함수¶
다음은 상당히 낮은 수준의 기술 세부 사항에 대한 다양한 함수 및 속성입니다.
일부 함수는 PDF 구조에 대한 세부 액세스를 제공합니다. 다른 함수들은 더 많은 정보를 제공하는 다른 함수들의 간소화된 고성능 버전입니다.
또 다른 함수들은 편리한 범용 유틸리티입니다.
함수 |
간단한 설명 |
|---|---|
|
PDF 전용: 외관 객체의 bbox |
|
PDF 전용: 외관 객체의 행렬 |
콘텐츠 래핑이 있는지 확인 |
|
Adobe Glyph List 에 정의된 글리프 이름 목록 |
|
Adobe Glyph List 에 정의된 유니코드 목록 |
|
PDF 전용: 주석의 |
|
|
PDF 전용: 외관 객체의 bbox 설정 |
|
PDF 전용: 외관 객체의 행렬 설정 |
get_text 메서드에 대한 헤더 문자열 반환 |
|
get_text 메서드에 대한 트레일러 문자열 반환 |
|
PDF 전용: XML 메타데이터 제거 |
|
PDF 전용: 글꼴의 글리프 너비 목록 반환 |
|
PDF 전용: 새로운 |
|
PDF 전용: |
|
PDF 전용: XML 메타데이터 |
|
PDF 전용: |
|
(표준) 빈/유효하지 않은 사각형 반환 |
|
(표준) 빈/유효하지 않은 쿼드 반환 |
|
(표준) 빈/유효하지 않은 사각형 반환 |
|
PDF 형식의 현재 타임스탬프 반환 |
|
PDF 호환 문자열 반환 |
|
주어진 글꼴 및 |
|
글리프 이름에서 유니코드 반환 |
|
기본 이미지 속성의 딕셔너리 반환 |
|
(유일하게 존재하는) 무한 사각형 반환 |
|
(유일하게 존재하는) 무한 쿼드 반환 |
|
(유일하게 존재하는) 무한 사각형 반환 |
|
사각형을 하위 사각형으로 분할 |
|
PDF 전용: 페이지의 |
|
텍스트, 그리기 또는 이미지 객체를 둘러싸는 사각형 목록 |
|
PDF 전용: 콘텐츠 |
|
페이지의 디스플레이 리스트 생성 |
|
텍스트 블록을 Python 리스트로 추출 |
|
텍스트 단어를 Python 리스트로 추출 |
|
저수준 텍스트 정보 |
|
PDF 전용: 완전하고 연결된 /Contents 소스 가져오기 |
|
디바이스를 통해 페이지 실행 |
|
스택 명령으로 콘텐츠 래핑 |
|
pymupdf_fonts 패키지의 글꼴에 대한 CSS 소스 생성 |
|
알려진 용지 형식에 대한 사각형 반환 |
|
알려진 용지 형식에 대한 너비, 높이 반환 |
|
사전 정의된 용지 형식의 딕셔너리 |
|
선을 x축에 매핑하는 행렬 |
|
문자(“rawdict”)의 쿼드 계산 |
|
라인 스팬의 하위 집합의 쿼드 계산 |
|
스팬(“dict”, “rawdict”)의 쿼드 계산 |
|
스팬 문자의 하위 집합의 쿼드 계산 |
|
PyMuPDF 메시지의 대상 설정. |
|
sRGB 정수에서 PDF RGB 색상 튜플 반환 |
|
sRGB 정수에서 (R, G, B) 색상 튜플 반환 |
|
유니코드에서 글리프 이름 반환 |
|
Tesseract-OCR 설치의 언어 지원 위치 찾기 |
|
색상 이름의 딕셔너리 반환. |
|
색상 이름의 리스트 반환. |
|
사용 가능한 보조 글꼴의 딕셔너리 |
|
PyMuPDF 메시지의 대상. |
|
PDF 형식의 약 500개의 RGB 색상 딕셔너리. |
- paper_size(s)¶
알려진 용지 형식 코드의 너비와 높이를 반환하는 편의 함수. 이러한 값은 표준 해상도 72 픽셀 = 1 인치에 대한 픽셀 단위로 제공됩니다.
현재 정의된 형식에는 ‘A0’ 부터 ‘A10’, ‘B0’ 부터 ‘B10’, ‘C0’ 부터 ‘C10’, ‘Card-4x6’, ‘Card-5x7’, ‘Commercial’, ‘Executive’, ‘Invoice’, ‘Ledger’, ‘Legal’, ‘Legal-13’, ‘Letter’, ‘Monarch’ 및 ‘Tabloid-Extra’ 가 포함되며, 각각 세로 또는 가로 형식으로 제공됩니다.
형식 이름은 문자열로 제공해야 하며(대소문자 구분 안 함), 선택적으로 “-L”(가로) 또는 “-P”(세로) 접미사를 붙일 수 있습니다. 접미사가 없으면 기본값은 세로입니다.
- 매개변수:
s (str) – 위의 형식 이름 중 하나를 대문자 또는 소문자로 지정합니다. 예: “A4” 또는 “letter-l”.
- 반환 형식:
tuple
- 반환:
용지 형식의 (너비, 높이). 알 수 없는 형식의 경우 (-1, -1) 이 반환됩니다. 예: pymupdf.paper_size(“A4”) 는 (595, 842) 를 반환하고 pymupdf.paper_size(“letter-l”) 는 (792, 612) 를 반환합니다.
- paper_rect(s)¶
알려진 용지 형식에 대한 Rect 를 반환하는 편의 함수.
- 매개변수:
s (str) –
paper_size()에서 지원하는 모든 형식 이름.- 반환 형식:
- 반환:
width, height=pymupdf.paper_size(s) 를 사용한 pymupdf.Rect(0, 0, width, height).
>>> import pymupdf >>> pymupdf.paper_rect("letter-l") pymupdf.Rect(0.0, 0.0, 792.0, 612.0) >>>
- set_messages(*, text=None, fd=None, stream=None, path=None, path_append=None, pylogging=None, pylogging_logger=None, pylogging_level=None, pylogging_name=None)¶
PyMuPDF 메시지의 대상을 파일 디스크립터, 파일, 기존 스트림 또는 Python의 로깅 시스템 로 설정합니다.
