Images¶
문서 페이지에서 이미지 만들기¶
이 작은 스크립트는 문서 파일 이름을 받아 각 페이지에서 PNG 파일을 생성합니다.
문서는 지원되는 모든 타입 일 수 있습니다.
스크립트는 매개변수로 제공된 파일 이름을 기대하는 명령줄 도구로 작동합니다. 생성된 이미지 파일(페이지당 1개)은 스크립트 디렉토리에 저장됩니다:
import sys, pymupdf # import the bindings
fname = sys.argv[1] # get filename from command line
doc = pymupdf.open(fname) # open document
for page in doc: # iterate through the pages
pix = page.get_pixmap() # render page to an image
pix.save(f"page-{page.number}.png") # store image as a PNG
스크립트 디렉토리에는 이제 page-0.png, page-1.png 등의 PNG 이미지 파일이 포함됩니다. 그림은 페이지의 크기를 가지며 너비와 높이는 정수로 반올림됩니다. 예를 들어 A4 세로 크기 페이지의 경우 595 x 842 픽셀입니다. x 및 y 차원에서 96 dpi의 해상도를 가지며 투명도가 없습니다. 모든 것을 변경할 수 있습니다 – 방법은 다음 섹션을 참조하세요.
이미지 해상도 높이는 방법¶
문서 페이지의 이미지는 Pixmap 으로 표현되며, 픽스맵을 생성하는 가장 간단한 방법은 Page.get_pixmap() 메서드를 사용하는 것입니다.
이 메서드는 결과에 영향을 주는 많은 옵션이 있습니다. 그 중 가장 중요한 것은 확대, 회전, 왜곡 또는 미러링을 가능하게 하는 Matrix 입니다.
Page.get_pixmap() 은 기본적으로 아무것도 하지 않는 Identity 행렬을 사용합니다.
다음에서는 각 차원에 확대 배율 2를 적용하여 4배 더 나은 해상도의 이미지를 생성합니다(크기도 약 4배):
zoom_x = 2.0 # horizontal zoom
zoom_y = 2.0 # vertical zoom
mat = pymupdf.Matrix(zoom_x, zoom_y) # zoom factor 2 in each dimension
pix = page.get_pixmap(matrix=mat) # use 'mat' instead of the identity matrix
버전 1.19.2부터 해상도를 설정하는 더 직접적인 방법이 있습니다: "dpi" (인치당 도트 수) 매개변수를 "matrix" 대신 사용할 수 있습니다. 페이지의 300 dpi 이미지를 만들려면 pix = page.get_pixmap(dpi=300) 을 지정하세요. 표기법의 간결함 외에도, 이 방법의 추가 장점은 dpi 값이 이미지 파일과 함께 저장된다는 것입니다 – Matrix 표기법을 사용할 때는 자동으로 발생하지 않습니다.
부분 픽스맵 (클립) 생성 방법¶
항상 페이지의 전체 이미지가 필요하거나 원하는 것은 아닙니다. 예를 들어 GUI에서 이미지를 표시하고 해당 창을 페이지의 확대된 부분으로 채우고 싶을 때가 그런 경우입니다.
GUI 창에 전체 문서 페이지를 표시할 공간이 있다고 가정하지만, 이제 이 공간을 페이지의 오른쪽 아래 사분면으로 채워 4배 더 나은 해상도를 사용하고 싶다고 가정합니다.
이를 달성하려면 GUI에 표시하려는 영역과 같은 사각형을 정의하고 “clip”이라고 부르세요. PyMuPDF에서 사각형을 구성하는 방법 중 하나는 대각선으로 반대편에 있는 두 모서리를 제공하는 것이며, 여기서도 그렇게 합니다.
