Text¶
모든 문서 텍스트 추출 방법¶
이 스크립트는 문서 파일 이름을 받아 모든 텍스트에서 텍스트 파일을 생성합니다.
문서는 지원되는 모든 타입 일 수 있습니다.
스크립트는 매개변수로 제공된 문서 파일 이름을 기대하는 명령줄 도구로 작동합니다. 스크립트 디렉토리에 “filename.txt”라는 하나의 텍스트 파일을 생성합니다. 페이지의 텍스트는 폼 피드 문자로 구분됩니다:
import sys, pathlib, pymupdf
fname = sys.argv[1] # get document filename
with pymupdf.open(fname) as doc: # open document
text = chr(12).join([page.get_text() for page in doc])
# write as a binary file to support non-ASCII characters
pathlib.Path(fname + ".txt").write_bytes(text.encode())
출력은 문서에 코딩된 대로 일반 텍스트입니다. 어떤 방식으로도 예쁘게 만들려는 시도는 없습니다. 특히 PDF의 경우, 이것은 일반적인 읽기 순서가 아닌 출력, 예상치 못한 줄바꿈 등을 의미할 수 있습니다.
이를 수정하는 많은 옵션이 있습니다 – 부록 2: 임베디드 파일에 대한 고려사항 장을 참조하세요. 그 중에는 다음이 있습니다:
HTML 형식으로 텍스트를 추출하고 HTML 문서로 저장하여 모든 브라우저에서 볼 수 있도록 합니다.
Page.get_text(“blocks”) 를 통해 텍스트 블록 목록으로 텍스트를 추출합니다. 이 목록의 각 항목은 텍스트에 대한 위치 정보를 포함하며, 이를 사용하여 편리한 읽기 순서를 설정할 수 있습니다.
Page.get_text(“words”) 를 통해 단일 단어 목록을 추출합니다. 항목은 위치 정보가 있는 단어입니다. 주어진 사각형에 포함된 텍스트를 확인하는 데 사용하세요 – 다음 섹션을 참조하세요.
예제 및 추가 설명은 다음 두 섹션을 참조하세요.
Markdown 형식으로 텍스트 추출 방법¶
이는 특히 RAG/LLM 환경에 유용합니다 - Outputting as Markdown 를 참조하세요.
페이지에서 키-값 쌍 추출 방법¶
페이지 레이아웃이 어느 정도 “예측 가능한” 경우, 정규 표현식을 사용하지 않고도 특정 키워드 집합에 대한 값을 빠르고 쉽게 찾는 간단한 방법이 있습니다. 이 예제 스크립트 를 참조하세요.
여기서 “예측 가능한” 이란 다음을 의미합니다:
각 키워드 뒤에는 그 값이 이어집니다 – 그 사이에 다른 텍스트는 없습니다.
값의 경계 상자 하단이 키워드의 경계 상자보다 위에 있지 않습니다.
다른 제한은 없습니다: 페이지 레이아웃이 고정되어 있을 수도 있고 아닐 수도 있으며, 텍스트가 하나의 문자열로 저장되었을 수도 있습니다. 키와 값은 서로 어떤 거리든 가질 수 있습니다.
예를 들어, 다음 다섯 개의 키-값 쌍이 올바르게 식별됩니다:
key1 value1
key2
value2
key3
value3 blah, blah, blah key4 value4 some other text key5 value5 ...
사각형 내부에서 텍스트 추출 방법¶
이제 (v1.18.0) 이를 달성하는 방법이 여러 가지 있습니다. 따라서 이 주제를 다루는 폴더 를 PyMuPDF-Utilities 저장소에 만들었습니다.
자연스러운 읽기 순서로 텍스트 추출 방법¶
PDF 텍스트 추출의 일반적인 문제 중 하나는 텍스트가 특정 읽기 순서로 나타나지 않을 수 있다는 것입니다.