일반적으로 하나의 인수만 설정하거나 하나 이상의
pylogging*인수를 설정합니다.
- 매개변수:
text (str) – 대상의 텍스트 사양. 자세한 내용은 환경 변수
PYMUPDF_MESSAGE의 설명을 참조하세요.fd (int) – 파일 디스크립터에 쓰기.
stream – 기존 스트림에 쓰기.
.write(text)및.flush()메서드가 있어야 합니다.path (str) – 파일에 쓰기.
path_append (str) – 파일에 추가.
pylogging – Python의
logging시스템에 쓰기.pylogging_logger (logging.Logger) – 지정된 Logger를 사용하여 Python의
logging시스템에 쓰기.pylogging_level (int) – 지정된 레벨을 사용하여 Python의
logging시스템에 쓰기.pylogging_name (str) – 지정된 로거 이름을 사용하여 Python의
logging시스템에 쓰기.pylogging_logger가None인 경우에만 사용됩니다. 기본값은pymupdf입니다.
pylogging*인수가None이 아니면 Python의 로깅 시스템 에 씁니다.
- sRGB_to_pdf(srgb)¶
v1.17.4에서 새로 추가됨
Page.get_text()딕셔너리 “dict” 및 “rawdict” 에서 발생하는 것처럼 주어진 sRGB 색상 정수에 대한 PDF 색상 삼중(빨강, 녹색, 파랑)을 반환하는 편의 함수.
- 매개변수:
srgb (int) – RRGGBB 형식의 정수로, 각 색상 구성 요소는 range(255)의 정수입니다.
- 반환:
동일한 색상을 나타내는 0 <= item <= 1 구간의 float 항목을 가진 튜플(빨강, 녹색, 파랑). 예:
sRGB_to_pdf(0xff0000) = (1, 0, 0)(빨강).
- sRGB_to_rgb(srgb)¶
v1.17.4에서 새로 추가됨
주어진 sRGB 색상 정수에 대한 색상(빨강, 녹색, 파랑)을 반환하는 편의 함수.
- 매개변수:
srgb (int) – RRGGBB 형식의 정수로, 각 색상 구성 요소는 range(255)의 정수입니다.
- 반환:
동일한 색상을 나타내는
range(256)의 정수 항목을 가진 튜플(빨강, 녹색, 파랑). 예:sRGB_to_pdf(0xff0000) = (255, 0, 0)(빨강).
- glyph_name_to_unicode(name)¶
v1.18.0에서 새로 추가됨
**Adobe Glyph List**를 기반으로 글리프 이름의 유니코드 번호를 반환합니다.
- 매개변수:
name (str) – 일부 글리프의 이름. 이 함수는 Adobe Glyph List 에 기반합니다.
- 반환 형식:
int
- 반환:
유니코드. 유효하지 않은
name항목은0xfffd (65533)을 반환합니다.참고
유사한 기능이 fontTools 패키지의 agl 하위 패키지에서 제공됩니다.
- unicode_to_glyph_name(ch)¶
v1.18.0에서 새로 추가됨
**Adobe Glyph List**를 기반으로 유니코드 번호의 글리프 이름을 반환합니다.
- 매개변수:
ch (int) – 예를 들어
ord("ß")로 주어진 유니코드. 이 함수는 Adobe Glyph List 에 기반합니다.- 반환 형식:
str
- 반환:
글리프 이름. 예:
pymupdf.unicode_to_glyph_name(ord("Ä"))는'Adieresis'를 반환합니다.참고
유사한 기능은 패키지 fontTools 의 agl 하위 패키지에서 제공됩니다.
- css_for_pymupdf_font(fontcode, *, CSS=None, archive=None, name=None)¶
v1.21.0의 새로운 기능
“Story” 애플리케이션에서 사용하기 위한 유틸리티 함수.
pymupdf-fonts에서 주어진 fontcode에 대한 CSS
@font-face항목을 생성합니다. 문자열 “fontcode”로 시작하는 모든 글꼴에 대한 CSS font-family를 생성합니다.패키지 pymupdf-fonts의 글꼴 명명 규칙은 “fontcode<sf>”이며, 여기서 접미사 “sf”는 “”(비어 있음), “it”/”i”, “bo”/”b” 또는 “bi” 중 하나입니다. 이러한 접미사는 따라서 해당 글꼴의 일반, 기울임꼴, 굵게 또는 굵은 기울임꼴 변형을 나타냅니다.
예를 들어, 글꼴 코드 “notos”는 다음 글꼴을 나타냅니다
“notos” - “Noto Sans Regular”
“notosit” - “Noto Sans Italic”
“notosbo” - “Noto Sans Bold”
“notosbi” - “Noto Sans Bold Italic”
함수는 (최대) 4개의 CSS
@font-face정의를 생성하고font-family이름 “notos”(또는 제공된 경우 “name” 값)를 집합적으로 할당합니다. 연결된 글꼴 버퍼는 제공된 아카이브에 배치/추가됩니다.Story 의 Python API에서 글꼴을 사용하려면
.set_font(fontcode)(또는 주어진 경우 “name”)를 실행하세요. 올바른 글꼴 두께 또는 스타일이 필요에 따라 자동으로 선택됩니다.예를 들어 위의 “notos”로 “sans-serif” HTML 표준(즉, Helvetica)을 대체하려면 다음을 실행하세요. “sans-serif”가 사용될 때마다(명시적으로든 암시적으로든) Noto Sans 글꼴이 선택됩니다.
CSS = pymupdf.css_for_pymupdf_font("notos", name="sans-serif", archive=...)CSS 소스를 받아서 새로운 CSS 정의가 추가된 CSS 소스를 반환합니다.
- 매개변수:
fontcode (str) – 패키지 pymupdf-fonts 에 있는 글꼴 코드 중 하나(일반적으로 글꼴 패밀리의 일반 버전을 나타냄).
