in the format as returned be
Page.get_drawings(). Using this parameter will prevent the method to extract vector graphics itself. This is useful if the vector graphics are already available. This can save execution time significantly.
- Returns:
a
TableFinderobject that has the following significant attributes:cells: a list of all bboxes on the page, that have been identified as table cells (across all tables). Each cell is arect_liketuple(x0, y0, x1, y1)of coordinates orNone.tables: a list ofTableobjects. This is[]if the page has no tables. Single tables can be found as items of this list. But theTableFinderobject itself is also a sequence of its tables. This means that iftabsis aTableFinderobject, then table “n” is delivered bytabs.tables[n]as well as by the shortertabs[n].The
Tableobject has the following attributes:bbox: the bounding box of the table as a tuple(x0, y0, x1, y1).cells: bounding boxes of the table’s cells (list of tuples). A cell may also beNone.extract(): this method returns the text content of each table cell as a list of list of strings.to_markdown(): this method returns the table as a string in markdown format (compatible to Github). Markdown viewers can render the string as a table. This output is optimized for small token sizes, which is especially beneficial for LLM/RAG feeds. Pandas DataFrames (see methodto_pandas()below) offer an equivalent markdown table output which however is better readable for the human eye. Any line breaks (\n) in cells are replaced by HTML line breaks tags<br>.to_pandas(): this method returns the table as a pandas DataFrame. DataFrames are very versatile objects allowing a plethora of table manipulation methods and outputs to almost 20 well-known formats, among them Excel files, CSV, JSON, markdown-formatted tables and more.DataFrame.to_markdown()generates a Github-compatible markdown format optimized for human readability. This method however requires the package tabulate to be installed in addition to pandas itself.header: aTableHeaderobject containing header information of the table.col_count: an integer containing the number of table columns.row_count: an integer containing the number of table rows.rows: a list ofTableRowobjects containing two attributes,bboxis the boundary box of the row, andcellsis a list of table cells contained in this row.
The
TableHeaderobject has the following attributes:bbox: the bounding box of the header.cells: a list of bounding boxes containing the name of the respective column.names: a list of strings containing the text of each of the cell bboxes. They represent the column names – which are used when exporting the table to pandas DataFrames, markdown, etc.external: a bool indicating whether the header bbox is outside the table body (True) or not. Table headers are never identified by theTableFinderlogic. Therefore, ifexternalis true, then the header cells are not part of any cell identified byTableFinder. Ifexternal == False, then the first table row is the header.
Please have a look at these Jupyter notebooks, which cover standard situations like multiple tables on one page or joining table fragments across multiple pages.
Caution
The lifetime of the
TableFinderobject, as well as that of all its tables equals the lifetime of the page. If the page object is deleted or reassigned, all tables are no longer valid.The only way to keep table content beyond the page’s availability is to extract it via methods
Table.to_markdown(),Table.to_pandas()or a copy ofTable.extract()(e.g.Table.extract()[:]).Note
Once a table has been extracted to a Pandas DataFrame with
to_pandas()it is easy to convert to other file types with the Pandas API:
Show/hide history
New in version 1.23.0
Changed in version 1.23.19: new argument
add_lines.
Important
There is also the pdf2docx extract tables method which is capable of table extraction if you prefer.
- add_stamp_annot(rect, stamp=0)¶
PDF only: Add a “rubber stamp” annotation to e.g. indicate the document’s intended use (“DRAFT”, “CONFIDENTIAL”, etc.). The parameter may be either an integer to select text from a predefined array of standard texts or an image.
- Parameters:
rect (rect_like) – rectangle where to place the annotation.
stamp (multiple) –
The following options are available:
The id number (int) of the stamp text. For available stamps see Stamp Annotation Icons.
A string specifying an image file path.
A
bytes,bytearrayorio.BytesIOobject for an image in memory.A Pixmap.
Text-based stamps
Annot.rectis automatically calculated as the largest rectangle with an aspect ratio ofwidth:height = 3.8that fits in the providedrect. Its position is vertically and horizontally centered.The font chosen is “Times Bold” and the text will be upper case.
The appearance can be modified using
Annot.set_opacity()and by setting the “stroke” color. By PDF specification, stamp annotations have no “fill” color.

Image-based stamps
The image is scaled to fit into the rectangle Rect such that the image’s center and the center of Rect coincide. The aspect ratio of the image is preserved, so the image may not fill the entire rectangle. However, at least one of the given rectangle’s width or height are fully covered.
The annotation can be modified via
Annot.set_opacity(). This method therefore is a way to display images transparently even if no alpha channel is present.Setting colors has no effect on image stamps.
Rotating image-based stamps is not supported. Setting the rotation may lead to unexpected results.
- add_widget(widget)¶
PDF only: Add a PDF Form field (“widget”) to a page. This also turns the PDF into a Form PDF. Because of the large amount of different options available for widgets, we have developed a new class Widget, which contains the possible PDF field attributes. It must be used for both, form field creation and updates.
- delete_annot(annot)¶
The removal will now include any bound ‘Popup’ or response annotations and related objects (changed in v1.16.6).
PDF only: Delete annotation from the page and return the next one.
- delete_widget(widget)¶
PDF only: Delete field from the page and return the next one.
- Parameters:
widget (Widget) – the widget to be deleted.
- Return type:
- Returns:
the widget following the deleted one. Please remember that physical removal requires saving to a new file with garbage > 0.
Show/hide history
(New in v1.18.4)
- delete_link(linkdict)¶
PDF only: Delete the specified link from the page. The parameter must be an original item of
get_links(), see Description of get_links() Entries. The reason for this is the dictionary’s “xref” key, which identifies the PDF object to be deleted.- Parameters:
linkdict (dict) – the link to be deleted.
- insert_link(linkdict)¶
PDF only: Insert a new link on this page. The parameter must be a dictionary of format as provided by
get_links(), see Description of get_links() Entries.- Parameters:
linkdict (dict) – the link to be inserted.
- update_link(linkdict)¶
PDF only: Modify the specified link. The parameter must be a (modified) original item of
get_links(), see Description of get_links() Entries. The reason for this is the dictionary’s “xref” key, which identifies the PDF object to be changed.- Parameters:
linkdict (dict) – the link to be modified.
Warning
If updating / inserting a URI link (
"kind": LINK_URI), please make sure to start the value for the"uri"key with a disambiguating string like"http://","https://","file://","ftp://","mailto:", etc. Otherwise – depending on your browser or other “consumer” software – unexpected default assumptions may lead to unwanted behaviours.
- get_label()¶
PDF only: Return the label for the page.
- Return type:
str
- Returns:
the label string like “vii” for Roman numbering or “” if not defined.
Show/hide history
New in v1.18.6
- get_links()¶
Retrieves all links of a page.
- Return type:
list
- Returns:
A list of dictionaries. For a description of the dictionary entries, see Description of get_links() Entries. Always use this or the
Page.links()method if you intend to make changes to the links of a page.
- links(kinds=None)¶
Return a generator over the page’s links. The results equal the entries of
Page.get_links().- Parameters:
kinds (sequence) – a sequence of integers to down-select to one or more link kinds. Default is all links. Example: kinds=(pymupdf.LINK_GOTO,) will only return internal links.
- Return type:
generator
- Returns:
an entry of
Page.get_links()for each iteration.
Show/hide history
New in v1.16.4
- annots(types=None)¶
Return a generator over the page’s annotations.
- Parameters:
types (sequence) – a sequence of integers to down-select to one or more annotation types. Default is all annotations. Example:
types=(pymupdf.PDF_ANNOT_FREETEXT, pymupdf.PDF_ANNOT_TEXT)will only return ‘FreeText’ and ‘Text’ annotations.- Return type:
generator
- Returns:
an Annot for each iteration.
