TextPage¶
이 클래스는 문서 페이지에 표시된 텍스트와 이미지를 나타냅니다. 모든 MuPDF 문서 타입 이 지원됩니다.
텍스트 페이지를 생성하는 일반적인 방법은 DisplayList.get_textpage() 와 Page.get_textpage() 입니다. 이 클래스의 메서드 세트가 제한적이므로, 더 편리하게 사용할 수 있는 Page 에 래퍼가 존재합니다. 이 테이블의 마지막 열은 이러한 해당 Page 메서드를 보여줍니다.
이 클래스에 대한 설명은 부록 2를 참조하세요.
메서드 |
설명 |
페이지 get_text 또는 search 메서드 |
|---|---|---|
일반 텍스트 추출 |
“text” |
|
이전의 동의어 |
“text” |
|
블록으로 그룹화된 일반 텍스트 |
“blocks” |
|
바운딩 박스를 포함한 모든 단어 |
“words” |
|
HTML 형식의 페이지 콘텐츠 |
“html” |
|
XHTML 형식의 페이지 콘텐츠 |
“xhtml” |
|
XML 형식의 페이지 텍스트 |
“xml” |
|
dict 형식의 페이지 콘텐츠 |
“dict” |
|
JSON 형식의 페이지 콘텐츠 |
“json” |
|
dict 형식의 페이지 콘텐츠 |
“rawdict” |
|
JSON 형식의 페이지 콘텐츠 |
“rawjson” |
|
페이지에서 문자열 검색 |
클래스 API
- class TextPage¶
- extractText(sort=False)¶
- extractTEXT(sort=False)¶
페이지의 전체 텍스트 문자열을 반환합니다. 텍스트는 UTF-8 유니코드이며 문서 생성 시 지정된 순서와 동일합니다.
- 매개변수:
sort (bool) – (v1.19.1에서 새로 추가됨) 출력을 수직 좌표, 그 다음 수평 좌표로 정렬합니다. 많은 경우 이것으로 “자연스러운” 읽기 순서를 생성할 수 있습니다.
- 반환 형식:
str
- extractBLOCKS()¶
블록별로 그룹화된 텍스트 줄 목록으로 된 텍스트 페이지 콘텐츠. 각 목록 항목은 다음과 같습니다:
``(x0, y0, x1, y1, "lines in the block", block_no, block_type)``
The first four entries are the block’s bbox coordinates, block_type is 1 for an image block, 3 for a vector block, and 0 for text. block_no is the block sequence number. Multiple text lines are joined via line breaks.
For an image block, its bbox and a text line with some image meta information is included – not the image content. Image blocks are included only if the extraction flag bit
TEXT_PRESERVE_IMAGESis set. An image block tuple will look like this:``(x0, y0, x1, y1, "<image: colorspace-name, w: width, h: height, bpc: bits_per_component>\n", block_no, 1)``
For a vector block, the following item will be included. Vector blocks are included only if the extraction flag bit
TEXT_COLLECT_VECTORSis set. A vector block tuple will look like this:``(x0, y0, x1, y1, "<vector stroked, color: #rrggbb, alpha: 255, is-rect: true, continues: false>\n", block_no, 3)``
The keyword “vector” is followed by either “stroked” or “filled”. The color is given in HTML (hexadecimal RGB) format. Property
is-rectis true, if the vector is not a curve and parallel to the x- or y-axis. So in essence is either a real rectangle or a line segment. Propertycontinuesindicates whether the vector is part of a path (and not the first item).참고
When no further details are needed (as provided by
Page.get_drawings()), then this is an inexpensive way to extract basic vector graphics information. Another major advantage is that all block types (text, images and vectors) are included in the output in the same order as they are present in the page’scontentsstream.원하는 읽기 순서로 일반 텍스트를 출력하기에 충분한 정보를 제공하는 고속 메서드입니다.