CSS (str) – 기존 CSS 소스 또는
None. 함수는 새로운 정의를 여기에 추가합니다. 이것은 Story 를 생성할 때user_css로 사용해야 하는 문자열입니다.archive – Archive (아카이브), 필수. “fontcode”에 대해 찾은 모든 글꼴 바이너리(최대 4개)가 아카이브에 추가됩니다. 이것은 Story 를 생성할 때 Archive (아카이브) 로 사용해야 하는 아카이브입니다.
name (str) – “fontcode” 글꼴을 찾을 이름. 생략하면 “fontcode”가 사용됩니다.
- 반환 형식:
str
- 반환:
fontcode의 각 글꼴 변형에 대한
@font-face문이 추가된 수정된 CSS. “fontcode”와 연결된 Fontbuffers가 ‘archive’에 추가됩니다. 함수는 자동으로 최대 4개의 글꼴 변형을 찾습니다. 모든 pymupdf-fonts(수학이나 음악 등 특수 목적이 아닌 것)는 일반, 굵게, 기울임꼴 및 굵은 기울임꼴 변형을 가지고 있습니다. 현재 사용 가능한 글꼴 코드를 확인하려면pymupdf.fitz_fontdescriptors.keys()를 확인하세요. 이것은dict_keys(['cascadia', 'cascadiai', 'cascadiab', 'cascadiabi', 'figbo', 'figo', 'figbi', 'figit', 'fimbo', 'fimo', 'spacembo', 'spacembi', 'spacemit', 'spacemo', 'math', 'music', 'symbol1', 'symbol2', 'notosbo', 'notosbi', 'notosit', 'notos', 'ubuntu', 'ubuntubo', 'ubuntubi', 'ubuntuit', 'ubuntm', 'ubuntmbo', 'ubuntmbi', 'ubuntmit'])와 같은 것을 보여줍니다.“Helvetica” 대신 “Noto Sans” 글꼴을 사용하는 완전한 코드 조각입니다:
arch = pymupdf.Archive() CSS = pymupdf.css_for_pymupdf_font("notos", name="sans-serif", archive=arch) story = pymupdf.Story(user_css=CSS, archive=arch)
- make_table(rect, cols=1, rows=1)¶
v1.17.4에서 새로 추가됨
사각형을 동일한 크기의 하위 사각형으로 분할하는 편의 함수.
rows리스트의 리스트를 반환하며, 각 리스트는cols개의 Rect 항목을 포함합니다. 각 하위 사각형은 행 및 열 인덱스로 주소를 지정할 수 있습니다.
- 매개변수:
rect (rect_like) – 분할할 사각형.
cols (int) – 원하는 열 수.
rows (int) – 원하는 행 수.
- 반환:
동일한 크기의 Rect 객체 리스트. 이들의 합집합은 rect 와 같습니다.
cell = pymupdf.make_table(rect, cols=4, rows=3)로 생성된 3x4 테이블의 레이아웃은 다음과 같습니다:
- planish_line(p1, p2)¶
버전 1.16.2의 새로운 기능
p1에서 p2로의 선을 x축에 매핑하는 행렬을 반환합니다. p1은 (0,0)이 되고 p2는 (0,0)까지의 동일한 거리를 가진 점이 됩니다.
- 매개변수:
p1 (point_like) – 선의 시작점.
p2 (point_like) – 선의 끝점.
- 반환 형식:
- 반환:
회전과 이동을 결합한 행렬:
>>> p1 = pymupdf.Point(1, 1) >>> p2 = pymupdf.Point(4, 5) >>> abs(p2 - p1) # distance of points 5.0 >>> m = pymupdf.planish_line(p1, p2) >>> p1 * m Point(0.0, 0.0) >>> p2 * m Point(5.0, -5.960464477539063e-08) >>> # distance of the resulting points >>> abs(p2 * m - p1 * m) 5.0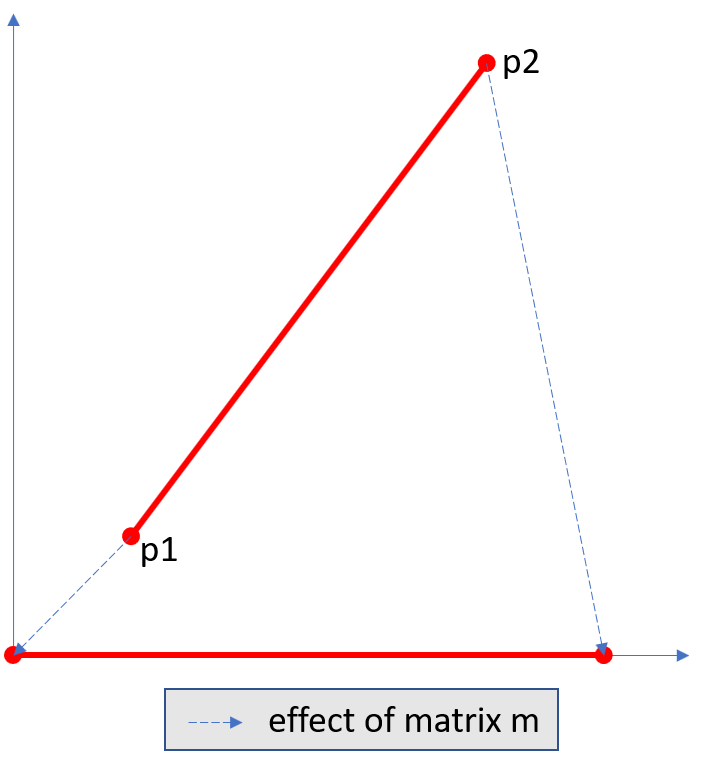
- paper_sizes()¶
사전 정의된 용지 형식의 딕셔너리.
paper_size()의 기반으로 사용됩니다.