Caution
You cannot safely update annotations from within this generator. This is because most annotation updates require reloading the page via
page = doc.reload_page(page). To circumvent this restriction, make a list of annotations xref numbers first and then iterate over these numbers:In [4]: xrefs = [annot.xref for annot in page.annots(types=[...])] In [5]: for xref in xrefs: ...: annot = page.load_annot(xref) ...: annot.update() ...: page = doc.reload_page(page) In [6]:
Show/hide history
New in v1.16.4
- widgets(types=None)¶
Return a generator over the page’s form fields.
- Parameters:
types (sequence) – a sequence of integers to down-select to one or more widget types. Default is all form fields. Example:
types=(pymupdf.PDF_WIDGET_TYPE_TEXT,)will only return ‘Text’ fields.- Return type:
generator
- Returns:
a Widget for each iteration.
Show/hide history
New in v1.16.4
- write_text(rect=None, writers=None, overlay=True, color=None, opacity=None, keep_proportion=True, rotate=0, oc=0)¶
PDF only: Write the text of one or more TextWriter objects to the page.
- Parameters:
rect (rect_like) – where to place the text. If omitted, the rectangle union of the text writers is used.
writers (sequence) – a non-empty tuple / list of TextWriter objects or a single TextWriter.
opacity (float) – set transparency, overwrites resp. value in the text writers.
color (sequ) – set the text color, overwrites resp. value in the text writers.
overlay (bool) – put the text in foreground or background.
keep_proportion (bool) – maintain the aspect ratio.
rotate (float) – rotate the text by an arbitrary angle.
Note
Parameters overlay, keep_proportion, rotate and oc have the same meaning as in
Page.show_pdf_page().Show/hide history
New in v1.16.18
- insert_text(point, text, *, fontsize=11, fontname='helv', fontfile=None, idx=0, color=None, fill=None, render_mode=0, miter_limit=1, border_width=0.05, encoding=TEXT_ENCODING_LATIN, rotate=0, morph=None, stroke_opacity=1, fill_opacity=1, overlay=True, oc=0)¶
PDF only: Insert text lines starting at
point_likepoint. SeeShape.insert_text().Show/hide history
Changed in v1.18.4
- insert_textbox(rect, buffer, *, align=TEXT_ALIGN_LEFT, border_width=1, color=None, encoding=TEXT_ENCODING_LATIN, expandtabs=8, fill=None, fill_opacity=1, fontfile=None, fontname='helv', fontsize=11, lineheight=None, miter_limit=1, morph=None, oc=0, overlay=True, render_mode=0, rotate=0, set_simple=False, stroke_opacity=1)¶
PDF only: Insert text into the specified
rect_likerect.- Parameters:
overlay – see
Shape.commit().
For other args, see
Shape.insert_textbox.Show/hide history
Changed in v1.18.4
- insert_htmlbox(rect, text, *, css=None, scale_low=0, archive=None, rotate=0, oc=0, opacity=1, overlay=True)¶
PDF only: Insert text into the specified rectangle. The method has similarities with methods
Page.insert_textbox()andTextWriter.fill_textbox(), but is much more powerful. This is achieved by letting a Story object do all the required processing.Parameter
textmay be a string as in the other methods. But it will be interpreted as HTML source and may therefore also contain HTML language elements – including styling. Thecssparameter may be used to pass in additional styling instructions.Automatic line breaks are generated at word boundaries. The “soft hyphen” character
"­"(or­) can be used to cause hyphenation and thus may also cause line breaks. Forced line breaks however are only achievable via the HTML tag<br>-\nis ignored and will be treated like a space.With this method the following can be achieved:
Styling effects like bold, italic, text color, text alignment, font size or font switching.
The text may include arbitrary languages – including right-to-left languages.
Scripts like Devanagari and several others in Asia have a highly complex system of ligatures, where two or more unicodes together yield one glyph. The Story uses the software package HarfBuzz , to deal with these things and produce correct output.
One can also include images via HTML tag
<img>– the Story will take care of the appropriate layout. This is an alternative option to insert images, compared toPage.insert_image().HTML tables (tag
<table>) may be included in the text and will be handled appropriately.Links are automatically generated when present.
If content does not fit in the rectangle, the developer has two choices:
either only be informed about this (and accept a no-op, just like with the other textbox insertion methods),
or (
scale_low=0- the default) scale down the content until it fits.
- Parameters:
rect (rect_like) – rectangle on page to receive the text.
text (str,Story) – the text to be written. Can contain a mixture of plain text and HTML tags with styling instructions. Alternatively, a Story object may be specified (in which case the internal Story generation step will be omitted). A Story must have been generated with all required styling and Archive information.
css (str) – optional string containing additional CSS instructions. This parameter is ignored if
textis a Story. See CSS Support for more.scale_low (float) – if necessary, scale down the content until it fits in the target rectangle. This sets the down scaling limit. Default is 0, no limit. A value of 1 means no down-scaling permitted. A value of e.g. 0.2 means maximum down-scaling by 80%.
archive (Archive) – an Archive object that points to locations where to find images or non-standard fonts. If
textrefers to images or non-standard fonts, this parameter is required. This parameter is ignored iftextis a Story.rotate (int) –
one of the values 0, 90, 180, 270. Depending on this, text will be filled:
0: top-left to bottom-right.
90: bottom-left to top-right.
180: bottom-right to top-left.
270: top-right to bottom-left.

oc (int) – the xref of an
OCG/OCMDor 0. Please refer toPage.show_pdf_page()for details.opacity (float) – set the fill and stroke opacity of the content. Only values
0 <= opacity < 1are considered.overlay (bool) – put the text in front of other content. Please refer to
Page.show_pdf_page()for details.
- Returns:
A tuple of floats
(spare_height, scale).spare_height: The (positive) height of the remaining space in Rect below the text, or -1 if we failed to fit.
scale: The scaling required;
0 < scale <= 1. Will bescale_lowif we failed to fit.
Please refer to examples in this section of the recipes: How to Fill a Box with HTML Text.
Show/hide history
New in v1.26.5:
do additional scaling to fit long words.
If we succeeded and scaled down, the returned
spare_heightis now generally positive instead of being fixed to zero, because the final rect’s height is usually not an exact multiple of the font line height.
New in v1.23.8: rebased-only.
New in v1.23.9:
opacityparameter.
Drawing Methods
- draw_line(p1, p2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a line from p1 to p2 (
point_likes). SeeShape.draw_line().Show/hide history
Changed in v1.18.4
- draw_zigzag(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a zigzag line from p1 to p2 (
point_likes). SeeShape.draw_zigzag().Show/hide history
Changed in v1.18.4
- draw_squiggle(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a squiggly (wavy, undulated) line from p1 to p2 (
point_likes). SeeShape.draw_squiggle().Show/hide history
Changed in v1.18.4
- draw_circle(center, radius, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a circle around center (
point_like) with a radius of radius. SeeShape.draw_circle().Show/hide history
Changed in v1.18.4
- draw_oval(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw an oval (ellipse) within the given
rect_likeorquad_like. SeeShape.draw_oval().Show/hide history
Changed in v1.18.4
- draw_sector(center, point, angle, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, fullSector=True, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a circular sector, optionally connecting the arc to the circle’s center (like a piece of pie). See
Shape.draw_sector().Show/hide history
Changed in v1.18.4
- draw_polyline(points, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw several connected lines defined by a sequence of
point_likes. SeeShape.draw_polyline().Show/hide history
Changed in v1.18.4
- draw_bezier(p1, p2, p3, p4, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a cubic Bézier curve from p1 to p4 with the control points p2 and p3 (all are
point_likes). SeeShape.draw_bezier().Show/hide history
Changed in v1.18.4
- draw_curve(p1, p2, p3, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: This is a special case of draw_bezier(). See
Shape.draw_curve().Show/hide history
Changed in v1.18.4
- draw_rect(rect, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, radius=None, oc=0)¶
PDF only: Draw a rectangle. See
Shape.draw_rect().Show/hide history
Changed in v1.18.4
Changed in v1.22.0: Added parameter radius.