이는 PDF 생성자(소프트웨어 또는 사람)의 책임입니다. 예를 들어, 페이지 헤더는 문서가 생성된 후 별도의 단계에서 삽입되었을 수 있습니다. 이 경우 헤더 텍스트는 페이지 텍스트 추출의 끝에 나타납니다(하지만 PDF 뷰어 소프트웨어에서는 올바르게 표시됩니다). 예를 들어, 다음 스니펫은 기존 PDF에 일부 헤더 및 푸터 줄을 추가합니다:
doc = pymupdf.open("some.pdf")
header = "Header" # text in header
for page in doc:
page.insert_text((50, 50), header) # insert header
page.insert_text( # insert footer 50 points above page bottom
(50, page.rect.height - 50),
f"Page {page.number + 1} of {doc.page_count}", # text in footer
)
이런 방식으로 수정된 페이지에서 추출된 텍스트 시퀀스는 다음과 같습니다:
원본 텍스트
헤더 줄
푸터 줄
PyMuPDF는 읽기 순서를 재구성하거나 원본에 가까운 레이아웃을 재생성하는 여러 가지 방법을 제공합니다:
Page.get_text()의sort매개변수를 사용하세요. 출력을 왼쪽 위에서 오른쪽 아래로 정렬합니다 (XHTML, HTML 및 XML 출력에는 무시됨).CLI에서
pymupdf모듈을 사용하세요:python -m pymupdf gettext ..., 이는 레이아웃을 보존하는 모드로 텍스트가 재배열된 텍스트 파일을 생성합니다. 출력을 제어하는 많은 옵션이 있습니다.
위에서 언급한 스크립트 를 수정하여 사용할 수도 있습니다.
문서에서 테이블 내용 추출 방법¶
문서에서 테이블을 볼 때, 일반적으로 Excel 같은 임베드된 객체나 다른 식별 가능한 객체를 보는 것이 아닙니다. 보통은 표 형식 데이터로 보이도록 포맷된 일반적인 표준 텍스트일 뿐입니다.
따라서 이러한 페이지 영역에서 표 형식 데이터를 추출하려면 테이블 영역(즉, 경계 상자)을 식별 하는 방법을 찾은 다음 (1) 테이블 및 열 경계를 그래픽으로 표시하고 (2) 이 정보를 기반으로 텍스트를 추출해야 합니다.
이는 선, 사각형 또는 기타 지원 벡터 그래픽의 존재 여부와 같은 세부 사항에 따라 매우 복잡한 작업이 될 수 있습니다.
Page.find_tables() 메서드는 높은 테이블 감지 정밀도로 모든 작업을 수행합니다. 큰 장점은 외부 라이브러리 의존성이 없고 인공 지능이나 머신 러닝 기술을 사용할 필요가 없다는 것입니다. 또한 데이터 분석을 위한 잘 알려진 Python 패키지 pandas 에 대한 통합 인터페이스를 제공합니다.
한 페이지에 여러 테이블이 있거나 여러 페이지에 걸친 테이블 조각을 결합하는 것과 같은 표준 상황을 다루는 예제 Jupyter 노트북 를 살펴보세요.
추출된 텍스트 표시 방법¶
페이지에서 임의의 텍스트를 검색하는 표준 검색 함수가 있습니다: Page.search_for(). 발견된 항목을 둘러싸는 Rect 객체 목록을 반환합니다. 이러한 사각형은 예를 들어 발견된 텍스트를 시각적으로 표시하는 주석을 자동으로 삽입하는 데 사용할 수 있습니다.
이 방법에는 장점과 단점이 있습니다. 장점은 다음과 같습니다:
검색 문자열은 공백을 포함할 수 있고 여러 줄에 걸칠 수 있습니다
대문자 또는 소문자 문자가 동일하게 처리됩니다
줄 끝의 단어 하이픈 연결이 감지되고 해결됩니다
반환값은 어느 축에도 평행하지 않은 텍스트를 정확히 찾기 위한 Quad 객체 목록일 수도 있습니다 – 페이지 회전이 0이 아닐 때는 Quad 출력 사용을 권장합니다.