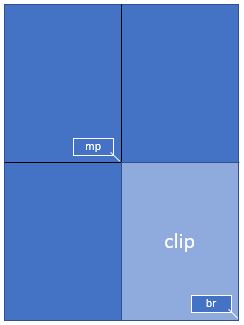
mat = pymupdf.Matrix(2, 2) # zoom factor 2 in each direction
rect = page.rect # the page rectangle
mp = (rect.tl + rect.br) / 2 # its middle point, becomes top-left of clip
clip = pymupdf.Rect(mp, rect.br) # the area we want
pix = page.get_pixmap(matrix=mat, clip=clip)
위에서는 두 개의 대각선 반대편 점을 지정하여 clip 을 구성합니다: 페이지 사각형의 중간점 mp 와 그 오른쪽 아래 rect.br 입니다.
클립을 GUI 창에 맞게 확대하는 방법¶
이전 섹션도 읽어보세요. 이번에는 클립의 확대 배율을 계산 하여 이미지가 주어진 GUI 창에 가장 잘 맞도록 합니다. 즉, 이미지의 너비 또는 높이(또는 둘 다)가 창 크기와 같아집니다. 다음 코드 스니펫을 위해서는 페이지의 클립 사각형을 받을 GUI 창의 WIDTH와 HEIGHT를 제공해야 합니다.
# WIDTH: width of the GUI window
# HEIGHT: height of the GUI window
# clip: a subrectangle of the document page
# compare width/height ratios of image and window
if clip.width / clip.height < WIDTH / HEIGHT:
# clip is narrower: zoom to window HEIGHT
zoom = HEIGHT / clip.height
else: # clip is broader: zoom to window WIDTH
zoom = WIDTH / clip.width
mat = pymupdf.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, clip=clip)
반대로, 이제 확대 배율이 있고 맞는 클립을 계산 해야 한다고 가정합니다.
이 경우 zoom = HEIGHT/clip.height = WIDTH/clip.width 이므로, clip.height = HEIGHT/zoom 과 clip.width = WIDTH/zoom 을 설정해야 합니다. 올바른 픽스맵을 계산하려면 페이지에서 클립의 왼쪽 위 지점 tl 을 선택하세요:
width = WIDTH / zoom
height = HEIGHT / zoom
clip = pymupdf.Rect(tl, tl.x + width, tl.y + height)
# ensure we still are inside the page
clip &= page.rect
mat = pymupdf.Matrix(zoom, zoom)
pix = pymupdf.Pixmap(matrix=mat, clip=clip)
주석 이미지 생성 또는 억제 방법¶
일반적으로 페이지의 픽스맵은 페이지의 주석도 표시합니다. 때로는 이것이 바람직하지 않을 수 있습니다.
렌더링된 페이지에서 주석 이미지를 억제하려면 Page.get_pixmap() 에서 annots=False 를 지정하세요.
주석을 별도로 렌더링할 수도 있습니다: 주석에는 자체 Annot.get_pixmap() 메서드가 있습니다. 결과 픽스맵은 주석 사각형과 동일한 크기를 가집니다.
이미지 추출 방법: 비 PDF 문서¶
이전 섹션과 달리, 이 섹션은 문서에 포함된 이미지를 추출 하는 것을 다루므로, 하나 이상의 페이지의 일부로 표시할 수 있습니다.