- draw_quad(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF only: Draw a quadrilateral. See
Shape.draw_quad().Show/hide history
Changed in v1.18.4
- insert_font(fontname='helv', fontfile=None, fontbuffer=None, set_simple=False, encoding=TEXT_ENCODING_LATIN)¶
PDF only: Add a new font to be used by text output methods and return its
xref. If not already present in the file, the font definition will be added. Supported are the built-inBase14_Fontsand the CJK fonts via “reserved” fontnames. Fonts can also be provided as a file path or a memory area containing the image of a font file.- Parameters:
fontname (str) –
The name by which this font shall be referenced when outputting text on this page. In general, you have a “free” choice here (but consult the Adobe PDF References, page 16, section 7.3.5 for a formal description of building legal PDF names). However, if it matches one of the
Base14_Fontsor one of the CJK fonts, fontfile and fontbuffer are ignored.In other words, you cannot insert a font via fontfile / fontbuffer and also give it a reserved fontname.
Note
A reserved fontname can be specified in any mixture of upper or lower case and still match the right built-in font definition: fontnames “helv”, “Helv”, “HELV”, “Helvetica”, etc. all lead to the same font definition “Helvetica”. But from a Page perspective, these are different references. You can exploit this fact when using different encoding variants (Latin, Greek, Cyrillic) of the same font on a page.
fontfile (str) – a path to a font file. If used, fontname must be different from all reserved names.
fontbuffer (bytes/bytearray) – the memory image of a font file. If used, fontname must be different from all reserved names. This parameter would typically be used with
Font.bufferfor fonts supported / available via Font.set_simple (int) – applicable for fontfile / fontbuffer cases only: enforce treatment as a “simple” font, i.e. one that only uses character codes up to 255.
encoding (int) – applicable for the “Helvetica”, “Courier” and “Times” sets of
Base14_Fontsonly. Select one of the available encodings Latin (0), Cyrillic (2) or Greek (1). Only use the default (0 = Latin) for “Symbol” and “ZapfDingBats”.
- Rytpe:
int
- Returns:
the
xrefof the installed font.
Note
Built-in fonts will not lead to the inclusion of a font file. So the resulting PDF file will remain small. However, your PDF viewer software is responsible for generating an appropriate appearance – and there exist differences on whether or how each one of them does this. This is especially true for the CJK fonts. But also Symbol and ZapfDingbats are incorrectly handled in some cases. Following are the Font Names and their correspondingly installed Base Font names:
Base-14 Fonts [1]
Font Name
Installed Base Font
Comments
helv
Helvetica
normal
heit
Helvetica-Oblique
italic
hebo
Helvetica-Bold
bold
hebi
Helvetica-BoldOblique
bold-italic
cour
Courier
normal
coit
Courier-Oblique
italic
cobo
Courier-Bold
bold
cobi
Courier-BoldOblique
bold-italic
tiro
Times-Roman
normal
tiit
Times-Italic
italic
tibo
Times-Bold
bold
tibi
Times-BoldItalic
bold-italic
symb
Symbol
zadb
ZapfDingbats
CJK Fonts [2] (China, Japan, Korea)
Font Name
Installed Base Font
Comments
china-s
Heiti
simplified Chinese
china-ss
Song
simplified Chinese (serif)
china-t
Fangti
traditional Chinese
china-ts
Ming
traditional Chinese (serif)
japan
Gothic
Japanese
japan-s
Mincho
Japanese (serif)
korea
Dotum
Korean
korea-s
Batang
Korean (serif)
- insert_image(rect, *, alpha=-1, filename=None, height=0, keep_proportion=True, mask=None, oc=0, overlay=True, pixmap=None, rotate=0, stream=None, width=0, xref=0)¶
PDF only: Put an image inside the given rectangle. The image may already exist in the PDF or be taken from a pixmap, a file, or a memory area.
- Parameters:
rect (rect_like) – where to put the image. Must be finite and not empty.
alpha (int) – deprecated and ignored.
filename (str) – name of an image file (all formats supported by MuPDF – see Supported Input Image Formats).
height (int)
keep_proportion (bool) – maintain the aspect ratio of the image.
mask (bytes,bytearray,io.BytesIO) – image in memory – to be used as image mask (alpha values) for the base image. When specified, the base image must be provided as a filename or a stream – and must not be an image that already has a mask.
oc (int) – (
xref) make image visibility dependent on thisOCGorOCMD. Ignored after the first of multiple insertions. The property is stored with the generated PDF image object and therefore controls the image’s visibility throughout the PDF.overlay – see Common Parameters.
pixmap (Pixmap) – a pixmap containing the image.
rotate (int) – rotate the image. Must be an integer multiple of 90 degrees. Positive values rotate anti-clockwise. If you need a rotation by an arbitrary angle, consider converting the image to a PDF (
Document.convert_to_pdf()) first and then usePage.show_pdf_page()instead.stream (bytes,bytearray,io.BytesIO) – image in memory (all formats supported by MuPDF – see Supported Input Image Formats).
width (int)
xref (int) – the
xrefof an image already present in the PDF. If given, parametersfilename, Pixmap,stream,alphaandmaskare ignored. The page will simply receive a reference to the existing image.
- Returns:
The
xrefof the embedded image. This can be used as thexrefargument for very significant performance boosts, if the image is inserted again.
This example puts the same image on every page of a document:
>>> doc = pymupdf.open(...) >>> rect = pymupdf.Rect(0, 0, 50, 50) # put thumbnail in upper left corner >>> img = open("some.jpg", "rb").read() # an image file >>> img_xref = 0 # first execution embeds the image >>> for page in doc: img_xref = page.insert_image(rect, stream=img, xref=img_xref, 2nd time reuses existing image ) >>> doc.save(...)
Note
The method detects multiple insertions of the same image (like in the above example) and will store its data only on the first execution. This is even true (although less performant), if using the default
xref=0.The method cannot detect if the same image had already been part of the file before opening it.
You can use this method to provide a background or foreground image for the page, like a copyright or a watermark. Please remember, that watermarks require a transparent image if put in foreground …
The image may be inserted uncompressed, e.g. if a Pixmap is used or if the image has an alpha channel. Therefore, consider using
deflate=Truewhen saving the file. In addition, there are ways to control the image size – even if transparency comes into play. Have a look at How to Add Images to a PDF Page.The image is stored in the PDF at its original quality level. This may be much better than what you need for your display. Consider decreasing the image size before insertion – e.g. by using the pixmap option and then shrinking it or scaling it down (see Pixmap chapter). The PIL method
Image.thumbnail()can also be used for that purpose. The file size savings can be very significant.Another efficient way to display the same image on multiple pages is another method:
show_pdf_page(). ConsultDocument.convert_to_pdf()for how to obtain intermediary PDFs usable for that method.
Show/hide history
Changed in v1.14.1: By default, the image keeps its aspect ratio.
Changed in v1.14.11: Added args
keep_proportion,rotate.Changed in v1.14.13:
The image is now always placed centered in the rectangle, i.e. the centers of image and rectangle are equal.
Added support for
streamasio.BytesIO.
Changed in v1.17.6: Insertion rectangle no longer needs to have a non-empty intersection with the page’s
Page.cropbox[5].Changed in v1.18.1: Added
maskarg.Changed in v1.18.3: Added
ocarg.Changed in v1.18.13:
Changed in v1.19.3: deprecate and ignore
alphaarg.
- replace_image(xref, filename=None, pixmap=None, stream=None)¶
Replace the image at xref with another one.
- Parameters:
Arguments
filename, Pixmap,streamhave the same meaning as inPage.insert_image(), especially exactly one of these must be provided.This is a global replacement: the new image will also be shown wherever the old one has been displayed throughout the file.
This method mainly exists for technical purposes. Typical uses include replacing large images by smaller versions, like a lower resolution, graylevel instead of colored, etc., or changing transparency.
Show/hide history
New in v1.21.0
- delete_image(xref)¶
Delete the image at xref. This is slightly misleading: actually the image is being replaced with a small transparent Pixmap using above
Page.replace_image(). The visible effect however is equivalent.- Parameters:
xref (int) – the
xrefof the image.