- fitz_fontdescriptors¶
v1.17.5의 새로운 기능
저장소 pymupdf-fonts 에서 사용 가능한 글꼴의 딕셔너리. 항목은 예약된 글꼴 이름으로 키가 지정되며 다음과 같은 정보를 제공합니다:
In [2]: pymupdf.fitz_fontdescriptors.keys() Out[2]: dict_keys(['figbo', 'figo', 'figbi', 'figit', 'fimbo', 'fimo', 'spacembo', 'spacembi', 'spacemit', 'spacemo', 'math', 'music', 'symbol1', 'symbol2']) In [3]: pymupdf.fitz_fontdescriptors["fimo"] Out[3]: {'name': 'Fira Mono Regular', 'size': 125712, 'mono': True, 'bold': False, 'italic': False, 'serif': True, 'glyphs': 1485}
pymupdf-fonts가 설치되지 않은 경우 딕셔너리는 비어 있습니다.딕셔너리 키는 예를 들어
font = pymupdf.Font("fimo")를 통해 Font 를 정의하는 데 사용할 수 있습니다 – 내장 글꼴 “Helvetica” 등과 동일하게 사용할 수 있습니다.
- PYMUPDF_MESSAGE¶
PyMuPDF 가 가져올 때
os.environ에 있으면 PyMuPDF 메시지의 대상을 설정합니다. 그렇지 않으면 메시지는sys.stdout으로 전송됩니다.
값이
fd:로 시작하면 나머지 텍스트는 메시지가 기록되는 정수 파일 디스크립터여야 합니다.
예를 들어
PYMUPDF_MESSAGE=fd:2는 메시지를 stderr로 보냅니다.값이
path:로 시작하면 나머지 텍스트는 메시지가 기록되는 파일의 경로입니다. 파일이 이미 존재하면 잘립니다.값이
path+:로 시작하면 나머지 텍스트는 메시지가 기록되는 파일의 경로입니다. 파일이 이미 존재하면 출력을 추가합니다.값이
logging:로 시작하면 메시지는 Python의 로깅 시스템 에 기록됩니다. 나머지 텍스트는 쉼표로 구분된 name=value 항목을 포함할 수 있습니다:
level=는 로깅 레벨을 설정합니다.
name=는 로거 이름을 설정합니다(기본값은pymupdf).다른 항목은 무시됩니다.
다른 접두사는 오류를 발생시킵니다.
set_messages()도 참조하세요.
- pdfcolor¶
v1.19.6의 새로운 기능
색상 이름을 키로 하는 PDF 형식의 약 500개의 RGB 색상을 포함합니다. 내용을 확인하려면
pymupdf.pdfcolor.keys()를 확인할 수 있습니다.예제:
pymupdf.pdfcolor["red"] = (1.0, 0.0, 0.0)
pymupdf.pdfcolor["skyblue"] = (0.5294117647058824, 0.807843137254902, 0.9215686274509803)
pymupdf.pdfcolor["wheat"] = (0.9607843137254902, 0.8705882352941177, 0.7019607843137254)
- get_pdf_now()¶
현재 로컬 타임스탬프를 PDF 호환 형식으로 반환하는 편의 함수. 예: UTC 자오선에서 서쪽으로 4시간 떨어진 시간대의 2017년 5월 1일 12:15:25 로컬 날짜/시간에 대한 D:20170501121525-04’00’.
- 반환 형식:
str
- 반환:
현재 로컬 PDF 타임스탬프.
- get_text_length(text, fontname='helv', fontsize=11, encoding=TEXT_ENCODING_LATIN)¶
버전 1.14.7의 새로운 기능
주어진 내장 글꼴,
fontsize및 인코딩으로 출력 시 텍스트 길이를 계산합니다.
- 매개변수:
text (str) – 텍스트 문자열.
fontname (str) – 글꼴 이름. PDF Base 14 글꼴 또는 “예약된” 글꼴 이름으로 식별되는 CJK 글꼴 중 하나여야 합니다(
Page.insert_font()의 표 참조).fontsize (float) –
fontsize.encoding (int) – 사용할 인코딩. 0 = Latin 외에 1 = Greek 및 2 = Cyrillic(러시아어)을 사용할 수 있습니다. Base-14 글꼴 “Helvetica”, “Courier” 및 “Times”와 그 변형에만 관련됩니다. 해당 텍스트 삽입에서와 동일한 값을 사용해야 합니다.
- 반환 형식:
float
- 반환:
문자열이 가질 포인트 단위의 길이(예:
Page.insert_text()에서 사용할 때).참고
이 함수는 계산만 수행합니다 – 글꼴이나 텍스트를 삽입하지 않습니다.
참고
Font 클래스는 유사한 메서드
Font.text_length()를 제공하며, Base-14 글꼴과 문자 맵(CMap, Type 0 글꼴)이 있는 모든 글꼴을 지원합니다.
- get_pdf_str(text)¶
PDF 호환 문자열 생성: 텍스트에 코드 포인트 ord(c) > 255 가 포함되어 있으면 BOM이 있는 UTF-16BE로 변환되어 <feff…> 와 같이 “<>” 괄호로 둘러싸인 16진수 문자 문자열이 됩니다. 그렇지 않으면 (둥근) 괄호로 둘러싸인 문자열을 반환하며, ASCII 범위 밖의 모든 문자를 특수 코드로 대체합니다. 또한 모든 “(”, “)” 또는 백슬래시는 백슬래시로 이스케이프됩니다.
- 매개변수:
text (str) – 변환할 객체
- 반환 형식:
str
- 반환:
() 또는 <> 로 둘러싸인 PDF 호환 문자열.
- image_profile(stream)¶
v1.16.7의 새로운 기능
v1.19.5에서 변경됨: EXIF 데이터가 있으면 추출된 자연 이미지 방향도 반환합니다.
v1.22.5에서 변경됨: 오류 경우 빈 딕셔너리 대신 항상
None을 반환합니다.메모리 영역으로 제공된 이미지의 중요한 속성을 표시합니다. 주요 목적은 이를 결정하기 위해 다른 Python 패키지를 사용하는 것을 피하는 것입니다.