원본 이미지를 파일 형식 또는 메모리 영역으로 재생성하려면 기본적으로 두 가지 옵션이 있습니다:
문서를 PDF로 변환한 다음 PDF 전용 추출 방법 중 하나를 사용하세요. 이 스니펫은 문서를 PDF로 변환합니다:
>>> pdfbytes = doc.convert_to_pdf() # this a bytes object >>> pdf = pymupdf.open("pdf", pdfbytes) # open it as a PDF document >>> # now use 'pdf' like any PDF document
“dict” 매개변수와 함께
Page.get_text()를 사용하세요. 이것은 모든 문서 유형에 작동합니다. 페이지에 표시된 모든 텍스트와 이미지를 Python 딕셔너리 형식으로 추출합니다. 각 이미지는 메타 정보와 바이너리 이미지 데이터 를 포함하는 이미지 블록에 나타납니다. 딕셔너리 구조의 세부 사항은 TextPage 를 참조하세요. 이 방법은 PDF 파일에도 동일하게 작동합니다. 이것은 페이지에 표시된 모든 이미지의 목록을 생성합니다:>>> d = page.get_text("dict") >>> blocks = d["blocks"] # the list of block dictionaries >>> imgblocks = [b for b in blocks if b["type"] == 1] >>> pprint(imgblocks[0]) {'bbox': (100.0, 135.8769989013672, 300.0, 364.1230163574219), 'bpc': 8, 'colorspace': 3, 'ext': 'jpeg', 'height': 501, 'image': b'\xff\xd8\xff\xe0\x00\x10JFIF\...', # CAUTION: LARGE! 'size': 80518, 'transform': (200.0, 0.0, -0.0, 228.2460174560547, 100.0, 135.8769989013672), 'type': 1, 'width': 439, 'xres': 96, 'yres': 96}
이미지 추출 방법: PDF 문서¶
PDF의 다른 “객체”와 마찬가지로, 이미지는 교차 참조 번호(xref, 정수)로 식별됩니다. 이 번호를 알고 있으면 이미지 데이터에 액세스하는 두 가지 방법이 있습니다:
pix = pymupdf.Pixmap(doc, xref) 지시로 이미지의 Pixmap 을 생성 합니다. 이 방법은 매우 빠릅니다(한 자리 마이크로초). 픽스맵의 속성(너비, 높이 등)은 이미지의 속성을 반영합니다. 이 경우 임베드된 원본의 이미지 형식을 알 수 있는 방법이 없습니다.
img = doc.extract_image(xref) 로 이미지를 추출 합니다. 이것은 img[“image”] 로 바이너리 이미지 데이터를 포함하는 딕셔너리입니다. 많은 메타데이터도 제공됩니다 – 대부분 이미지의 픽스맵에서 찾을 수 있는 것과 동일합니다. 주요 차이점은 이미지 형식을 지정하는 문자열 img[“ext”] 입니다: “png” 외에도 “jpeg”, “bmp”, “tiff” 등의 문자열이 나타날 수 있습니다. 디스크에 저장하려면 이 문자열을 파일 확장자로 사용하세요. 이 방법의 실행 속도는 pix = pymupdf.Pixmap(doc, xref);pix.tobytes() 문의 결합 속도와 비교해야 합니다. 임베드된 이미지가 PNG 형식인 경우,
Document.extract_image()의 속도는 거의 동일합니다(바이너리 이미지 데이터도 동일). 그렇지 않으면 이 방법이 수천 배 더 빠르고, 이미지 데이터가 훨씬 작습니다.
질문은 남아 있습니다: “이미지의 ‘xref’ 번호를 어떻게 알 수 있나요?”. 이에 대한 두 가지 답변이 있습니다:
“페이지 객체 검사:”
Page.get_images()의 항목을 반복합니다. 이것은 리스트의 리스트이며, 항목은 [xref, smask, …] 와 같이 보이며 이미지의xref를 포함합니다. 그런 다음 이xref를 위의 방법 중 하나와 함께 사용할 수 있습니다. 유효한(손상되지 않은) 문서에 이 방법을 사용하세요. 그러나 동일한 이미지가 여러 번 참조될 수 있으므로(다른 페이지에서) 여러 번 추출을 피하는 메커니즘을 제공하는 것이 좋습니다.“알 필요 없음:” 문서의 모든 xref 목록을 반복하고 각각에 대해
Document.extract_image()를 수행합니다. 반환된 딕셔너리가 비어 있으면 계속합니다 – 이xref는 이미지가 아닙니다. PDF가 손상된(사용 불가능한 페이지) 경우 이 방법을 사용하세요. PDF에는 종종 다른 이미지의 투명도를 정의하는 특수 목적의 “의사 이미지”(“스텐실 마스크”)가 포함되어 있습니다. 추출에서 이를 제외하는 로직을 제공하는 것이 좋습니다. 다음 섹션도 살펴보세요.