This is a global replacement: the image will disappear wherever the old one has been displayed throughout the file.
If you inspect / extract a page’s images by methods like
Page.get_images(),Page.get_image_info()orPage.get_text(), the replacing “dummy” image will be detected like so(45, 47, 1, 1, 8, 'DeviceGray', '', 'Im1', 'FlateDecode')and also seem to “cover” the same boundary box on the page.Show/hide history
New in v1.21.0
- get_text(option, *, clip=None, flags=None, textpage=None, sort=False, delimiters=None)¶
Retrieves the content of a page in a variety of formats. Depending on the
flagsvalue, this may include text, images and several other object types. The method is a wrapper for multiple TextPage methods by choosing the output optionoptas follows:“text” –
TextPage.extractTEXT(), default. Always includes text only.“blocks” –
TextPage.extractBLOCKS(). Includes text and may include image meta information.“words” –
TextPage.extractWORDS(). Always includes text only.“html” –
TextPage.extractHTML(). May include text and images.“xhtml” –
TextPage.extractXHTML(). May include text and images.“xml” –
TextPage.extractXML(). Always includes text only.“dict” –
TextPage.extractDICT(). May include text and images.“json” –
TextPage.extractJSON(). May include text and images.“rawdict” –
TextPage.extractRAWDICT(). May include text and images.“rawjson” –
TextPage.extractRAWJSON(). May include text and images.
- Parameters:
opt (str) – A string indicating the requested format, one of the above. A mixture of upper and lower case is supported. If misspelled, option “text” is silently assumed.
clip (rect-like) – restrict the extraction to this rectangle. If
None(default), the visible part of the page is taken. Any content (text, images) that is not fully contained inclipwill be completely omitted. To avoid clipping altogether useclip=pymupdf.INFINITE_RECT(). Only then the extraction will contain all items. This parameter has no effect on options “html”, “xhtml” and “xml”.flags (int) – indicator bits to control whether to include images or how text should be handled with respect to white spaces and
ligatures. See Font Properties for available indicators and Text Extraction Flags Defaults for default settings. (New in v1.16.2)textpage – use a previously created TextPage. This reduces execution time very significantly: by more than 50% and up to 95%, depending on the extraction option. If specified, the ‘flags’ and ‘clip’ arguments are ignored, because they are textpage-only properties. If omitted, a new, temporary textpage will be created.
sort (bool) – sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a “natural” reading order. Has no effect on (X)HTML and XML. For options “blocks”, “dict”, “json”, “rawdict”, “rawjson”, sorting happens by coordinates
(y1, x0)of the respective block bbox. For options “words” and “text”, the text lines are completely re-synthesized to follow the reading sequence and appearance in the document – which even establishes the original layout to some extent.delimiters (str) – use these characters as additional word separators with the “words” output option (ignored otherwise). By default, all white spaces (including non-breaking space
0xA0) indicate start and end of a word. Now you can specify more characters causing this. For instance, the default will return"john.doe@outlook.com"as one word. If you specifydelimiters="@."then the four words"john","doe","outlook","com"will be returned. Other possible uses include ignoring punctuation charactersdelimiters=string.punctuation. The “word” strings will not contain any delimiting character. (New in v1.23.5)
- Return type:
str, list, dict
- Returns:
The page’s content as a string, a list or a dictionary. Refer to the corresponding TextPage method for details.
Note
You can use this method as a document conversion tool from any supported document type to one of TEXT, HTML, XHTML or XML documents.
The inclusion of text via the clip parameter is decided on a by-character level: a character becomes part of the output, if its bbox is contained in
clip. This deviates from the algorithm used in redaction annotations: a character will be removed if its bbox intersects any redaction annotation.
Show/hide history
Changed in v1.19.0: added TextPage parameter
Changed in v1.19.1: added
sortparameterChanged in v1.19.6: added new constants for defining default flags per method.
Changed in v1.23.5: added
delimitersparameterChanged in v1.24.11: changed the effect of
sort_Truefor “text” and “words” to closely follow natural reading sequence.
- get_textbox(rect, textpage=None)¶
Retrieve the text contained in a rectangle.
- Parameters:
rect (rect-like) – rect-like.
textpage – a TextPage to use. If omitted, a new, temporary textpage will be created.
- Returns:
a string with interspersed linebreaks where necessary. It is based on dedicated code (changed in v1.19.0). A typical use is checking the result of
Page.search_for():>>> rl = page.search_for("currency:") >>> page.get_textbox(rl[0]) 'Currency:' >>>
Show/hide history
New in v1.17.7
Changed in v1.19.0: add TextPage parameter
- get_textpage(clip=None, flags=3)¶
Create a TextPage for the page.
- Parameters:
flags (int) – indicator bits controlling the content available for subsequent text extractions and searches – see the parameter of
Page.get_text().clip (rect-like) – restrict extracted text to this area. (New in v1.17.7)
- Returns:
Show/hide history
New in v1.16.5
Changed in v1.17.7: introduced
clipparameter.
- get_textpage_ocr(flags=3, language='eng', dpi=72, full=False, tessdata=None)¶
Optical Character Recognition (OCR) technology can be used to extract text data for pages where text is in raster image or vector graphic format. Use this method to OCR a page for subsequent text extraction.
This method returns a TextPage for the page that includes OCRed text. MuPDF will invoke Tesseract-OCR if this method is used.
- Parameters:
flags (int) – indicator bits controlling the content available for subsequent test extractions and searches – see the parameter of
Page.get_text().language (str) – the expected language(s). Use “+”-separated values if multiple languages are expected, “eng+spa” for English and Spanish.
dpi (int) – the desired resolution in dots per inch. Influences recognition quality (and execution time).
full (bool) – whether to OCR the full page, or only page areas that contain no legible text.
tessdata (str) – The name of Tesseract’s language support folder
tessdata. If omitted, the name is determined using functionget_tessdata().
Note
This method does not support a clip parameter – OCR (full or partial) will always happen for the complete page rectangle.
- Returns:
a TextPage. Execution may be significantly longer than
Page.get_textpage().
For
full=TrueOCR, all text will have the font “GlyphLessFont” from Tesseract. In case of partial OCR (full=False), legible normal text will keep its properties, and only recognized text will have the GlyphLessFont.Recognized / OCR text will follow (legible) normal text for partial OCR and will thus not be in reading order. Establishing reading order is – as always – your responsibility.
Note
Text extraction results, including any OCR, are stored in the returned TextPage. To access them, you must use the
textpageparameter in all subsequent text extraction and search methods.This Jupyter notebook walks through an example for using OCR textpages.
Show/hide history
New in v.1.19.0
Changed in v1.19.1: support full and partial OCRing a page.
changed in v1.27.2: For partial OCR, all page areas outside legible text are now OCRed, not just those within images. This means that OCR will now also be performed for vector graphics, and for text containing illegible characters.
- get_drawings(extended=False)¶
Return the vector graphics of the page. These are instructions which draw lines, rectangles, quadruples or curves, including properties like colors, transparency, line width and dashing, etc. Alternative terms are “line art” and “drawings”.
- Returns:
a list of dictionaries. Each dictionary item contains one or more single draw commands belonging together: they have the same properties (colors, dashing, etc.). This is called a “path” in PDF, so we adopted that name here, but the method works for all document types.
The path dictionary for fill, stroke and fill-stroke paths has been designed to be compatible with class Shape. There are the following keys:
Key
Value
closePath
Same as the parameter in Shape.
color
Stroke color (see Shape).
dashes
Dashed line specification (see Shape).
even_odd
Fill colors of area overlaps – same as the parameter in Shape.
fill
Fill color (see Shape).
items
List of draw commands: lines, rectangles, quads or curves.
lineCap
Number 3-tuple, use its max value on output with Shape.
lineJoin
Same as the parameter in Shape.
fill_opacity
fill color transparency (see Shape). (New in v1.18.17)
stroke_opacity
stroke color transparency (see Shape). (New in v1.18.17)
rect
Page area covered by this path. Information only.
layer
name of applicable Optional Content Group. (New in v1.22.0)
level
the hierarchy level if
extended=True. (New in v1.22.0)seqno
command number when building page appearance. (New in v1.19.0)
type
type of this path. (New in v1.18.17)
width
Stroke line width. (see Shape).