- 반환 형식:
list
- extractWORDS(delimiters=None)¶
v1.23.5에서 변경됨:
delimiters매개변수 추가
bbox 정보가 있는 단일 단어 목록으로 된 텍스트 페이지 콘텐츠. 이 목록의 항목은 다음과 같습니다:
(x0, y0, x1, y1, "word", block_no, line_no, word_no)
- 매개변수:
delimiters (str) – (v1.23.5에서 새로 추가됨) 이러한 문자를 추가 단어 구분자로 사용합니다. 기본적으로 모든 공백(줄바꿈 없는 공백
0xA0포함)은 단어의 시작과 끝을 나타냅니다. 이제 이를 유발하는 더 많은 문자를 지정할 수 있습니다. 예를 들어 기본값은"john.doe@outlook.com"을 하나의 단어로 반환합니다.delimiters="@."를 지정하면 네 개의 단어"john","doe","outlook","com"이 반환됩니다. 다른 가능한 용도로는 구두점 문자 무시delimiters=string.punctuation가 있습니다. “word” 문자열에는 구분 문자가 포함되지 않습니다.
이것은 예를 들어 주어진 영역 내에서 텍스트를 추출하거나 텍스트 읽기 순서를 복구할 수 있게 하는 고속 메서드입니다.
- 반환 형식:
list
- extractHTML()¶
HTML 형식의 문자열로 된 텍스트 페이지 콘텐츠. 이 버전은 완전한 서식 및 위치 정보를 포함합니다. 이미지가 포함됩니다(base64 문자열로 인코딩됨). Python에서 출력을 해석하려면 HTML 패키지가 필요합니다. 인터넷 브라우저가 이 정보를 적절히 표시할 수 있어야 하지만 HTML 출력 품질 제어 를 참조하세요.
- 반환 형식:
str
- extractDICT(sort=False)¶
Python 딕셔너리로 된 텍스트 페이지 콘텐츠. HTML과 동일한 정보 세부 사항을 제공합니다. 구조는 아래를 참조하세요.
- 매개변수:
sort (bool) – (v1.19.1에서 새로 추가됨) 출력을 수직 좌표, 그 다음 수평 좌표로 정렬합니다. 많은 경우 이것으로 “자연스러운” 읽기 순서를 생성할 수 있습니다.
- 반환 형식:
dict
- extractJSON(sort=False)¶
JSON 문자열로 된 텍스트 페이지 콘텐츠.
json.dumps(TextPage.extractDICT())로 생성됩니다. 하위 호환성을 위해 포함되었습니다. 이 메서드는 아마도 결과를 파일로 출력하는 용도로만 사용할 것입니다. 이 메서드는 바이너리 이미지 데이터를 감지하고 base64 인코딩된 문자열로 변환합니다.- 매개변수:
sort (bool) – (v1.19.1에서 새로 추가됨) 출력을 수직 좌표, 그 다음 수평 좌표로 정렬합니다. 많은 경우 이것으로 “자연스러운” 읽기 순서를 생성할 수 있습니다.
- 반환 형식:
str
- extractXHTML()¶
XHTML 형식의 문자열로 된 텍스트 페이지 콘텐츠. 텍스트 정보 세부 사항은
extractTEXT()와 유사하지만 이미지도 포함합니다(base64 인코딩됨). 이 메서드는 원본 시각적 모양을 재현하려고 시도하지 않습니다.- 반환 형식:
str
- extractXML()¶
XML 형식의 문자열로 된 텍스트 페이지 콘텐츠. 이것은 페이지의 모든 단일 문자에 대한 완전한 서식 정보를 포함합니다: 글꼴, 크기, 줄, 단락, 위치, 색상 등. 이미지는 포함되지 않습니다. Python에서 출력을 해석하려면 XML 패키지가 필요합니다.