두 추출 방법 모두에 대해 즉시 사용 가능한 범용 스크립트가 있습니다:
extract-from-pages.py 는 페이지별로 이미지를 추출합니다:
그리고 extract-from-xref.py 는 xref 테이블로 이미지를 추출합니다:
이미지 마스크 처리 방법¶
PDF의 일부 이미지에는 이미지 마스크 가 함께 제공됩니다. 가장 간단한 형태에서 마스크는 별도의 이미지로 저장된 알파(투명도) 바이트를 나타냅니다. 마스크가 있는 이미지의 원본을 재구성하려면 마스크에서 가져온 투명도 바이트로 “보강”해야 합니다.
이미지에 그러한 마스크가 있는지는 PyMuPDF에서 두 가지 방법 중 하나로 인식할 수 있습니다:
Document.get_page_images()의 항목은 일반 형식(xref, smask, ...)을 가지며, 여기서xref는 이미지의xref이고 smask 가 양수이면 마스크의xref입니다.Document.extract_image()의 (딕셔너리) 결과에는 “smask” 키가 있으며, 양수이면 마스크의xref도 포함합니다.
smask == 0 이면 xref 를 통해 발견된 이미지는 그대로 처리할 수 있습니다.
PyMuPDF를 사용하여 원본 이미지를 복구하려면 다음에 설명된 절차를 실행해야 합니다:
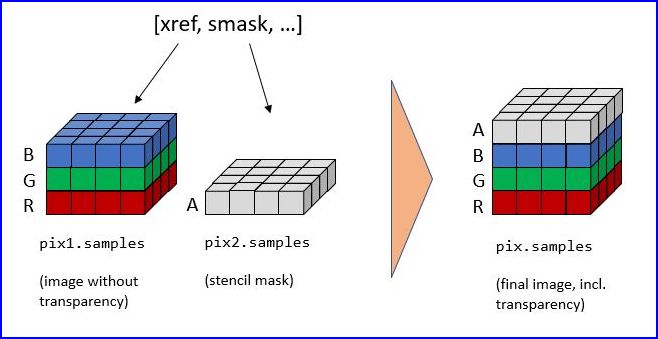
>>> pix1 = pymupdf.Pixmap(doc.extract_image(xref)["image"]) # (1) pixmap of image w/o alpha
>>> mask = pymupdf.Pixmap(doc.extract_image(smask)["image"]) # (2) mask pixmap
>>> pix = pymupdf.Pixmap(pix1, mask) # (3) copy of pix1, image mask added
단계 (1)은 기본 이미지의 픽스맵을 생성합니다. 단계 (2)는 이미지 마스크에 대해 동일한 작업을 수행합니다. 단계 (3)는 알파 채널을 추가하고 투명도 정보로 채웁니다.
위의 extract-from-pages.py 및 extract-from-xref.py 스크립트에도 이 로직이 포함되어 있습니다.
모든 사진(또는 파일)을 하나의 PDF로 만드는 방법¶
여기서는 (이미지 및 기타) 파일 목록을 받아 모두 하나의 PDF에 넣는 세 가지 스크립트 를 보여줍니다.
방법 1: 이미지를 페이지로 삽입
첫 번째는 각 이미지를 동일한 크기의 PDF 페이지로 변환합니다. 결과는 이미지당 한 페이지의 PDF가 됩니다. 지원되는 이미지 파일 형식에서만 작동합니다:
import os, pymupdf
import PySimpleGUI as psg # for showing a progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where the pics are
imglist = os.listdir(imgdir) # list of them
imgcount = len(imglist) # pic count
for i, f in enumerate(imglist):
img = pymupdf.open(os.path.join(imgdir, f)) # open pic as document
rect = img[0].rect # pic dimension
pdfbytes = img.convert_to_pdf() # make a PDF stream
img.close() # no longer needed
imgPDF = pymupdf.open("pdf", pdfbytes) # open stream as PDF
page = doc.new_page(width = rect.width, # new page with ...
height = rect.height) # pic dimension
page.show_pdf_page(rect, imgPDF, 0) # image fills the page
psg.EasyProgressMeter("Import Images", # show our progress
i+1, imgcount)
doc.save("all-my-pics.pdf")
이것은 결합된 그림 크기보다 약간만 큰 PDF를 생성합니다. 성능에 대한 일부 수치:
위 스크립트는 총 크기가 514 MB인 149개의 그림에 대해 내 컴퓨터에서 약 1분이 걸렸습니다(결과 PDF 크기도 거의 동일).