Key
"opacity"has been replaced by the new keys"fill_opacity"and"stroke_opacity". This is now compatible with the corresponding parameters ofShape.finish(). (Changed in v1.18.17)For paths other than groups or clips, key
"type"takes one of the following values:“f” – this is a fill-only path. Only key-values relevant for this operation have a meaning, not applicable ones are present with a value of
None:"color","lineCap","lineJoin","width","closePath","dashes"and should be ignored.“s” – this is a stroke-only path. Similar to previous, key
"fill"is present with valueNone.“fs” – this is a path performing combined fill and stroke operations.
Each item in
path["items"]is one of the following:("l", p1, p2)- a line from p1 to p2 (Point objects).("c", p1, p2, p3, p4)- cubic Bézier curve from p1 to p4 (p2 and p3 are the control points). All objects are of type Point.("re", rect, orientation)- a Rect. Multiple rectangles within the same path are now detected (changed in v1.18.17). Integerorientationis 1 resp. -1 indicating whether the enclosed area is rotated left (1 = anti-clockwise), or resp. right [7] (changed in v1.19.2).("qu", quad)- a Quad. 3 or 4 consecutive lines are detected to actually represent a Quad (changed in v1.19.2:). (New in v1.18.17)
Using class Shape, you should be able to recreate the original drawings on a separate (PDF) page with high fidelity under normal, not too sophisticated circumstances. Please see the following comments on restrictions. A coding draft can be found in How to Extract Drawings.
Specifying
extended=Truesignificantly alters the output. Most importantly, new dictionary types are present: “clip” and “group”. All paths will now be organized in a hierarchic structure which is encoded by the new integer key “level”, the hierarchy level. Each group or clip establishes a new hierarchy, which applies to all subsequent paths having a larger level value. (New in v1.22.0)Any path with a smaller level value than its predecessor will end the scope of (at least) the preceding hierarchy level. A “clip” path with the same level as the preceding clip will end the scope of that clip. Same is true for groups. This is best explained by an example:
+------+------+--------+------+--------+ | line | lvl0 | lvl1 | lvl2 | lvl3 | +------+------+--------+------+--------+ | 0 | clip | | | | | 1 | | fill | | | | 2 | | group | | | | 3 | | | clip | | | 4 | | | | stroke | | 5 | | | fill | | ends scope of clip in line 3 | 6 | | stroke | | | ends scope of group in line 2 | 7 | | clip | | | | 8 | fill | | | | ends scope of line 0 +------+------+--------+------+--------+
The clip in line 0 applies to line including line 7. Group in line 2 applies to lines 3 to 5, clip in line 3 only applies to line 4.
“stroke” in line 4 is under control of “group” in line 2 and “clip” in line 3 (which in turn is a subset of line 0 clip).
“clip” dictionary. Its values (most importantly “scissor”) remain valid / apply as long as following dictionaries have a larger “level” value.
Key
Value
closePath
Same as in “stroke” or “fill” dictionaries
even_odd
Same as in “stroke” or “fill” dictionaries
items
Same as in “stroke” or “fill” dictionaries
rect
Same as in “stroke” or “fill” dictionaries
layer
Same as in “stroke” or “fill” dictionaries
level
Same as in “stroke” or “fill” dictionaries
scissor
the clip rectangle
type
“clip”
“group” dictionary. Its values remain valid (apply) as long as following dictionaries have a larger “level” value. Any dictionary with an equal or lower level end this group.
Key
Value
rect
Same as in “stroke” or “fill” dictionaries
layer
Same as in “stroke” or “fill” dictionaries
level
Same as in “stroke” or “fill” dictionaries
isolated
(bool) Whether this group is isolated
knockout
(bool) Whether this is a “Knockout Group”
blendmode
Name of the BlendMode, default is “Normal”
opacity
Float value in range [0, 1].
type
“group”
Note
The method is based on the output of
Page.get_cdrawings()– which is much faster, but requires somewhat more attention processing its output.Show/hide history
New in v1.18.0
Changed in v1.18.17
Changed in v1.19.0: add “seqno” key, remove “clippings” key
Changed in v1.19.1: “color” / “fill” keys now always are either are RGB tuples or
None. This resolves issues caused by exotic colorspaces.Changed in v1.19.2: add an indicator for the “orientation” of the area covered by an “re” item.
Changed in v1.22.0: add new key
"layer"which contains the name of the Optional Content Group of the path (orNone).Changed in v1.22.0: add parameter
extendedto also return clipping and group paths.
- get_cdrawings(extended=False)¶
Extract the vector graphics on the page. Apart from following technical differences, functionally equivalent to
Page.get_drawings(), but much faster:Every path type only contains the relevant keys, e.g. a stroke path has no
"fill"color key. See comment in methodPage.get_drawings().Coordinates are given as
point_like,rect_likeandquad_liketuples – not as Point, Rect, Quad objects.
If performance is a concern, consider using this method: Compared to versions earlier than 1.18.17, you should see much shorter response times. We have seen pages that required 2 seconds then, now only need 200 ms with this method.
Show/hide history
New in v1.18.17
Changed in v1.19.0: removed “clippings” key, added “seqno” key.
Changed in v1.19.1: always generate RGB color tuples.
Changed in v1.22.0: added new key
"layer"which contains the name of the Optional Content Group of the path (orNone).Changed in v1.22.0: added parameter
extendedto also return clipping paths.
- get_fonts(full=False)¶
PDF only: Return a list of fonts referenced by the page. Wrapper for
Document.get_page_fonts().
- get_images(full=False)¶
PDF only: Return a list of images referenced by the page. Wrapper for
Document.get_page_images().
- get_image_info(hashes=False, xrefs=False)¶
Return a list of meta information dictionaries for all images displayed by the page. This works for all document types.
- Parameters:
hashes (bool) – Compute the MD5 hashcode for each encountered image, which allows identifying image duplicates. This adds the key
"digest"to the output, whose value is a 16 bytebytesobject. (New in v1.18.13)xrefs (bool) – PDF only. Try to find the
xreffor each image. Implieshashes=True. Adds the"xref"key to the dictionary. If not found, the value is 0, which means, the image is either “inline” or its xref is undetectable for some reason. Please note that this option has an extended response time, because the MD5 hashcode will be computed at least two times for each image with an xref. (New in v1.18.13)
- Return type:
list[dict]
- Returns:
A list of dictionaries. This includes information for exactly those images, that are shown on the page – including “inline images”. The dictionary layout is similar to that of image blocks in
page.get_text("dict").In contrast to images included in
Page.get_text(), image binary content is not loaded by this method, which drastically reduces memory usage. Another difference is that image detection is not restricted to the visible part of the page or anyclipparameter: methodPage.get_text()will only extract images fully contained in the providedclip.Key
Value
number
block number (
int)bbox
image bbox on page,
rect_likewidth
original image width (
int)height
original image height (
int)cs-name
colorspace name (
str)colorspace
colorspace.n (
int)xres
resolution in x-direction (
int) [10]yres
resolution in y-direction (
int) [10]bpc
bits per component (
int)size
storage occupied by image (
int)digest
MD5 hashcode (
bytes), ifhashesis truexref
image
xrefor 0, if xrefs is truetransform
matrix transforming image rect to bbox,
matrix_likehas-mask
whether the image is transparent and has a mask (
bool)Multiple occurrences of the same image are always reported. You can detect duplicates by comparing their
digestvalues.
Show/hide history
New in v1.18.11
Changed in v1.18.13: added image MD5 hashcode computation and
xrefsearch.