- 매개변수:
stream (bytes|bytearray|BytesIO|file) – 메모리의 이미지 또는 열린 파일. 메모리의 이미지는
bytes,bytearray또는io.BytesIO형식 중 하나일 수 있습니다.- 반환 형식:
dict
- 반환:
예외는 발생하지 않습니다. 오류가 발생하면
None이 반환됩니다. 그렇지 않으면 다음 항목이 있습니다:In [2]: pymupdf.image_profile(open("nur-ruhig.jpg", "rb").read()) Out[2]: {'width': 439, 'height': 501, 'orientation': 0, # natural orientation (from EXIF) 'transform': (1.0, 0.0, 0.0, 1.0, 0.0, 0.0), # orientation matrix 'xres': 96, 'yres': 96, 'colorspace': 3, 'bpc': 8, 'ext': 'jpeg', 'cs-name': 'DeviceRGB'}
orientation에 인코딩된 Exif 정보 및 이에 해당하는transform행렬과의 관계는 다음과 같습니다(MuPDF 문서에서 인용, ccw = 반시계 방향):
정의되지 않음
0도 반시계 방향 회전. (Exif = 1)
90도 반시계 방향 회전. (Exif = 8)
180도 반시계 방향 회전. (Exif = 3)
270도 반시계 방향 회전. (Exif = 6)
X축으로 뒤집기. (Exif = 2)
X축으로 뒤집은 후 90도 반시계 방향 회전. (Exif = 5)
X축으로 뒤집은 후 180도 반시계 방향 회전. (Exif = 4)
X축으로 뒤집은 후 270도 반시계 방향 회전. (Exif = 7)
참고
일부 “특수” 이미지(FAX 인코딩, RAW 형식 등)의 경우 이 메서드는 작동하지 않습니다. 그러나 PyMuPDF에서
Document.extract_image()를 사용하거나Pixmap(doc, xref)를 통해 픽스맵을 생성하는 등으로 이러한 이미지를 계속 작업할 수 있습니다. 이러한 메서드는 결과를 반환하기 전에 특수 이미지를 자동으로 PNG 형식으로 변환합니다.PDF에 포함된 이미지의 속성은
xref를 통해 가져올 수도 있습니다. 이 경우 원시 스트림을 추출해야 합니다:pymupdf.image_profile(doc.xref_stream_raw(xref)).”dict” 또는 “rawdict” 옵션을 사용하는
Page.get_text()의 이미지 블록으로 반환된 이미지도 지원됩니다.
- ConversionHeader("text", filename="UNKNOWN")¶
페이지 텍스트 출력으로 유효한 문서를 만들기 위해 필요한 헤더 문자열을 반환합니다.
- 매개변수:
output (str) – 문서 타입. get_text() 의 출력 매개변수와 동일하게 사용하세요.
filename (str) – 출력 타입 “json” 및 “xml”에서 사용할 선택적 임의 이름.
- 반환 형식:
str
- ConversionTrailer(output)¶
페이지 텍스트 출력으로 유효한 문서를 만들기 위해 필요한 트레일러 문자열을 반환합니다. 예제는
Page.get_text()를 참조하세요.
- 매개변수:
output (str) – 문서 타입. get_text() 의 출력 매개변수와 동일하게 사용하세요.
- 반환 형식:
str
- Document.del_xml_metadata()¶
PDF에서 XML 기반 메타데이터를 포함하는 객체를 삭제합니다. (Py-) MuPDF는 XML 기반 메타데이터를 지원하지 않습니다. 기존 메타데이터 딕셔너리가 독점적으로 사용되도록 하려면 이것을 사용하세요. 많은 타사 PDF 프로그램이 자체 메타데이터를 XML 형식으로 삽입하므로 기존 딕셔너리에 저장한 내용을 덮어쓸 수 있습니다. 이 메서드는 이러한 참조를 삭제하며, 해당 PDF 객체는 다음 파일 가비지 수집 중에 삭제됩니다.
- Document.xml_metadata_xref()¶
PDF의 XML 기반 메타데이터
xref가 있으면 반환합니다 –Document.del_xml_metadata()도 참조하세요.Document.xref_stream()을 통해 콘텐츠를 검색한 다음 일부 XML 소프트웨어를 사용하여 작업할 수 있습니다.
- 반환 형식:
int
- 반환:
PDF 파일 레벨 XML 메타데이터의
xref– 없으면 0.
- Page.run(dev, transform)¶
디바이스를 통해 페이지 실행.
- 매개변수:
dev (Device (디바이스)) – 디바이스, Device (디바이스) 생성자 중 하나에서 얻음.
transform (Matrix) – 페이지에 적용할 변환. 변환이 필요 없으면 Identity 로 설정하세요.
- Page.get_bboxlog(layers=False)¶
v1.19.0의 새로운 기능
v1.22.0에서 변경됨: 선택적으로 경계 상자에 적용 가능한 OCG 이름도 반환합니다.
- 반환:
텍스트, 이미지 또는 그리기 객체를 둘러싸는 사각형 목록. 각 항목은
(type, (x0, y0, x1, y1))튜플이며, 두 번째 튜플은 사각형 좌표로 구성되고 type 은 다음 값 중 하나입니다.layers=True인 경우 OCG 이름 또는None을 포함하는 세 번째 항목이 있습니다:(type, (x0, y0, x1, y1), None).
"fill-text"– 일반 텍스트(문자 경계 없이 그려짐)
"stroke-text"– 문자 경계만 표시하는 텍스트
"ignore-text"– 표시되지 않아야 하는 텍스트(예: OCR 텍스트 레이어에서 사용)
"fill-path"– 채우기 색상으로 그리기(경계 없음)
"stroke-path"– 경계로 그리기(채우기 색상 없음)
"fill-image"– 이미지 표시
"fill-shade"– 음영 표시항목 시퀀스는 페이지의 모양을 구축하기 위해 이러한 명령이 실행되는 순서 를 나타냅니다. 따라서 항목의 bbox가 이전 항목과 교차하거나 포함하는 경우 이전 항목이 (부분적으로) 덮이거나 숨겨질 수 있습니다.
따라서 이 목록을 사용하여 이러한 상황을 감지할 수 있습니다. 이 목록의 항목 인덱스는
Page.get_drawings()및Page.get_texttrace()에서 반환된 딕셔너리의"seqno"값과 같습니다.