더 완전한 소스 코드는 여기 를 참조하세요: 디렉토리 선택 대화 상자를 제공하고 지원되지 않는 파일과 비파일 항목을 건너뜁니다.
참고
Page.show_pdf_page() 대신 Page.insert_image() 를 사용했을 수도 있으며, 결과는 비슷해 보이는 파일이었을 것입니다. 그러나 이미지 유형에 따라 이미지를 압축하지 않고 저장할 수 있습니다. 따라서 합리적인 파일 크기를 달성하려면 저장 옵션 deflate = True 를 사용해야 하며, 이는 많은 수의 이미지에 대해 실행 시간을 크게 증가시킵니다. 따라서 이 대안은 여기서 권장할 수 없습니다.
방법 2: 파일 임베드
두 번째 스크립트는 이미지뿐만 아니라 임의의 파일을 임베드 합니다. 결과 PDF는 기술적 이유로 하나의(빈) 페이지만 있습니다. 나중에 임베드된 파일에 다시 액세스하려면 임베드된 파일을 표시하고/또는 추출할 수 있는 적절한 PDF 뷰어가 필요합니다:
import os, pymupdf
import PySimpleGUI as psg # for showing progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where my files are
imglist = os.listdir(imgdir) # list of pictures
imgcount = len(imglist) # pic count
imglist.sort() # nicely sort them
for i, f in enumerate(imglist):
img = open(os.path.join(imgdir,f), "rb").read() # make pic stream
doc.embfile_add(img, f, filename=f, # and embed it
ufilename=f, desc=f)
psg.EasyProgressMeter("Embedding Files", # show our progress
i+1, imgcount)
page = doc.new_page() # at least 1 page is needed
doc.save("all-my-pics-embedded.pdf")
이것은 지금까지 가장 빠른 방법이며 가능한 가장 작은 출력 파일 크기도 생성합니다. 위의 그림은 내 컴퓨터에서 20초가 걸렸고 510 MB 크기의 PDF를 생성했습니다. 더 완전한 소스 코드는 여기 를 참조하세요: 디렉토리 선택 대화 상자를 제공하고 비파일 항목을 건너뜁니다.
방법 3: 파일 첨부
이 작업을 달성하는 세 번째 방법은 페이지 주석을 통해 파일을 첨부 하는 것입니다. 전체 소스 코드는 여기 를 참조하세요.
이것은 이전 스크립트와 유사한 성능을 가지며 유사한 파일 크기도 생성합니다. 각 첨부 파일에 대해 ‘FileAttachment’ 아이콘을 표시하는 PDF 페이지를 생성합니다.
참고
임베드 와 첨부 방법 모두 이미지뿐만 아니라 임의의 파일 에 사용할 수 있습니다.
참고
장시간 실행될 수 있는 작업에 대해 진행 표시기를 표시하려면 PySimpleGUI 패키지 사용을 강력히 권장합니다. 순수 Python이며 Tkinter를 사용합니다(추가 GUI 패키지 없음) 그리고 코드 한 줄만 더 필요합니다!
벡터 이미지 생성 방법¶
문서 페이지에서 이미지를 만드는 일반적인 방법은 Page.get_pixmap() 입니다. 픽스맵은 래스터 이미지를 나타내므로 생성 시 품질(즉, 해상도)을 결정해야 합니다. 나중에 변경할 수 없습니다.