- 반환 형식:
str
- extractRAWDICT(sort=False)¶
Python 딕셔너리로 된 텍스트 페이지 콘텐츠. 기술적으로
extractDICT()와 유사하며, 해당 정보를 하위 집합으로 포함합니다(이미지 포함). 각 문자까지 추가 세부 정보를 제공하므로 많은 경우 XML 사용을 불필요하게 만듭니다. 구조는 아래를 참조하세요.- 매개변수:
sort (bool) – (v1.19.1에서 새로 추가됨) 출력을 수직 좌표, 그 다음 수평 좌표로 정렬합니다. 많은 경우 이것으로 “자연스러운” 읽기 순서를 생성할 수 있습니다.
- 반환 형식:
dict
- extractRAWJSON(sort=False)¶
JSON 문자열로 된 텍스트 페이지 콘텐츠.
json.dumps(TextPage.extractRAWDICT())로 생성됩니다. 이 메서드는 아마도 결과를 파일로 출력하는 용도로만 사용할 것입니다. 이 메서드는 바이너리 이미지 데이터를 감지하고 base64 인코딩된 문자열로 변환합니다.- 매개변수:
sort (bool) – (v1.19.1에서 새로 추가됨) 출력을 수직 좌표, 그 다음 수평 좌표로 정렬합니다. 많은 경우 이것으로 “자연스러운” 읽기 순서를 생성할 수 있습니다.
- 반환 형식:
str
- search(needle, quads=False)¶
v1.18.2에서 변경됨
string 을 검색하고 찾은 위치 목록을 반환합니다.
- 매개변수:
needle (str) – 검색할 문자열. needle이 ASCII 문자로만 구성된 경우 대소문자가 모두 일치합니다. “Ä” 와 “ä” 등에는 아직 작동하지 않습니다.
quads (bool) – 사각형 대신 사각형을 반환합니다.
- 반환 형식:
list
- 반환:
Rect 또는 Quad 객체 목록으로, 각각 찾은 needle 발생을 둘러쌉니다. 검색 문자열에 공백이 포함될 수 있으므로 해당 부분이 다른 줄에서 발견될 수 있습니다. 이 경우 둘 이상의 사각형(또는 사각형)이 반환됩니다. (v1.18.2에서 변경됨) 이 메서드는 이제 하이픈 제거를 지원 하므로 두 줄에 걸쳐 “meth-” 와 “od” 로 하이픈 처리된 경우에도 예를 들어 “method” 를 찾을 수 있습니다. 반환된 두 사각형에는 “meth” (하이픈 없음)와 “od” 가 포함됩니다.
참고
v1.18.2의 변경 사항 개요:
hit_max매개변수가 제거되었습니다. 모든 히트가 항상 반환됩니다.TextPage 의 Rect 매개변수가 이제 존중됩니다. 이 영역 내의 텍스트만 검사됩니다. 완전히 포함된 bbox를 가진 문자만 고려됩니다. 래퍼 메서드
Page.search_for()는 이에 따라 clip 매개변수를 지원합니다.하이픈 처리된 단어 가 이제 찾아집니다.
같은 줄의 겹치는 사각형 이 이제 자동으로 결합됩니다. 이러한 분리는 동일한 검색 needle의 일부를 포함하는 여러 표시된 콘텐츠 그룹에 의해 생성된 아티팩트라고 가정합니다.
Quad 대 Rect 예시: needle “pymupdf” 를 검색할 때 해당 항목은 파란색 사각형이 되거나, quads 가 지정된 경우 사각형 Quad(ul, ur, ll, lr) 가 됩니다.

- rect¶
텍스트 페이지와 연결된 사각형. 이것은 생성 페이지의 사각형이거나
Page.get_textpage()및 텍스트 추출/검색 메서드의clip매개변수와 같습니다.참고
텍스트 검색 및 대부분의 텍스트 추출 출력은 이 사각형으로 제한됩니다. 그러나 (X)HTML 및 XML 출력은 항상 전체 페이지를 추출합니다.