- Page.get_texttrace()¶
v1.18.16의 새로운 기능
v1.19.0에서 변경됨: 키 “seqno” 추가.
v1.19.1에서 변경됨: 스트로크 및 채우기 색상이 이제 항상 RGB 또는 GRAY입니다
v1.19.3에서 변경됨:
dir != (1, 0)인 경우에도 스팬 및 문자 bbox가 이제 올바릅니다.v1.22.0에서 변경됨: 새로운 딕셔너리 키 “layer” 추가.
페이지의 저수준 텍스트 정보를 반환합니다. 이 메서드는 모든 문서 타입에서 사용할 수 있습니다. 결과는 다음 내용을 가진 Python 딕셔너리 목록입니다:
{ 'ascender': 0.83251953125, # font ascender (1) 'bbox': (458.14019775390625, # span bbox x0 (7) 749.4671630859375, # span bbox y0 467.76458740234375, # span bbox x1 757.5071411132812), # span bbox y1 'bidi': 0, # bidirectional level (1) 'chars': ( # char information, tuple[tuple] (45, # unicode (4) 16, # glyph id (font dependent) (458.14019775390625, # origin.x (1) 755.3758544921875), # origin.y (1) (458.14019775390625, # char bbox x0 (6) 749.4671630859375, # char bbox y0 462.9649963378906, # char bbox x1 757.5071411132812)), # char bbox y1 ( ... ), # more characters ), 'color': (0.0,), # text color, tuple[float] (1) 'colorspace': 1, # number of colorspace components (1) 'descender': -0.30029296875, # font descender (1) 'dir': (1.0, 0.0), # writing direction (1) 'flags': 12, # font flags (1) 'font': 'CourierNewPSMT', # font name (1) 'linewidth': 0.4019999980926514, # current line width value (3) 'opacity': 1.0, # alpha value of the text (5) 'layer': None, # name of Optional Content Group (9) 'seqno': 246, # sequence number (8) 'size': 8.039999961853027, # font size (1) 'spacewidth': 4.824785133358091, # width of space char 'type': 0, # span type (2) 'wmode': 0 # writing mode (1) }세부사항:
“(1)”로 태그된 위의 정보는 TextPage 에서 설명한 것과 동일한 의미와 값을 가집니다.
글꼴
flags값에는 위첨자 플래그 비트가 포함되지 않습니다: 위첨자 감지는 MuPDF TextPage 코드 내에서 수행됩니다 – 이것은 어떤 글꼴의 속성도 아닙니다.텍스트 color 는 일반적인 float 튜플 0 <= f <= 1로 인코딩됩니다 – sRGB 형식이 아닙니다.
span["type"]에 따라 이를 채우기 색상 또는 스트로크 색상으로 해석하세요.3가지 텍스트 스팬 타입이 있습니다:
0: 채워진 텍스트 – PDF 텍스트 렌더링 모드 0(
0 Tr, PDF의 기본값)과 동일하며, 각 문자의 “내부”만 표시됩니다.1: 스트로크 텍스트 –
1 Tr와 동일하며, 문자 경계만 표시됩니다.3: 무시된 텍스트 –
3 Tr(숨겨진 텍스트)와 동일합니다.이 맥락에서 선 너비는
span["type"] != 0처리에만 중요합니다: 문자 경계선의 두께를 결정합니다. 이 값은 텍스트 데이터와 함께 전혀 제공되지 않을 수 있습니다. 이 경우fontsize의 5% 값(span["size"] * 0,05)이 생성됩니다. 종종 PDF의 “인위적인” 굵은 텍스트는2 Tr로 생성됩니다. 이 경우에 해당하는 스팬 타입은 없습니다. 대신 해당 텍스트는 두 개의 연속된 스팬으로 표현됩니다 – 타입이 각각 0과 1인 것을 제외하고 모든 면에서 동일합니다. 이러한 상황을 처리하는 것은 사용자의 책임입니다 -Page.get_text()에서는 MuPDF가 이를 수행합니다.데이터 압축을 위해 여기에 문자의 유니코드가 제공됩니다. 문자 자체는 내장 함수
chr()을 사용하세요.스팬 텍스트의 알파/불투명도 값,
0 <= opacity <= 1, 0은 보이지 않는 텍스트, 1(100%)은 불투명합니다.span["type"]에 따라 이 값을 fill 불투명도 또는 stroke 불투명도로 해석하세요.(v1.19.0에서 변경됨) 이 값은 “rawdict”의
char["bbox"]와 같거나 가깝습니다. 특히 bbox height 값은 항상 “small glyph heights” 가 요청된 것처럼 계산됩니다.(v1.19.0의 새로운 기능) 이것은 모든 문자 bbox의 합집합입니다.
(v1.19.0의 새로운 기능) 페이지의 모양을 구축하는 명령을 열거합니다. 텍스트가 “나중에” 그려지거나 어떤 객체 위에 그려진 객체에 의해 효과적으로 숨겨지는지 확인하는 데 사용할 수 있습니다. 따라서 더 높은 시퀀스 번호를 가진 그리기 또는 이미지가 있고, 그 bbox가 이 텍스트 스팬의 (일부)와 겹치는 경우, 그러한 객체가 해당 텍스트를 숨긴다고 가정할 수 있습니다. 다른 텍스트 스팬은 한 번에 생성된 경우 동일한 시퀀스 번호를 가집니다.
(v1.22.0의 새로운 기능) 해당하는 경우 Optional Content Group (OCG)의 이름 또는
None.
page.get_text("rawdict")와 비교한page.get_texttrace()의 유사점과 차이점 목록입니다:
이 메서드는 “rawdict” 추출과 비교하여 최대 2배 빠릅니다. 텍스트 양에 따라 다릅니다.
반환된 데이터는 크기가 훨씬 작습니다 – 더 많은 정보를 제공하지만.
추가 유형의 텍스트 보이지 않음을 감지할 수 있습니다: opacity = 0 또는 type > 1 또는 더 높은 시퀀스 번호를 가진 객체의 겹치는 bbox.