하지만 다른 옵션도 있습니다:
import sys
import pymupdf
def mark_word(page, text):
"""Underline each word that contains 'text'.
"""
found = 0
wlist = page.get_text("words", delimiters=None) # make the word list
for w in wlist: # scan through all words on page
if text in w[4]: # w[4] is the word's string
found += 1 # count
r = pymupdf.Rect(w[:4]) # make rect from word bbox
page.add_underline_annot(r) # underline
return found
fname = sys.argv[1] # filename
text = sys.argv[2] # search string
doc = pymupdf.open(fname)
print(f"underlining words containing '{word}' in document '{doc.name}'")
new_doc = False # indicator if anything found at all
for page in doc: # scan through the pages
found = mark_word(page, text) # mark the page's words
if found: # if anything found ...
new_doc = True
print(f"found '{text}' {found} times on page {page.number + 1}")
if new_doc:
doc.save("marked-" + doc.name)
이 스크립트는 CLI 매개변수를 통해 전달된 문자열을 찾기 위해 Page.get_text("words") 를 사용합니다. 이 방법은 페이지의 텍스트를 공백을 구분자로 사용하여 “단어”로 분리합니다. 추가 설명:
발견되면, 검색 문자열뿐만 아니라 문자열을 포함하는 전체 단어 가 표시됩니다(밑줄).
검색 문자열에는 단어 구분자를 포함할 수 없습니다. 기본적으로 단어 구분자는 공백과 줄바꿈 없는 공백
chr(0xA0)입니다.page.get_text("words", delimiters="./,")와 같이 추가 구분 문자를 사용하는 경우, 이러한 문자 중 어느 것도 검색 문자열에 포함되어서는 안 됩니다.여기서 보여주듯이, 대문자/소문자가 구분됩니다. 하지만 mark_word 함수에서 문자열 메서드 lower() (또는 정규 표현식)를 사용하여 이를 변경할 수 있습니다.
상한이 없습니다: 모든 항목이 감지됩니다.
단어를 표시하는 데 어떤 것 이든 사용할 수 있습니다: ‘Underline’, ‘Highlight’, ‘StrikeThrough’ 또는 ‘Square’ 주석 등.
이 매뉴얼 페이지의 예제 스니펫입니다. “MuPDF” 가 검색 문자열로 사용되었습니다. “MuPDF”를 포함하는 모든 문자열이 완전히 밑줄 처리되었습니다(검색 문자열뿐만 아니라).
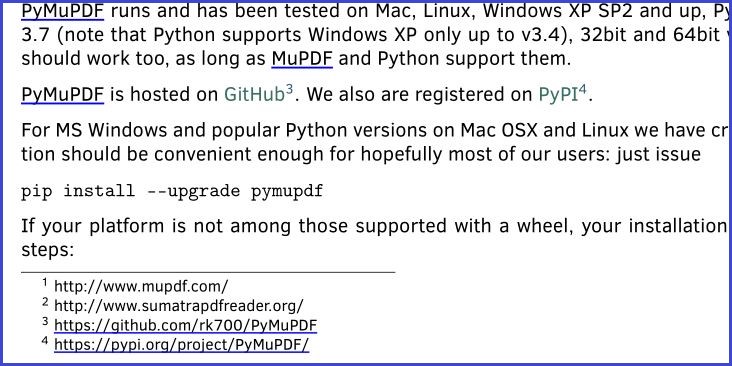
검색된 텍스트 표시 방법¶
이 스크립트는 텍스트를 검색하고 표시합니다:
# -*- coding: utf-8 -*-
import pymupdf
# the document to annotate
doc = pymupdf.open("tilted-text.pdf")
# the text to be marked
needle = "¡La práctica hace el campeón!"