PyMuPDF는 또한 SVG 형식(확장 가능한 벡터 그래픽, XML 구문으로 정의됨)으로 페이지의 벡터 이미지 를 만드는 방법을 제공합니다. SVG 이미지는 확대/축소 수준에서 정확성을 유지합니다(물론 그 안에 임베드된 래스터 그래픽 요소는 제외).
지시 svg = page.get_svg_image(matrix=pymupdf.Identity) 는 확장자 “.svg” 로 저장할 수 있는 UTF-8 문자열 svg 를 제공합니다.
이미지 변환 방법¶
다른 기능과 마찬가지로 PyMuPDF의 이미지 변환은 쉽습니다. 많은 경우 PIL/Pillow와 같은 다른 그래픽 패키지를 사용하지 않아도 될 수 있습니다.
그럼에도 불구하고 Pillow와의 인터페이싱은 거의 사소합니다.
입력 형식 |
출력 형식 |
설명 |
|---|---|---|
BMP |
. |
Windows Bitmap |
JPEG |
JPEG |
Joint Photographic Experts Group |
JXR |
. |
JPEG Extended Range |
JPX/JP2 |
. |
JPEG 2000 |
GIF |
. |
Graphics Interchange Format |
TIFF |
. |
Tagged Image File Format |
PNG |
PNG |
Portable Network Graphics |
PNM |
PNM |
Portable Anymap |
PGM |
PGM |
Portable Graymap |
PBM |
PBM |
Portable Bitmap |
PPM |
PPM |
Portable Pixmap |
PAM |
PAM |
Portable Arbitrary Map |
. |
PSD |
Adobe Photoshop Document |
. |
PS |
Adobe Postscript |
일반적인 방식은 다음 두 줄입니다:
pix = pymupdf.Pixmap("input.xxx") # any supported input format
pix.save("output.yyy") # any supported output format
비고
pymupdf.Pixmap(arg) 의 입력 인수는 이미지를 포함하는 파일 또는 bytes / io.BytesIO 객체일 수 있습니다.
출력 파일 대신 pix.tobytes(“yyy”) 를 통해 bytes 객체를 생성하고 이를 전달할 수도 있습니다.
당연히 입력 및 출력 형식은 색 공간 및 투명도 측면에서 호환되어야 합니다.
Pixmap클래스는 조정이 필요한 경우 내장 기능을 포함하고 있습니다.
참고
JPEG를 Photoshop으로 변환:
pix = pymupdf.Pixmap("myfamily.jpg")
pix.save("myfamily.psd")
참고
JPEG를 Tkinter PhotoImage로 변환 합니다. 모든 RGB / 알파 없음 이미지도 정확히 동일하게 작동합니다. Portable Anymap 형식(PPM, PGM 등) 중 하나로 변환하면 효과가 있습니다. 모든 Tkinter 버전에서 지원되기 때문입니다:
import tkinter as tk
pix = pymupdf.Pixmap("input.jpg") # or any RGB / no-alpha image
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
참고
알파가 있는 PNG 를 Tkinter PhotoImage로 변환합니다. PPM 변환을 수행하기 전에 알파 바이트를 제거 해야 합니다:
import tkinter as tk
pix = pymupdf.Pixmap("input.png") # may have an alpha channel
if pix.alpha: # we have an alpha channel!
pix = pymupdf.Pixmap(pix, 0) # remove it
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
픽스맵 사용 방법: 이미지 붙이기¶
이것은 픽스맵이 순수하게 그래픽적이고 문서가 아닌 목적으로 사용될 수 있는 방법을 보여줍니다. 스크립트는 이미지 파일을 읽고 원본의 3 * 4 타일로 구성된 새 이미지를 생성합니다:
import pymupdf
src = pymupdf.Pixmap("img-7edges.png") # create pixmap from a picture
col = 3 # tiles per row
lin = 4 # tiles per column
tar_w = src.width * col # width of target
tar_h = src.height * lin # height of target
# create target pixmap
tar_pix = pymupdf.Pixmap(src.colorspace, (0, 0, tar_w, tar_h), src.alpha)
# now fill target with the tiles
for i in range(col):
for j in range(lin):
src.set_origin(src.width * i, src.height * j)
tar_pix.copy(src, src.irect) # copy input to new loc
tar_pix.save("tar.png")
이것이 입력 그림입니다:

출력은 다음과 같습니다:

픽스맵 사용 방법: 프랙탈 만들기¶
다음은 시에르핀스키 카펫 을 생성하는 또 다른 픽스맵 예제입니다 – 칸토어 집합 을 2차원으로 일반화한 프랙탈입니다. 정사각형 카펫이 주어지면 9개의 하위 사각형(3 x 3)을 표시하고 중앙의 것을 잘라냅니다. 나머지 8개의 하위 사각형 각각에 대해 동일한 방식으로 처리하고 무한히 계속합니다. 최종 결과는 면적이 0이고 프랙탈 차원이 1.8928…인 집합입니다.