MuPDF가 인식되지 않은 문자에 대해 유니코드 0xFFFD(65533)를 반환하는 경우, 글리프 id에서 원하는 정보를 추론할 수 있을 수 있습니다.
span["chars"]는 공백을 포함하지 않습니다, 문서 작성자가 명시적으로 코딩한 경우를 제외하고.Page.get_text()메서드에서 발생하는 것처럼 절대 생성되지 않습니다. 여기서 자체 계산을 수행하는 데 도움이 되도록 공백 문자의 너비가 제공됩니다. 이 값은 가능한 경우 글꼴에서 파생됩니다. 그렇지 않으면 대체 글꼴의 값이 사용됩니다.TextPage 에서 발생하는 것처럼 텍스트를 구성하려는 시도가 없습니다(블록, 라인, 스팬 및 문자의 계층 구조). 문자는 단순히 순차적으로 하나씩 추출되어 스팬에 배치됩니다. 스팬의 특성이 변경될 때마다 새로운 스팬이 시작됩니다. 따라서 동일한 스팬에서 다른
origin.y값을 가진 문자를 찾을 수 있습니다(이는 다른 라인에 나타날 것임을 의미). 스팬 문자가 특정 순서로 정렬되어 있다고 가정할 수 없습니다 –span["dir"],span["wmode"]등을 고려하여 정보를 직접 이해해야 합니다.
- 합자는 다음과 같이 표현됩니다:
MuPDF는 다음 합자를 처리합니다: “fi”, “ff”, “fl”, “ft”, “st”, “ffi”, “ffl” (처음 3개만 주로 사용됨). 페이지에 예를 들어 합자 “fi”가 포함되어 있으면 다음 두 문자 항목이 서로 연속으로 나타납니다:
(102, glyph, (x, y), (x0, y0, x1, y1)) # 102 = ord("f") (105, -1, (x, y), (x0, y0, x0, y1)) # 105 = ord("i"), empty bbox!이것은 첫 번째 합자 문자의 bbox가 완전한 복합 글리프를 포함하는 영역임을 의미합니다. 후속 합자 구성 요소는 글리프 값 -1과 너비가 0인 bbox로 인식할 수 있습니다.
2개 또는 3개의 문자 튜플을 합자 자체를 나타내는 하나로 대체할 수 있습니다. 다음 합자-유니코드 매핑을 사용하세요:
"ff" -> 0xFB00
"fi" -> 0xFB01
"fl" -> 0xFB02
"ffi" -> 0xFB03
"ffl" -> 0xFB04
"ft" -> 0xFB05
"st" -> 0xFB06따라서 위의 두 예제 튜플을 다음 단일 튜플로 대체할 수 있습니다:
(0xFB01, glyph, (x, y), (x0, y0, x1, y1))(일반적으로 해당 글꼴에서 0xFB01에 대한 올바른 글리프 id를 조회할 필요는 없지만,font.has_glyph(0xFB01)을 실행하고 반환 값을 사용할 수 있습니다).v1.19.3에서 변경됨: 다른 텍스트 추출 메서드와 유사하게, 문자 및 스팬 bbox는 문자 쿼드를 둘러쌉니다. 쿼드를 복구하려면 딕셔너리 출력 구조 에서 설명한 것과 동일한 메서드
recover_quad(),recover_char_quad()또는recover_span_quad()를 따르세요. 쓰기 방향에는None또는span["dir"]을 사용하세요.v1.21.1에서 변경됨: 해당하는 경우 OCG의 이름이
"layer"에 표시됩니다.
- Page.wrap_contents()¶
페이지의 소위 그래픽 상태가 균형을 이루고 새 콘텐츠가 올바르게 삽입될 수 있도록 합니다.
PyMuPDF 버전 1.24.1+에서 이 메서드가 개선되어 필요에 따라 자동으로 실행되므로 더 이상 신경 쓸 필요가 없습니다.
이를 달성하기 위해
Page.clean_contents()사용을 권장하지 않습니다.
- Page.is_wrapped¶
페이지의 소위 그래픽 상태가 균형을 이루는지 나타냅니다.
False인 경우 새 콘텐츠가 삽입되면Page.wrap_contents()를 실행해야 합니다(overlay=True모드에서만 관련됨). 최신 버전(1.24.1+)에서는 이 확인 및 해당 조정이 자동으로 실행됩니다 – 따라서 더 이상 신경 쓸 필요가 없습니다.
- 반환 형식:
bool
- Page.get_text_blocks(flags=None)¶
TextPage.extractBLOCKS()의 더 이상 사용되지 않는 래퍼. 대신 “blocks” 옵션을 사용하는Page.get_text()를 사용하세요.
- 반환 형식:
list[tuple]
- Page.get_text_words(flags=None, delimiters=None)¶
TextPage.extractWORDS()의 더 이상 사용되지 않는 래퍼. 대신 “words” 옵션을 사용하는Page.get_text()를 사용하세요.
- 반환 형식:
list[tuple]
- Page.get_displaylist()¶
리스트 디바이스를 통해 페이지를 실행하고 디스플레이 리스트를 반환합니다.
- 반환 형식:
- 반환:
페이지의 디스플레이 리스트.
- Page.get_contents()¶
PDF 전용: 페이지의
contents객체의xref목록을 검색합니다. 비어 있거나 여러 정수를 포함할 수 있습니다. 페이지가 정리된 경우(Page.clean_contents()) 항목은 하나 이하입니다. 각/Contents객체의 “source”는 이 목록의 항목을 사용하여Document.xref_stream()으로 개별적으로 읽을 수 있습니다. 반면Page.read_contents()메서드는 이 목록을 순회하고 해당 소스를 하나의bytes객체로 연결합니다.
- 반환 형식:
list[int]
- Page.set_contents(xref)¶
PDF 전용: 페이지의
/Contents키가 이 xref를 가리키도록 합니다. 이전에 사용된 모든 콘텐츠 객체는 무시되며 가비지 수집을 통해 제거할 수 있습니다.
- Page.clean_contents(sanitize=True)¶
v1.17.6에서 변경됨
PDF 전용: 이 페이지와 연결된 모든
contents객체를 정리하고 연결합니다. “정리”에는 구문 수정, 표준화 및 콘텐츠 스트림의 “예쁘게 인쇄”가 포함됩니다. sanitize가 true이면contents와resources객체 간의 불일치도 수정됩니다. 자세한 내용은Page.get_contents()를 참조하세요.버전 1.16.0에서 변경됨: 주석은 이 메서드에 의해 더 이상 암시적으로 정리되지 않습니다.