# work with first page only
page = doc[0]
# get list of text locations
# we use "quads", not rectangles because text may be tilted!
rl = page.search_for(needle, quads=True)
# mark all found quads with one annotation
page.add_squiggly_annot(rl)
# save to a new PDF
doc.save("a-squiggly.pdf")
결과는 다음과 같습니다:

수평이 아닌 텍스트 표시 방법¶
이전 섹션에서는 텍스트 검색 으로 감지된 수평이 아닌 텍스트를 표시하는 예제를 이미 보여주었습니다.
하지만 Page.get_text() 의 “dict” / “rawdict” 옵션을 사용한 텍스트 추출 은 x축에 대해 0이 아닌 각도를 가진 텍스트도 반환할 수 있습니다. 이는 줄 딕셔너리의 "dir" 키 값으로 표시됩니다: 해당 각도의 튜플 (cosine, sine) 입니다. line["dir"] != (1, 0) 이면, 모든 스팬의 텍스트가 (동일한) 각도 != 0으로 회전됩니다.
하지만 이 메서드가 반환하는 “bboxes”는 사각형일 뿐입니다 – 쿼드가 아닙니다. 따라서 스팬 텍스트를 올바르게 표시하려면, 줄 및 스팬 딕셔너리에 포함된 데이터에서 쿼드를 복구해야 합니다. 다음 유틸리티 함수를 사용하세요 (v1.18.9에서 새로 추가됨):
span_quad = pymupdf.recover_quad(line["dir"], span)
annot = page.add_highlight_annot(span_quad) # this will mark the complete span text
전체 줄 또는 스팬의 하위 집합을 한 번에 표시하려면 다음 스니펫을 사용하세요 (v1.18.10 이상에서 작동):
line_quad = pymupdf.recover_line_quad(line, spans=line["spans"][1:-1])
page.add_highlight_annot(line_quad)

위의 spans 인수는 line["spans"] 의 임의의 하위 목록을 지정할 수 있습니다. 위 예제에서는 두 번째부터 마지막에서 두 번째까지의 스팬이 표시됩니다. 생략하면 전체 줄이 사용됩니다.
폰트 특성 분석 방법¶
PDF의 텍스트 특성을 분석하려면 이 기본 스크립트를 시작점으로 사용하세요:
import sys
import pymupdf
def flags_decomposer(flags):
"""Make font flags human readable."""
l = []
if flags & 2 ** 0:
l.append("superscript")
if flags & 2 ** 1:
l.append("italic")
if flags & 2 ** 2:
l.append("serifed")
else:
l.append("sans")
if flags & 2 ** 3:
l.append("monospaced")
else:
l.append("proportional")
if flags & 2 ** 4:
l.append("bold")
return ", ".join(l)
doc = pymupdf.open(sys.argv[1])
page = doc[0]
# read page text as a dictionary, suppressing extra spaces in CJK fonts
blocks = page.get_text("dict", flags=11)["blocks"]
for b in blocks: # iterate through the text blocks
for l in b["lines"]: # iterate through the text lines
for s in l["spans"]: # iterate through the text spans
print("")
s_font = s['font']
s_flags = flags_decomposer(s['flags'])
s_size = s['size']
s_color = s['color']
print(f"Text: '{s['text']}'") # simple print of text
print(f"Font: '{s_font}' ({s_flags}), size {s_size}, color #{s_color:06x}")
PDF 페이지와 스크립트 출력은 다음과 같습니다:

텍스트 삽입 방법¶
PyMuPDF는 다음 기능을 사용하여 새 PDF 페이지나 기존 PDF 페이지에 텍스트를 삽입하는 방법을 제공합니다:
파일로 사용 가능한 폰트를 포함하여 내장 폰트와 폰트를 선택
굵게, 기울임, 폰트 크기, 폰트 색상 등의 텍스트 특성 선택
여러 방법으로 텍스트 위치 지정:
특정 지점에서 시작하는 간단한 줄 지향 출력으로,
또는 사각형으로 제공된 상자에 텍스트를 맞추는 경우, 이 경우 텍스트 정렬 선택도 사용 가능,
텍스트를 전경에 배치할지 선택(기존 콘텐츠 위에 오버레이),
모든 텍스트를 임의로 “변형”할 수 있습니다. 즉, Matrix 를 통해 모양을 변경하여 확대/축소, 기울이기 또는 미러링과 같은 효과를 얻을 수 있습니다,
변형과 독립적으로, 추가로 텍스트를 90도의 정수 배로 회전할 수 있습니다.