딕셔너리 출력 구조¶
TextPage.extractDICT(), TextPage.extractJSON(), TextPage.extractRAWDICT(), TextPage.extractRAWJSON() 메서드는 페이지의 텍스트 및 이미지 콘텐츠를 포함하는 딕셔너리를 반환합니다. 네 가지 메서드의 딕셔너리 구조는 거의 동일합니다. 각각을 자체 하위 딕셔너리로 표현하여 텍스트 페이지의 블록, 줄, 범위 및 문자 정보 계층을 가능한 한 정확하게 매핑합니다:
페이지 는 블록 딕셔너리 목록으로 구성됩니다.
(텍스트) 블록 은 줄 딕셔너리 목록으로 구성됩니다.
줄 은 범위 딕셔너리 목록으로 구성됩니다.
범위 는 텍스트 자체로 구성되거나 RAW 변형의 경우 문자 딕셔너리 목록으로 구성됩니다.
RAW 변형: 문자 는 원본, bbox 및 유니코드의 딕셔너리입니다.
여기에 포함된 모든 PyMuPDF 기하 객체(점, 사각형, 행렬)는 “like” 형식으로 표현됩니다: Rect 대신 rect_like tuple 이 사용됩니다. 그 이유는 성능 및 메모리 고려 사항입니다:
이 코드는 C로 작성되었으며, Python 튜플을 쉽게 생성할 수 있습니다. 반면 기하 객체는 Python 소스에만 정의되어 있습니다. 각 Python 튜플을 해당 기하 객체로 변환하면 상당한 실행 시간이 추가됩니다(대부분 불필요함).
4-tuple은 약 168바이트가 필요하고, 해당 Rect 는 472바이트입니다. 거의 3배 크기입니다. 텍스트가 많은 페이지의 “dict” 딕셔너리에는 300개 이상의 bbox 객체가 포함되어 있습니다. 따라서 4-tuple로 약 50KB, Rect 객체로 140KB의 저장 공간이 필요합니다. 그러나 이러한 페이지의 “rawdict” 출력에는 4천~5천 개 의 bbox가 포함되므로, 이 경우 750KB 대 2MB를 말하는 것입니다.
또한 bboxes (= rect_like 4-tuple)만 반환되지만, TextPage 는 실제로 전체 위치 정보 를 가지고 있습니다. Quad 형식입니다. 이 결정의 이유는 다시 메모리 고려 사항입니다: quad_like 는 488바이트(rect_like 크기의 3배)가 필요합니다. 생성된 bbox의 양을 고려하면 quad_like 정보를 반환하면 상당한 영향을 미칩니다.
대부분의 경우 수평 텍스트만 다루며, bbox가 완전히 충분한 정보를 제공합니다.
또한 전체 quad 정보는 손실되지 않습니다: 다음 목록의 적절한 함수를 사용하여 줄, 범위 및 문자에 대해 필요에 따라 복구할 수 있습니다:
recover_quad()– 전체 범위의 quadrecover_span_quad()– 범위의 문자 하위 집합의 quadrecover_line_quad()– 줄의 quadrecover_char_quad()– 문자의 quad
언급한 대로, 이러한 함수 사용은 텍스트가 수평으로 작성되지 않은 경우(line["dir"] != (1, 0))에만 필요하며, 텍스트 마커 주석(Page.add_highlight_annot() 등)에 quad가 필요한 경우입니다.