Annot.clean_contents()를 별도로 사용하세요.
- 매개변수:
sanitize (bool) – (v1.17.6의 새로운 기능) true이면 리소스와 콘텐츠 객체에서의 실제 사용 간의 동기화가 이루어집니다. 예를 들어, 글꼴이 페이지의 어떤 텍스트에도 실제로 사용되지 않으면
/Resources/Font객체에서 삭제됩니다.경고
이것은 대량의 새 데이터를 생성하고 이전 데이터를 사용하지 않게 만들 수 있는 복잡한 함수입니다. 증분 저장 옵션과 함께 사용하는 것은 권장되지 않습니다. 또한 결과 단일 /Contents 객체는 압축되지 않습니다. 따라서 “deflate=True, garbage=3” 옵션을 사용하여 새 파일 에 저장해야 합니다.
PDF 페이지에 올바른 삽입을 보장하기 위해 이 메서드를 더 이상 사용하지 마세요. PyMuPDF 버전 1.24.2부터는 이것이 자동으로 처리됩니다.
- Annot.clean_contents(sanitize=True)¶
주석과 연결된
contents스트림을 정리합니다. 이것은Page.clean_contents()가 수행하는 것과 동일한 작업입니다 – 단지 이 주석으로 제한됩니다.
- Document.get_char_widths(xref=0, limit=256)¶
문서에 있는 글꼴에 대한 문자 글리프 및 너비 목록을 반환합니다. 글꼴은 PDF 교차 참조 번호
xref로 지정해야 합니다. 이 함수는Page.insert_text()및Page.insert_textbox()에서 자동으로 호출됩니다. 따라서 직접 수행할 필요는 거의 없습니다.
- 매개변수:
xref (int) – PDF에 포함된 글꼴의 교차 참조 번호. 글꼴
xref를 찾으려면 예를 들어 페이지 번호 pno 의 doc.get_page_fonts(pno) 를 사용하고 반환된 목록 항목 중 하나의 첫 번째 항목을 가져옵니다.limit (int) – 반환된 항목 수를 제한합니다. 256의 기본값은 1바이트 문자만 지원하는 소위 “simple fonts”(이 메서드로 확인됨)에 대해 적용됩니다. 모든 PDF Base 14 글꼴 는 simple fonts입니다.
- 반환 형식:
list
- 반환:
limit 튜플 목록. 각 문자 c 는 ord(c) 인덱스를 가진 이 목록에 (g, w) 항목을 가집니다. 튜플의 항목 g (정수)는 문자의 글리프 id이고, float w 는 정규화된 너비입니다. 일부
fontsize에 대한 실제 너비는 w * fontsize 로 계산할 수 있습니다. simple fonts의 경우 g 항목은 항상 안전하게 무시할 수 있습니다. 다른 모든 경우 g 는 c 를 그래픽으로 표현하는 기반입니다.이 함수는 text 라는 문자열의 픽셀 너비를 계산합니다:
def pixlen(text, widthlist, fontsize): try: return sum([widthlist[ord(c)] for c in text]) * fontsize except IndexError: raise ValueError(f"max. code point found: {ord(max(text))}, increase limit")
- recover_quad(line_dir, span)¶
Page.get_text()의 “dict” 또는 “rawdict” 옵션을 통해 추출된 텍스트 스팬의 사각형을 계산합니다.
- 매개변수:
line_dir (tuple) – 소유 라인의
line["dir"].Page.get_texttrace()에서 가져온 스팬의 경우None을 사용하세요.span (dict) – 스팬.
- 반환:
스팬의 Quad, 텍스트 마커 주석(‘Highlight’ 등)에 사용 가능.
- recover_char_quad(line_dir, span, char)¶
Page.get_text()의 “rawdict” 옵션을 통해 추출된 텍스트 문자의 사각형을 계산합니다.
- 매개변수:
line_dir (tuple) – 소유 라인의
line["dir"].Page.get_texttrace()에서 가져온 스팬의 경우None을 사용하세요.span (dict) – 스팬.
char (dict) – 문자.
- 반환:
문자의 Quad, 텍스트 마커 주석(‘Highlight’ 등)에 사용 가능.
- recover_span_quad(line_dir, span, chars=None)¶
Page.get_text()의 “rawdict” 옵션을 통해 추출된 스팬의 문자 하위 집합의 사각형을 계산합니다.
- 매개변수:
line_dir (tuple) – 소유 라인의
line["dir"].Page.get_texttrace()에서 가져온 스팬의 경우None을 사용하세요.span (dict) – 스팬.
chars (list) – 고려할 문자. 주어진 경우 선택된 추출 옵션은 “rawdict”여야 합니다.
- 반환:
선택된 문자의 Quad, 텍스트 마커 주석(‘Highlight’ 등)에 사용 가능.
- recover_line_quad(line, spans=None)¶
Page.get_text()의 “dict” 또는 “rawdict” 옵션을 통해 추출된 텍스트 라인의 스팬 하위 집합의 사각형을 계산합니다.
- 매개변수:
line (dict) – 라인.
spans (list) –
line["spans"]의 하위 목록. 생략하면 전체 라인 쿼드가 반환됩니다.- 반환:
선택된 라인 스팬의 Quad, 텍스트 마커 주석(‘Highlight’ 등)에 사용 가능.
- get_tessdata(tessdata=None)¶
Tesseract 언어 지원 폴더 감지.
이 함수는 언어 지원 폴더가 직접 또는 환경 변수 TESSDATA_PREFIX에 지정되지 않은 경우에도 Tesseract를 통해 OCR을 활성화하는 데 사용됩니다.
<tessdata>가 설정되어 있으면 직접 반환합니다.
그렇지 않으면 설정된 경우
os.environ['TESSDATA_PREFIX']를 반환합니다.그렇지 않으면 Tesseract 설치를 검색하고 언어 지원 폴더를 반환합니다.
그렇지 않으면 예외를 발생시킵니다.