위의 모든 것은 세 가지 기본 Page, 각각 Shape 메서드로 제공됩니다:
Page.insert_font()– 나중에 참조할 수 있도록 페이지에 폰트를 설치합니다. 결과는Document.get_page_fonts()의 출력에 반영됩니다. 폰트는 다음 중 하나일 수 있습니다:파일로 제공되거나,
Font 를 통해 (그런 다음
Font.buffer사용) 또는이 PDF 또는 다른 PDF의 어딘가에 이미 있거나,
내장 폰트일 수 있습니다.
Page.insert_text()– 텍스트 줄을 작성합니다. 내부적으로는Shape.insert_text()를 사용합니다.Page.insert_textbox()– 주어진 사각형에 텍스트를 맞춥니다. 여기서 텍스트 정렬 기능(왼쪽, 오른쪽, 가운데, 양쪽 정렬)을 선택할 수 있으며 텍스트가 실제로 맞는지 제어할 수 있습니다. 내부적으로는Shape.insert_textbox()를 사용합니다.
참고
두 텍스트 삽입 방법 모두 필요에 따라 폰트를 자동으로 설치합니다.
텍스트 줄 작성 방법¶
페이지에 텍스트 줄 출력:
import pymupdf
doc = pymupdf.open(...) # new or existing PDF
page = doc.new_page() # new or existing page via doc[n]
p = pymupdf.Point(50, 72) # start point of 1st line
text = "Some text,\nspread across\nseveral lines."
# the same result is achievable by
# text = ["Some text", "spread across", "several lines."]
rc = page.insert_text(p, # bottom-left of 1st char
text, # the text (honors '\n')
fontname = "helv", # the default font
fontsize = 11, # the default font size
rotate = 0, # also available: 90, 180, 270
)
print(f"{rc} lines printed on page {page.number}.")
doc.save("text.pdf")
이 방법을 사용하면 줄 수 만 페이지 높이를 초과하지 않도록 제어됩니다. 초과 줄은 작성되지 않으며 실제 줄 수가 반환됩니다. 계산은 fontsize 와 하단 여백으로 36포인트(0.5인치)에서 계산된 줄 높이를 사용합니다.
줄 너비는 무시됩니다. 줄의 초과 부분은 단순히 보이지 않습니다.
하지만 내장 폰트의 경우 사전에 줄 너비를 계산하는 방법이 있습니다 - get_text_length() 를 참조하세요.