이 스크립트는 1픽셀 단위까지 내려가서 PNG로 근사 이미지를 생성합니다. 이미지 정밀도를 높이려면 n(정밀도) 값을 변경하세요:
import pymupdf, time
if not list(map(int, pymupdf.VersionBind.split("."))) >= [1, 14, 8]:
raise SystemExit("need PyMuPDF v1.14.8 for this script")
n = 6 # depth (precision)
d = 3**n # edge length
t0 = time.perf_counter()
ir = (0, 0, d, d) # the pixmap rectangle
pm = pymupdf.Pixmap(pymupdf.csRGB, ir, False)
pm.set_rect(pm.irect, (255,255,0)) # fill it with some background color
color = (0, 0, 255) # color to fill the punch holes
# alternatively, define a 'fill' pixmap for the punch holes
# this could be anything, e.g. some photo image ...
fill = pymupdf.Pixmap(pymupdf.csRGB, ir, False) # same size as 'pm'
fill.set_rect(fill.irect, (0, 255, 255)) # put some color in
def punch(x, y, step):
"""Recursively "punch a hole" in the central square of a pixmap.
Arguments are top-left coords and the step width.
Some alternative punching methods are commented out.
"""
s = step // 3 # the new step
# iterate through the 9 sub-squares
# the central one will be filled with the color
for i in range(3):
for j in range(3):
if i != j or i != 1: # this is not the central cube
if s >= 3: # recursing needed?
punch(x+i*s, y+j*s, s) # recurse
else: # punching alternatives are:
pm.set_rect((x+s, y+s, x+2*s, y+2*s), color) # fill with a color
#pm.copy(fill, (x+s, y+s, x+2*s, y+2*s)) # copy from fill
#pm.invert_irect((x+s, y+s, x+2*s, y+2*s)) # invert colors
return
#==============================================================================
# main program
#==============================================================================
# now start punching holes into the pixmap
punch(0, 0, d)
t1 = time.perf_counter()
pm.save("sierpinski-punch.png")
t2 = time.perf_counter()
print (f"{round(t1-t0,3)} sec to create / fill the pixmap")
print (f"{round(t2-t1,3)} sec to save the image")
결과는 다음과 같아야 합니다:

NumPy와 인터페이스하는 방법¶
이것은 numpy 배열에서 PNG 파일을 만드는 방법을 보여줍니다(대부분의 다른 방법보다 몇 배 빠름):
import numpy as np
import pymupdf
#==============================================================================
# create a fun-colored width * height PNG with pymupdf and numpy
#==============================================================================
height = 150
width = 100
bild = np.ndarray((height, width, 3), dtype=np.uint8)
for i in range(height):
for j in range(width):
# one pixel (some fun coloring)
bild[i, j] = [(i+j)%256, i%256, j%256]
samples = bytearray(bild.tostring()) # get plain pixel data from numpy array
pix = pymupdf.Pixmap(pymupdf.csRGB, width, height, samples, alpha=False)
pix.save("test.png")
PDF 페이지에 이미지 추가 방법¶
PDF 페이지에 이미지를 추가하는 두 가지 방법이 있습니다: Page.insert_image() 와 Page.show_pdf_page(). 두 방법 모두 공통점이 있지만 차이점도 있습니다.