- get_xobjects()¶
PDF only: Return a list of Form XObjects referenced by the page. Wrapper for
Document.get_page_xobjects().
- get_image_rects(item, transform=False)¶
PDF only: Return boundary boxes and transformation matrices of an embedded image. This is an improved version of
Page.get_image_bbox()with the following differences:There is no restriction on how the image is invoked (by the page or one of its Form XObjects). The result is always complete and correct.
The result is a list of Rect or (Rect, Matrix) objects – depending on transform. Each list item represents one location of the image on the page. Multiple occurrences might not be detectable by
Page.get_image_bbox().The method invokes
Page.get_image_info()withxrefs=Trueand therefore has a noticeably longer response time thanPage.get_image_bbox().
- Parameters:
item (list,str,int) – an item of the list
Page.get_images(), or the reference name entry of such an item (item[7]), or the imagexref.transform (bool) – also return the matrix used to transform the image rectangle to the bbox on the page. If true, then tuples
(bbox, matrix)are returned.
- Return type:
list
- Returns:
Boundary boxes and respective transformation matrices for each image occurrence on the page. If the item is not on the page, an empty list
[]is returned.
Show/hide history
New in v1.18.13
- get_image_bbox(item, transform=False)¶
PDF only: Return boundary box and transformation matrix of an embedded image.
- Parameters:
item (list,str) – an item of the list
Page.get_images()with full=True specified, or the reference name entry of such an item, which is item[-3] (or item[7] respectively).transform (bool) – return the matrix used to transform the image rectangle to the bbox on the page (new in v1.18.11). Default is just the bbox. If true, then a tuple
(bbox, matrix)is returned.
- Return type:
- Returns:
the boundary box of the image – optionally also its transformation matrix.
Show/hide history
(Changed in v1.16.7): If the page in fact does not display this image, an infinite rectangle is returned now. In previous versions, an exception was raised. Formally invalid parameters still raise exceptions.
(Changed in v1.17.0): Only images referenced directly by the page are considered. This means that images occurring in embedded PDF pages are ignored and an exception is raised.
(Changed in v1.18.5): Removed the restriction introduced in v1.17.0: any item of the page’s image list may be specified.
(Changed in v1.18.11): Partially re-instated a restriction: only those images are considered, that are either directly referenced by the page or by a Form XObject directly referenced by the page.
(Changed in v1.18.11): Optionally also return the transformation matrix together with the bbox as the tuple
(bbox, transform).
Note
Be aware that
Page.get_images()may contain “dead” entries i.e. images, which the page does not display. This is no error, but intended by the PDF creator. No exception will be raised in this case, but an infinite rectangle is returned. You can avoid this from happening by executingPage.clean_contents()before this method.The image’s “transformation matrix” is defined as the matrix, for which the expression
bbox / transform == pymupdf.Rect(0, 0, 1, 1)is true, lookup details here: Image Transformation Matrix.
Show/hide history
Changed in v1.18.11: return image transformation matrix
- get_svg_image(matrix=pymupdf.Identity, text_as_path=True)¶
Create an SVG image from the page. Only full page images are currently supported.
- Parameters:
matrix (matrix_like) – a matrix, default is Identity.
text_as_path (bool) – – controls how text is represented.
Trueoutputs each character as a series of elementary draw commands, which leads to a more precise text display in browsers, but a very much larger output for text-oriented pages. Display quality forFalserelies on the presence of the referenced fonts on the current system. For missing fonts, the internet browser will fall back to some default – leading to unpleasant appearances. ChooseFalseif you want to parse the text of the SVG. (New in v1.17.5)
- Returns:
a UTF-8 encoded string that contains the image. Because SVG has XML syntax it can be saved in a text file, the standard extension is
.svg.Note
In case of a PDF, you can circumvent the “full page image only” restriction by modifying the page’s CropBox before using the method.
- get_pixmap(*, matrix=pymupdf.Identity, dpi=None, colorspace=pymupdf.csRGB, clip=None, alpha=False, annots=True)¶
Create a pixmap from the page. This is probably the most often used method to create a Pixmap.
All parameters are keyword-only.
- Parameters:
matrix (matrix_like) – default is Identity.
dpi (int) – desired resolution in x and y direction. If not
None, the"matrix"parameter is ignored. (New in v1.19.2)colorspace (str or Colorspace) – The desired colorspace, one of “GRAY”, “RGB” or “CMYK” (case insensitive). Or specify a Colorspace, ie. one of the predefined ones:
csGRAY,csRGBorcsCMYK.clip (irect_like) – restrict rendering to the intersection of this area with the page’s rectangle.
alpha (bool) –
whether to add an alpha channel. Always accept the default
Falseif you do not really need transparency. This will save a lot of memory (25% in case of RGB … and pixmaps are typically large!), and also processing time. Also note an important difference in how the image will be rendered: withTruethe pixmap’s samples area will be pre-cleared with 0x00. This results in transparent areas where the page is empty. WithFalsethe pixmap’s samples will be pre-cleared with 0xff. This results in white where the page has nothing to show.Show/hide history
- Changed in v1.14.17
The default alpha value is now
False.Generated with alpha=True

Generated with alpha=False

annots (bool) – (new in version 1.16.0) whether to also render annotations or to suppress them. You can create pixmaps for annotations separately.
- Return type:
- Returns:
Pixmap of the page. For fine-controlling the generated image, the by far most important parameter is matrix. E.g. you can increase or decrease the image resolution by using Matrix(xzoom, yzoom). If zoom > 1, you will get a higher resolution: zoom=2 will double the number of pixels in that direction and thus generate a 2 times larger image. Non-positive values will flip horizontally, resp. vertically. Similarly, matrices also let you rotate or shear, and you can combine effects via e.g. matrix multiplication. See the Matrix section to learn more.
Note
The pixmap will have “premultiplied” pixels if
alpha=True. To learn about some background, e.g. look for “Premultiplied alpha” here.The method will respect any page rotation and will not exceed the intersection of
clipandPage.cropbox. If you need the page’s mediabox (and if this is a different rectangle), you can use a snippet like the following to achieve this:In [1]: import pymupdf In [2]: doc=pymupdf.open("demo1.pdf") In [3]: page=doc[0] In [4]: rotation = page.rotation In [5]: cropbox = page.cropbox In [6]: page.set_cropbox(page.mediabox) In [7]: page.set_rotation(0) In [8]: pix = page.get_pixmap() In [9]: page.set_cropbox(cropbox) In [10]: if rotation != 0: ...: page.set_rotation(rotation) ...: In [11]:
Show/hide history
Changed in v1.19.2: added support of parameter dpi.
- annot_names()¶
PDF only: return a list of the names of annotations, widgets and links. Technically, these are the /NM values of every PDF object found in the page’s /Annots array.
- Return type:
list
Show/hide history
New in v1.16.10
- annot_xrefs()¶
PDF only: return a list of the
xrefnumbers of annotations, widgets and links – technically of all entries found in the page’s /Annots array.- Return type:
list
- Returns:
a list of items (xref, type) where type is the annotation type. Use the type to tell apart links, fields and annotations, see Annotation Types.
Show/hide history
New in v1.17.1
- load_annot(ident)¶
PDF only: return the annotation identified by ident. This may be its unique name (PDF
/NMkey), or itsxref.- Parameters:
ident (str,int) – the annotation name or xref.
- Return type:
- Returns:
the annotation or
None.
Note
Methods
Page.annot_names(),Page.annot_xrefs()provide lists of names or xrefs, respectively, from where an item may be picked and loaded via this method.Show/hide history
New in v1.17.1
- load_widget(xref)¶
PDF only: return the field identified by
xref.- Parameters:
xref (int) – the field’s xref.
- Return type:
- Returns:
the field or
None.
Note
This is similar to the analogous method
Page.load_annot()– except that here only the xref is supported as identifier.Show/hide history
New in v1.19.6
- load_links()¶
Return the first link on a page. Synonym of property
first_link.- Return type:
- Returns:
first link on the page (or
None).