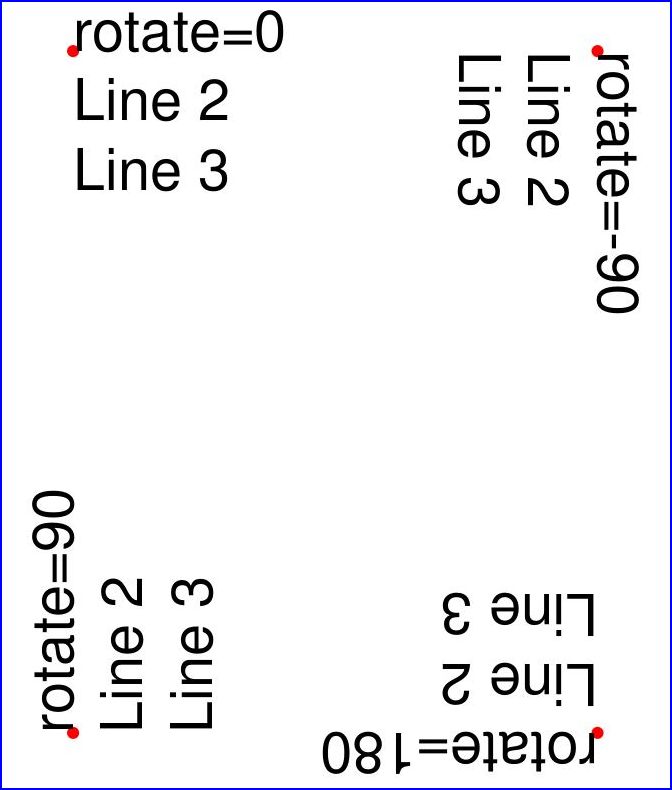
다른 예제입니다. 네 가지 다른 회전 옵션을 사용하여 4개의 텍스트 문자열을 삽입하고, 원하는 결과를 얻기 위해 텍스트 삽입 지점을 어떻게 선택해야 하는지 설명합니다:
import pymupdf
doc = pymupdf.open()
page = doc.new_page()
# the text strings, each having 3 lines
text1 = "rotate=0\nLine 2\nLine 3"
text2 = "rotate=90\nLine 2\nLine 3"
text3 = "rotate=-90\nLine 2\nLine 3"
text4 = "rotate=180\nLine 2\nLine 3"
red = (1, 0, 0) # the color for the red dots
# the insertion points, each with a 25 pix distance from the corners
p1 = pymupdf.Point(25, 25)
p2 = pymupdf.Point(page.rect.width - 25, 25)
p3 = pymupdf.Point(25, page.rect.height - 25)
p4 = pymupdf.Point(page.rect.width - 25, page.rect.height - 25)
# create a Shape to draw on
shape = page.new_shape()
# draw the insertion points as red, filled dots
shape.draw_circle(p1,1)
shape.draw_circle(p2,1)
shape.draw_circle(p3,1)
shape.draw_circle(p4,1)
shape.finish(width=0.3, color=red, fill=red)
# insert the text strings
shape.insert_text(p1, text1)
shape.insert_text(p3, text2, rotate=90)
shape.insert_text(p2, text3, rotate=-90)
shape.insert_text(p4, text4, rotate=180)
# store our work to the page
shape.commit()
doc.save(...)
결과는 다음과 같습니다:
텍스트 상자 채우기 방법¶
이 스크립트는 텍스트로 4개의 다른 사각형을 채우며, 매번 다른 회전 값을 선택합니다:
import pymupdf
doc = pymupdf.open() # new or existing PDF
page = doc.new_page() # new page, or choose doc[n]
# write in this overall area
rect = pymupdf.Rect(100, 100, 300, 150)
# partition the area in 4 equal sub-rectangles
CELLS = pymupdf.make_table(rect, cols=4, rows=1)
t1 = "text with rotate = 0." # these texts we will written
t2 = "text with rotate = 90."
t3 = "text with rotate = 180."
t4 = "text with rotate = 270."
text = [t1, t2, t3, t4]
red = pymupdf.pdfcolor["red"] # some colors
gold = pymupdf.pdfcolor["gold"]
blue = pymupdf.pdfcolor["blue"]
"""
We use a Shape object (something like a canvas) to output the text and
the rectangles surrounding it for demonstration.
"""
shape = page.new_shape() # create Shape
for i in range(len(CELLS[0])):
shape.draw_rect(CELLS[0][i]) # draw rectangle
shape.insert_textbox(
CELLS[0][i], text[i], fontname="hebo", color=blue, rotate=90 * i
)
shape.finish(width=0.3, color=red, fill=gold)
shape.commit() # write all stuff to the page
doc.ez_save(__file__.replace(".py", ".pdf"))
위에서는 일부 기본값이 사용되었습니다: 폰트 크기 11 및 텍스트 정렬 “left”. 결과는 다음과 같습니다:

HTML 텍스트로 상자 채우기 방법¶
Page.insert_htmlbox() 메서드는 사각형에 텍스트를 삽입하는 훨씬 더 강력한 방법을 제공합니다.