기준 |
||
|---|---|---|
표시 가능한 콘텐츠 |
이미지 파일, 메모리의 이미지, 픽스맵 |
PDF 페이지 |
표시 해상도 |
이미지 해상도 |
벡터화됨(래스터 페이지 콘텐츠 제외) |
회전 |
0, 90, 180 또는 270도 |
임의의 각도 |
클리핑 |
아니오(전체 이미지만) |
예 |
종횡비 유지 |
예(기본 옵션) |
예(기본 옵션) |
투명도(워터마킹) |
이미지에 따라 다름 |
페이지에 따라 다름 |
위치 / 배치 |
대상 사각형에 맞게 크기 조정 |
대상 사각형에 맞게 크기 조정 |
성능 |
중복 자동 방지; |
중복 자동 방지; |
다중 페이지 이미지 지원 |
아니오 |
예 |
사용 편의성 |
간단하고 직관적; |
간단하고 직관적; |
Page.insert_image() 의 기본 코드 패턴. 기존 이미지를 다시 삽입하지 않는 경우 filename / stream / pixmap 매개변수 중 정확히 하나 를 제공해야 합니다:
page.insert_image(
rect, # where to place the image (rect-like)
filename=None, # image in a file
stream=None, # image in memory (bytes)
pixmap=None, # image from pixmap
mask=None, # specify alpha channel separately
rotate=0, # rotate (int, multiple of 90)
xref=0, # re-use existing image
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
Page.show_pdf_page() 의 기본 코드 패턴. 소스 및 대상 PDF는 서로 다른 Document 객체여야 합니다(같은 파일에서 열 수 있음):
page.show_pdf_page(
rect, # where to place the image (rect-like)
src, # source PDF
pno=0, # page number in source PDF
clip=None, # only display this area (rect-like)
rotate=0, # rotate (float, any value)
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
픽스맵 사용 방법: 텍스트 가시성 확인¶
주어진 텍스트가 페이지에서 실제로 보이는지는 여러 요인에 따라 다릅니다:
텍스트가 다른 객체에 의해 덮이지 않았지만 배경과 같은 색상일 수 있습니다. 예: 흰색 위의 흰색 등.
텍스트가 이미지나 벡터 그래픽에 의해 덮일 수 있습니다. 이를 감지하는 것은 중요한 기능입니다. 예를 들어 잘못 익명화된 법률 문서를 발견하는 데 사용됩니다.
텍스트가 숨겨진 상태로 생성됩니다. 이 기술은 일반적으로 OCR 도구가 인식된 텍스트를 페이지의 보이지 않는 레이어에 저장하는 데 사용됩니다.
다음은 위의 상황 1을 감지하는 방법 또는 덮는 객체가 단색인 경우 상황 2를 감지하는 방법을 보여줍니다:
pix = page.get_pixmap(dpi=150) # make page image with a decent resolution
# the following matrix transforms page to pixmap coordinates
mat = page.rect.torect(pix.irect)
# search for some string "needle"
rlist = page.search_for("needle")
# check the visibility for each hit rectangle
for rect in rlist:
if pix.color_topusage(clip=rect * mat)[0] > 0.95:
print("'needle' is invisible here:", rect)
Pixmap.color_topusage() 메서드는 (ratio, pixel) 튜플을 반환합니다. 여기서 0 < ratio <= 1이고 pixel 은 색상의 픽셀 값입니다. 픽스맵을 한 번만 생성 합니다. 여러 히트 사각형이 있는 경우 처리 시간을 많이 절약할 수 있습니다.
위 코드의 로직은 다음과 같습니다: 바늘이 가리키는 사각형이 (“거의”: > 95%) 단색이면 텍스트가 보일 수 없습니다. 보이는 텍스트의 일반적인 결과는 배경 색상(대부분 흰색)과 약 0.7~0.8의 비율을 반환합니다. 예: (0.685, b'xffxffxff').