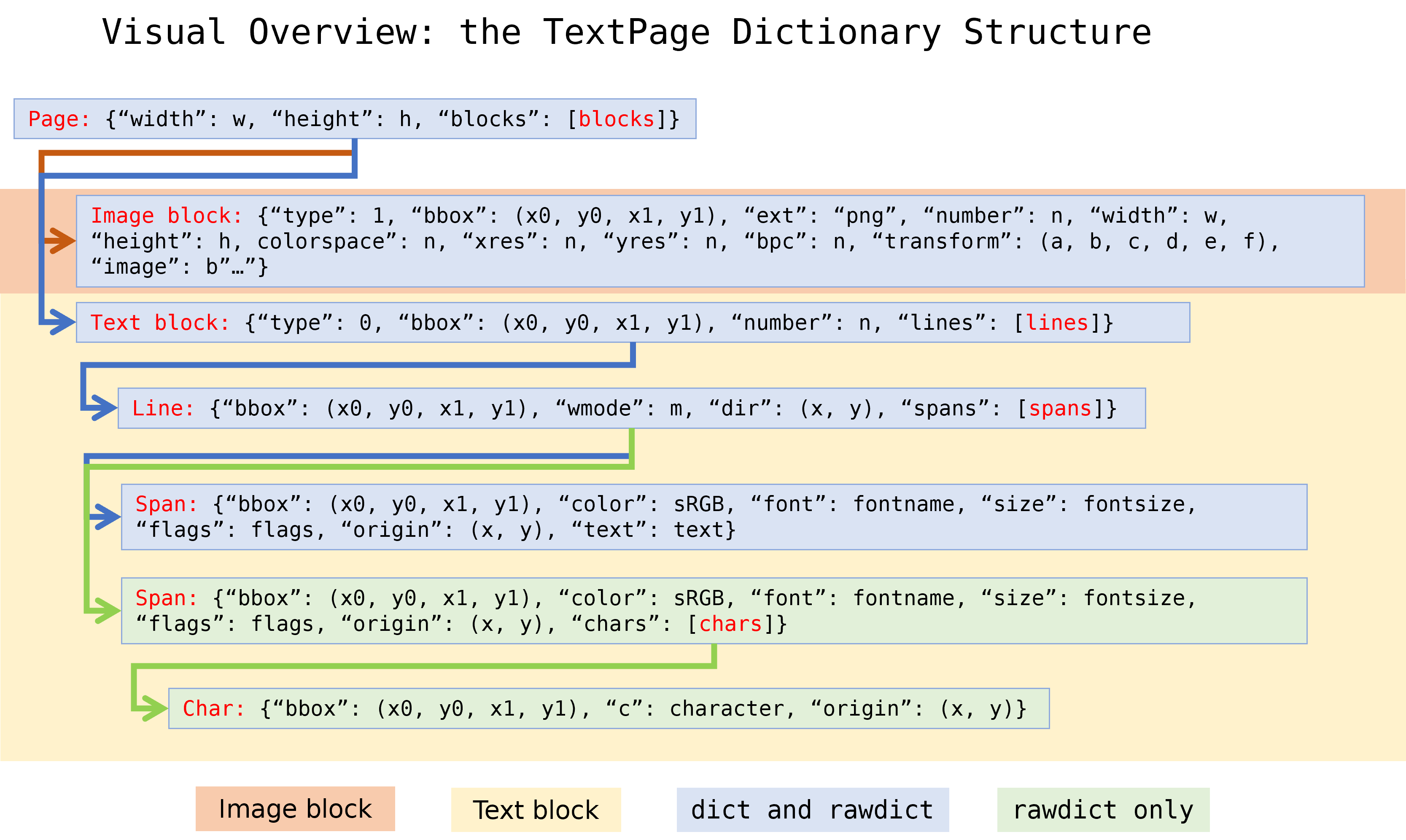
페이지 딕셔너리¶
키 |
값 |
|---|---|
width |
|
height |
|
blocks |
블록 딕셔너리의 list |
블록 딕셔너리¶
Block dictionaries come in different formats for vector blocks, image blocks and text blocks. Vector blocks are included only if the extraction flag bit TEXT_COLLECT_VECTORS is set. Image blocks are included only if the extraction flag bit TEXT_PRESERVE_IMAGES is set.
Vector block:
키 |
값 |
|---|---|
type |
3 = vector ( |
bbox |
vector bbox on page ( |
number |
블록 개수 ( |
stroked |
either stroked ( |
isrect |
whether the vector is axis-parallel ( |
continues |
whether the vector is (not the last) part of a sequence of vectors in a path ( |
color |
sRGB integer, e.g. 0xRRGGBB ( |
alpha |
Transparency, a value in |
This information is a true subset of the output of Page.get_drawings(). Its advantage is its speed (because it is extracted alongside one TextPage creation) and the fact that vector blocks are included in the overall page content sequence together with text and images.