간단한 일반 텍스트 대신, 이 메서드는 HTML 소스를 받아들입니다. HTML 태그뿐만 아니라 폰트, 폰트 굵기(굵게), 스타일(기울임), 색상 등을 제어하는 스타일 지시문도 포함할 수 있습니다.
여러 폰트와 언어를 혼합하고, HTML 테이블을 출력하며, 이미지와 URI 링크를 삽입할 수도 있습니다.
더 많은 스타일링 유연성을 위해 추가 CSS 소스를 제공할 수도 있습니다.
이 메서드는 Story 클래스를 기반으로 합니다. 따라서 Devanagari, Nepali, Tamil 등과 같은 복잡한 문자 체계가 지원되며 HarfBuzz 라이브러리를 사용하여 올바르게 작성됩니다 - 이는 소위 “텍스트 셰이핑” 기능을 제공합니다.
문자를 출력하는 데 필요한 모든 폰트는 Google NOTO 폰트 라이브러리에서 자동으로 가져옵니다 - 폴백으로 (선택적으로 제공된 – 사용자 폰트에 일부 글리프가 없는 경우).
여기서 제공되는 기능을 간단히 살펴보기 위해 다음 HTML이 풍부한 텍스트를 출력합니다:
import pymupdf
rect = pymupdf.Rect(100, 100, 400, 300)
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: #f00;">reprehenderit</span>
in <span style="color: #0f0;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
doc = pymupdf.Document()
page = doc.new_page()
page.insert_htmlbox(rect, text, css="* {font-family: sans-serif;font-size:14px;}")
doc.ez_save(__file__.replace(".py", ".pdf"))
“css” 매개변수가 기본 “sans-serif” 폰트와 폰트 크기 14를 전역적으로 선택하는 데 어떻게 사용되는지 주목하세요.
결과는 다음과 같습니다:

HTML 테이블 및 이미지 출력 방법¶
이 메서드로 테이블을 출력하는 또 다른 예제입니다. 이번에는 모든 스타일링을 HTML 소스 자체에 포함합니다. 이미지를 포함하는 방법(테이블 셀 내부에서도)도 주목하세요:
import pymupdf
import os
filedir = os.path.dirname(__file__)
text = """
<style>
body {
font-family: sans-serif;
}
td,
th {
border: 1px solid blue;
border-right: none;
border-bottom: none;
padding: 5px;
text-align: center;
}
table {
border-right: 1px solid blue;
border-bottom: 1px solid blue;
border-spacing: 0;
}
</style>
<body>
<p><b>Some Colors</b></p>
<table>
<tr>
<th>Lime</th>
<th>Lemon</th>
<th>Image</th>
<th>Mauve</th>
</tr>
<tr>
<td>Green</td>
<td>Yellow</td>
<td><img src="img-cake.png" width=50></td>
<td>Between<br>Gray and Purple</td>
</tr>
</table>
</body>
"""
doc = pymupdf.Document()
page = doc.new_page()
rect = page.rect + (36, 36, -36, -36)
# we must specify an Archive because of the image
page.insert_htmlbox(rect, text, archive=pymupdf.Archive("."))