- set_rotation(rotate)¶
PDF only: Set the rotation of the page.
- Parameters:
rotate (int) – An integer specifying the required rotation in degrees. Must be an integer multiple of 90. Values will be converted to one of 0, 90, 180, 270.
- recolor(components=1)¶
PDF only: Change the colorspace components of all objects on page.
- Parameters:
components (int) – The desired count of color components. Must be one of 1, 3 or 4, which results in color spaces DeviceGray, DeviceRGB or DeviceCMYK respectively. The method affects text, images and vector graphics. For instance, with the default value 1, a page will be converted to grayscale. If a page is already grayscale, the method will not cause visible changes – independent of the value of
components.
These changes are permanent and cannot be reverted.
- clip_to_rect(rect)¶
PDF only: Permanently remove page content outside the given rectangle. This is similar to
Page.set_cropbox(), but the page’s rectangle will not be changed, only the content outside the rectangle will be removed.- Parameters:
rect (rect_like) – The rectangle to clip to. Must be finite and its intersection with the page must not be empty.
The method works best for text: All text on the page will be removed (decided by single character) that has no intersection with the rectangle. For vector graphics, the method will remove all paths that have no intersection with the rectangle. For images, the method will remove all images that have no intersection with the rectangle. Vectors and images having an intersection with the rectangle, will be kept in their entirety.
The method roughly has the same effect as if four redactions had been applied that cover the rectangle’s outside.
New in v1.26.4.
- remove_rotation()¶
PDF only: Set page rotation to 0 while maintaining appearance and page content.
- Returns:
The inverted matrix used to achieve this change. If the page was not rotated (rotation 0), Identity is returned. The method automatically recomputes the rectangles of any annotations, links and widgets present on the page.
This method may come in handy when e.g. used with
Page.show_pdf_page().
- show_pdf_page(rect, docsrc, pno=0, keep_proportion=True, overlay=True, oc=0, rotate=0, clip=None)¶
PDF only: Display a page of another PDF. This is similar to
Page.insert_image()but the source page will appear like a copy of itself and will not be rasterized. This is a multi-purpose method. For example, you can use it to:create “n-up” versions of existing PDF files, combining several input pages into one output page (see example combine.py),
create “posterized” PDF files, i.e. every input page is split up in parts which each create a separate output page (see posterize.py),
include PDF-based vector images like company logos, watermarks, etc., see svg.py, which puts an SVG-based logo on each page.
- Parameters:
rect (rect_like) – where to place the image on current page. Must be finite and its intersection with the page must not be empty.
docsrc (Document) – source PDF document containing the page. Must be a different document object, but may be the same file.
pno (int) – page number (0-based, in
-∞ < pno < docsrc.page_count) to be shown.keep_proportion (bool) – whether to maintain the width-height-ratio (default). If false, all 4 corners are always positioned on the border of the target rectangle – whatever the rotation value. In general, this will deliver distorted and /or non-rectangular images.
overlay (bool) – put image in foreground (default) or background.
oc (int) – (
xref) make visibility dependent on thisOCG/OCMD(which must be defined in the target PDF) [9]. (New in v1.18.3)rotate (float) – show the source rectangle rotated by some angle. Any angle is supported (changed in v1.14.11). (New in v1.14.10)
clip (rect_like) – choose which part of the source page to show. Default is the full page, else must be finite and its intersection with the source page must not be empty.
Note
In contrast to method
Document.insert_pdf(), this method does not copy annotations, widgets or links, so these objects are not included in the target [6]. But all its other resources (text, images, fonts, etc.) will be imported into the current PDF. They will therefore appear in text extractions and inget_fonts()andget_images()lists – even if they are not contained in the visible area given by clip.Example: Show the same source page, rotated by 90 and by -90 degrees:
>>> doc = pymupdf.open() # new empty PDF >>> page=doc.new_page() # new page in A4 format >>> >>> # upper half page >>> r1 = pymupdf.Rect(0, 0, page.rect.width, page.rect.height/2) >>> >>> # lower half page >>> r2 = r1 + (0, page.rect.height/2, 0, page.rect.height/2) >>> >>> src = pymupdf.open("PyMuPDF.pdf") # show page 0 of this >>> >>> page.show_pdf_page(r1, src, 0, rotate=90) >>> page.show_pdf_page(r2, src, 0, rotate=-90) >>> doc.save("show.pdf")
Show/hide history
Changed in v1.14.11: Parameter reuse_xref has been deprecated. Position the source rectangle centered in target rectangle. Any rotation angle is now supported.
Changed in v1.18.3: New parameter
oc.
- search_for(needle, *, clip=None, quads=False, flags=TEXT_DEHYPHENATE | TEXT_PRESERVE_WHITESPACE | TEXT_PRESERVE_LIGATURES | TEXT_MEDIABOX_CLIP, textpage=None)¶
Search for needle on a page. Wrapper for
TextPage.search().- Parameters:
needle (str) – Text to search for. May contain spaces. Upper / lower case is ignored, but only works for ASCII characters: For example, “COMPÉTENCES” will not be found if needle is “compétences” – “compÉtences” however will. Similar is true for German umlauts and the like.
clip (rect_like) – only search within this area. (New in v1.18.2)
flags (int) – Control the data extracted by the underlying TextPage. By default, ligatures and white spaces are kept, and hyphenation [8] is detected.
textpage – use a previously created TextPage. This reduces execution time significantly. If specified, the ‘flags’ and ‘clip’ arguments are ignored. If omitted, a temporary textpage will be created. (New in v1.19.0)
- Return type:
list
- Returns:
A list of Rect or Quad objects, each of which – normally! – surrounds one occurrence of needle. However: if parts of needle occur on more than one line, then a separate item is generated for each these parts. So, if
needle = "search string", two rectangles may be generated.Show/hide history
Changes in v1.18.2:
There no longer is a limit on the list length (removal of the
hit_maxparameter).If a word is hyphenated at a line break, it will still be found. E.g. the needle “method” will be found even if hyphenated as “meth-od” at a line break, and two rectangles will be returned: one surrounding “meth” (without the hyphen) and another one surrounding “od”.
Note
The method supports multi-line text marker annotations: you can use the full returned list as one single parameter for creating the annotation.
Caution
There is a tricky aspect: the search logic regards contiguous multiple occurrences of needle as one: assuming needle is “abc”, and the page contains “abc” and “abcabc”, then only two rectangles will be returned, one for “abc”, and a second one for “abcabc”.
You can always use
Page.get_textbox()to check what text actually is being surrounded by each rectangle.
Note
A feature repeatedly asked for is supporting regular expressions when specifying the
"needle"string: There is no way to do this. If you need something in that direction, first extract text in the desired format and then subselect the result by matching with some regex pattern. Here is an example for matching words:>>> pattern = re.compile(r"...") # the regex pattern >>> words = page.get_text("words") # extract words on page >>> matches = [w for w in words if pattern.search(w[4])]
The
matcheslist will contain the words matching the given pattern. In the same way you can selectspan["text"]from the output ofpage.get_text("dict").Show/hide history
Changed in v1.18.2: added
clipparameter. Removehit_maxparameter. Add default “dehyphenate”.Changed in v1.19.0: added TextPage parameter.
- set_mediabox(r)¶
PDF only: Change the physical page dimension by setting
mediaboxin the page’s object definition.- Parameters:
r (rect-like) – the new
mediaboxvalue.
Note
This method also removes the page’s other (optional) rectangles (
cropbox, ArtBox, TrimBox and Bleedbox) to prevent inconsistent situations. This will cause those to assume their default values.Caution
For non-empty pages this may have undesired effects, because the location of all content depends on this value and will therefore change position or even disappear.
Show/hide history
New in v1.16.13
Changed in v1.19.4: remove all other rectangle definitions.
- set_cropbox(r)¶
PDF only: change the visible part of the page.