doc.ez_save(__file__.replace(".py", ".pdf"))
결과는 다음과 같습니다:

세계 언어 출력 방법¶
세 번째 예제는 자동 다국어 지원을 보여줍니다. Devanagari 및 오른쪽에서 왼쪽으로 쓰는 언어와 같은 복잡한 문자 체계에 대한 자동 텍스트 셰이핑 을 포함합니다:
import pymupdf
greetings = (
"Hello, World!", # english
"Hallo, Welt!", # german
"سلام دنیا!", # persian
"வணக்கம், உலகம்!", # tamil
"สวัสดีชาวโลก!", # thai
"Привіт Світ!", # ucranian
"שלום עולם!", # hebrew
"ওহে বিশ্ব!", # bengali
"你好世界!", # chinese
"こんにちは世界!", # japanese
"안녕하세요, 월드!", # korean
"नमस्कार, विश्व !", # sanskrit
"हैलो वर्ल्ड!", # hindi
)
doc = pymupdf.open()
page = doc.new_page()
rect = (50, 50, 200, 500)
# join greetings into one text string
text = " ... ".join([t for t in greetings])
# the output of the above is simple:
page.insert_htmlbox(rect, text)
doc.save(__file__.replace(".py", ".pdf"))
그리고 이것이 출력입니다:

자신의 폰트 지정 방법¶
@font-face 문을 사용하여 CSS 구문으로 폰트 파일을 정의하세요. 지원하려는 폰트 굵기와 폰트 스타일(예: 굵게 또는 기울임)의 모든 조합에 대해 별도의 @font-face 가 필요합니다. 다음 예제는 유명한 MS Comic Sans 폰트를 일반, 굵게, 기울임, 굵은 기울임의 네 가지 변형으로 사용합니다.
이 네 개의 폰트 파일이 시스템 폴더 C:/Windows/Fonts 에 있으므로, 메서드는 해당 폴더를 가리키는 Archive (아카이브) 정의가 필요합니다:
"""
How to use your own fonts with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
We need an Archive object to show where font files are located.
We intend to use the font family "MS Comic Sans".
"""
arch = pymupdf.Archive("C:/Windows/Fonts")
# These statements define which font file to use for regular, bold,
# italic and bold-italic text.
# We assign an arbitrary common font-family for all 4 font files.
# The Story algorithm will select the right file as required.
# We request to use "comic" throughout the text.
css = """
@font-face {font-family: comic; src: url(comic.ttf);}
@font-face {font-family: comic; src: url(comicbd.ttf);font-weight: bold;}
@font-face {font-family: comic; src: url(comicz.ttf);font-weight: bold;font-style: italic;}
@font-face {font-family: comic; src: url(comici.ttf);font-style: italic;}
* {font-family: comic;}
"""
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150) # make small page
page.insert_htmlbox(page.rect, text, css=css, archive=arch)
doc.subset_fonts(verbose=True) # build subset fonts to reduce file size
doc.ez_save(__file__.replace(".py", ".pdf"))

텍스트 정렬 요청 방법¶
이 예제는 여러 요구사항을 결합합니다:
텍스트를 90도 반시계 방향으로 회전합니다.
pymupdf-fonts 패키지의 폰트를 사용합니다. 이 경우 해당 CSS 정의가 훨씬 더 쉬운 것을 볼 수 있습니다.
“justify” 옵션으로 텍스트를 정렬합니다.
"""
How to use a pymupdf font with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
This is similar to font file support. However, we can use a convenience
function for creating required CSS definitions.
We still need an Archive for finding the font binaries.
"""
arch = pymupdf.Archive()
# We request to use "myfont" throughout the text.
css = pymupdf.css_for_pymupdf_font("ubuntu", archive=arch, name="myfont")
css += "* {font-family: myfont;text-align: justify;}"
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150)
page.insert_htmlbox(page.rect, text, css=css, archive=arch, rotate=90)
doc.subset_fonts(verbose=True)
doc.ez_save(__file__.replace(".py", ".pdf"))

색상이 있는 텍스트 추출 방법¶
텍스트 블록을 반복하고 이 정보에 필요한 텍스트 스팬을 찾으세요.
for page in doc:
text_blocks = page.get_text("dict", flags=pymupdf.TEXTFLAGS_TEXT)["blocks"]
for block in text_blocks:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
color = pymupdf.sRGB_to_rgb(span["color"])
print(f"Text: {text}, Color: {color}")