- Parameters:
r (rect_like) – the new visible area of the page. Note that this must be specified in unrotated coordinates, not empty, nor infinite and be completely contained in the
Page.mediabox.
After execution (if the page is not rotated),
Page.rectwill equal this rectangle, but be shifted to the top-left position (0, 0) if necessary. Example session:>>> page = doc.new_page() >>> page.rect pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> page.cropbox # cropbox and mediabox still equal pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # now set cropbox to a part of the page >>> page.set_cropbox(pymupdf.Rect(100, 100, 400, 400)) >>> # this will also change the "rect" property: >>> page.rect pymupdf.Rect(0.0, 0.0, 300.0, 300.0) >>> >>> # but mediabox remains unaffected >>> page.mediabox pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # revert CropBox change >>> # either set it to MediaBox >>> page.set_cropbox(page.mediabox) >>> # or 'refresh' MediaBox: will remove all other rectangles >>> page.set_mediabox(page.mediabox)
- set_artbox(r)¶
- set_bleedbox(r)¶
- set_trimbox(r)¶
PDF only: Set the resp. rectangle in the page object. For the meaning of these objects see Adobe PDF References, page 77. Parameter and restrictions are the same as for
Page.set_cropbox().Show/hide history
New in v1.19.4
- rotation¶
Contains the rotation of the page in degrees (always 0 for non-PDF types). This is a copy of the value in the PDF file. The PDF documentation says:
“The number of degrees by which the page should be rotated clockwise when displayed or printed. The value must be a multiple of 90. Default value: 0.”
In PyMuPDF, we make sure that this attribute is always one of 0, 90, 180 or 270.
- Type:
int
- cropbox_position¶
Contains the top-left point of the page’s
/CropBoxfor a PDF, otherwise Point(0, 0).- Type:
- cropbox¶
The page’s
/CropBoxfor a PDF. Always the unrotated page rectangle is returned. For a non-PDF this will always equal the page rectangle.Note
In PDF, the relationship between
/MediaBox,/CropBoxand page rectangle may sometimes be confusing, please do lookup the glossary forMediaBox.- Type:
- artbox¶
- bleedbox¶
- trimbox¶
The page’s
/ArtBox,/BleedBox,/TrimBox, respectively. If not provided, defaulting toPage.cropbox.- Type:
- mediabox_size¶
Contains the width and height of the page’s
Page.mediaboxfor a PDF, otherwise the bottom-right coordinates ofPage.rect.- Type:
- mediabox¶
The page’s
mediaboxfor a PDF, otherwisePage.rect.- Type:
Note
For most PDF documents and for all other document types,
page.rect == page.cropbox == page.mediaboxis true. However, for some PDFs the visible page is a true subset ofmediabox. Also, if the page is rotated, itsPage.rectmay not equalPage.cropbox. In these cases the above attributes help to correctly locate page elements.
- transformation_matrix¶
This matrix translates coordinates from the PDF space to the MuPDF space. For example, in PDF
/Rect [x0 y0 x1 y1]the pair (x0, y0) specifies the bottom-left point of the rectangle – in contrast to MuPDF’s system, where (x0, y0) specify top-left. Multiplying the PDF coordinates with this matrix will deliver the (Py-) MuPDF rectangle version. Obviously, the inverse matrix will again yield the PDF rectangle.- Type:
- rotation_matrix¶
- derotation_matrix¶
These matrices may be used for dealing with rotated PDF pages. When adding / inserting anything to a PDF page, the coordinates of the unrotated page are always used. These matrices help translating between the two states. Example: if a page is rotated by 90 degrees – what would then be the coordinates of the top-left Point(0, 0) of an A4 page?
>>> page.set_rotation(90) # rotate an ISO A4 page >>> page.rect Rect(0.0, 0.0, 842.0, 595.0) >>> p = pymupdf.Point(0, 0) # where did top-left point land? >>> p * page.rotation_matrix Point(842.0, 0.0) >>>
- Type:
- number¶
The page number.
- Type:
int
- rect¶
Contains the rectangle of the page. Same as result of
Page.bound().- Type:
Description of get_links() Entries¶
Each entry of the Page.get_links() list is a dictionary with the following keys:
kind: (required) an integer indicating the kind of link. This is one of LINK_NONE, LINK_GOTO, LINK_GOTOR, LINK_LAUNCH, or LINK_URI. For values and meaning of these names refer to Link Destination Kinds.
from: (required) a Rect describing the “hot spot” location on the page’s visible representation (where the cursor changes to a hand image, usually).
page: a 0-based integer indicating the destination page. Required for LINK_GOTO and LINK_GOTOR, else ignored.
to: either a pymupdf.Point, specifying the destination location on the provided page, default is pymupdf.Point(0, 0), or a symbolic (indirect) name. If an indirect name is specified, page = -1 is required and the name must be defined in the PDF in order for this to work. Required for LINK_GOTO and LINK_GOTOR, else ignored.
file: a string specifying the destination file. Required for LINK_GOTOR and LINK_LAUNCH, else ignored.
uri: a string specifying the destination internet resource. Required for LINK_URI, else ignored. You should make sure to start this string with an unambiguous substring, that classifies the subtype of the URL, like
"http://","https://","file://","ftp://","mailto:", etc. Otherwise your browser will try to interpret the text and come to unwanted / unexpected conclusions about the intended URL type.xref: an integer specifying the PDFxrefof the link object. Do not change this entry in any way. Required for link deletion and update, otherwise ignored. For non-PDF documents, this entry contains -1. It is also -1 for all entries in the get_links() list, if any of the links is not supported by MuPDF - see Notes on Supporting Links.
Notes on Supporting Links¶
MuPDF’s support for links has changed in v1.10a. These changes affect link types LINK_GOTO and LINK_GOTOR.
Reading (pertains to method get_links() and the first_link property chain)¶
If MuPDF detects a link to another file, it will supply either a LINK_GOTOR or a LINK_LAUNCH link kind. In case of LINK_GOTOR destination details may either be given as page number (eventually including position information), or as an indirect destination.
If an indirect destination is given, then this is indicated by page = -1, and link.dest.dest will contain this name. The dictionaries in the get_links() list will contain this information as the to value.
Internal links are always of kind LINK_GOTO. If an internal link specifies an indirect destination, it will always be resolved and the resulting direct destination will be returned. Names are never returned for internal links, and undefined destinations will cause the link to be ignored.
Writing¶
PyMuPDF writes (updates, inserts) links by constructing and writing the appropriate PDF object source. This makes it possible to specify indirect destinations for LINK_GOTOR and LINK_GOTO link kinds (pre PDF 1.2 file formats are not supported).
Warning
If a LINK_GOTO indirect destination specifies an undefined name, this link can later on not be found / read again with MuPDF / PyMuPDF. Other readers however will detect it, but flag it as erroneous.
Indirect LINK_GOTOR destinations can in general of course not be checked for validity and are therefore always accepted.
Example: How to insert a link pointing to another page in the same document
Determine the rectangle on the current page, where the link should be placed. This may be the bbox of an image or some text.
Determine the target page number (“pno”, 0-based) and a Point on it, where the link should be directed to.
Create a dictionary
d = {"kind": pymupdf.LINK_GOTO, "page": pno, "from": bbox, "to": point}.Execute
page.insert_link(d).
Homologous Methods of Document and Page¶
This is an overview of homologous methods on the Document and on the Page level.
Document Level |
Page Level |
|---|---|
Note
Most document methods (left column) exist for convenience reasons, and are just wrappers for: Document[pno].<page method>. So they load and discard the page on each execution.
However, the first two methods work differently. They only need a page’s object definition statement - the page itself will not be loaded. So e.g. Page.get_fonts() is a wrapper the other way round and defined as follows: page.get_fonts == page.parent.get_page_fonts(page.number).
When calling the Document equivalent methods then the page number is sent through as a parameter, e.g.:
Document.get_page_images(pno) or Document.get_page_text(pno)
Tip
The page number parameter, pno, is a 0-based integer -∞ < pno < page_count.