이미지 블록:
키 |
값 |
|---|---|
type |
1 = 이미지 ( |
bbox |
페이지의 이미지 bbox ( |
number |
블록 개수 ( |
ext |
이미지 타입 ( |
width |
원본 이미지 너비 ( |
height |
원본 이미지 높이 ( |
colorspace |
색 공간 구성 요소 개수 ( |
xres |
x 방향 해상도 ( |
yres |
y 방향 해상도 ( |
bpc |
구성 요소당 비트 수 ( |
transform |
이미지 rect를 bbox로 변환하는 행렬 ( |
size |
바이트 단위의 이미지 크기 ( |
image |
이미지 콘텐츠 ( |
mask |
투명 이미지의 이미지 마스크 콘텐츠 ( |
“ext” 키의 가능한 값은 “bmp”, “gif”, “jpeg”, “jpx” (JPEG 2000), “jxr” (JPEG XR), “png”, “pnm”, “tiff” 입니다.
참고
페이지의 모든 이미지 발생 에 대해 이미지 블록이 생성됩니다. 따라서 이미지가 다른 위치에 표시되면 중복이 있을 수 있습니다.
TextPage 및 해당 메서드
Page.get_text()는 모든 문서 타입에 사용 가능합니다. PDF 문서의 경우에만Document.get_page_images()/Page.get_images()메서드가 이미지 목록과 관련하여 일부 중복 기능을 제공합니다. 그러나 두 목록은 같은 항목을 포함할 수도 있고 포함하지 않을 수도 있습니다. 차이점은 다음 중 하나로 인한 것일 가능성이 높습니다:PDF 페이지의 “인라인” 이미지(Adobe PDF 참조 214페이지 참조)는 텍스트 페이지에 포함되지만
Page.get_images()에는 나타나지 않습니다.주석에도 이미지가 포함될 수 있습니다. 이것들은
Page.get_images()에 나타나지 않습니다.텍스트 페이지의 이미지 블록은 모든 이미지 위치에 대해 생성됩니다. 중복이 있는지 여부와 관계없이. 이것은 각 이미지를 한 번만 나열하는
Page.get_images()(참조 이름당)와 대조됩니다.페이지의
object정의에 언급된 이미지는 항상Page.get_images()[1] 에 나타납니다. 그러나 페이지의contents에 “display” 명령이 없을 수 있습니다(오류 또는 의도적으로). 이 경우 이미지는 텍스트 페이지에 나타나지 않습니다.
이미지의 “변환 행렬” 은 표현식
bbox / transform == pymupdf.Rect(0, 0, 1, 1)가 참인 행렬로 정의됩니다. 자세한 내용은 이미지 변환 행렬 을 참조하세요.투명 이미지에는 마스크 이미지가 함께 제공될 수 있습니다. 이것은 키
"mask"아래에 저장되며DeviceGrayPNG 이미지 형식을 가집니다. 그렇지 않으면 이 키의 값은None입니다. 있는 경우 “image” 및 “mask” 값에서 Pixmap 객체를 생성하고 오버레이하여 원본 이미지(즉, 투명도 포함)를 복구할 수 있습니다. 마스크 이미지는 여러 형식으로 제공되며, 모든 형식이 Pixmap 오버레이가 지원되는 조건을 충족하지는 않기 때문에 항상 작동한다고 보장할 수는 없습니다. 다음은 코드 스니펫입니다:
>>> base = pymupdf.Pixmap(block["image"])
>>> mask = pymupdf.Pixmap(block["mask"])
>>> result = pymupdf.Pixmap(base, mask)
텍스트 블록:
키 |
값 |
|---|---|
type |
0 = 텍스트 (int) |
bbox |
블록 사각형, |
number |
블록 개수 (int) |
lines |
텍스트 줄 딕셔너리의 list |
줄 딕셔너리¶
키 |
값 |
|---|---|
bbox |
줄 사각형, |
wmode |
쓰기 모드 (int): 0 = 수평, 1 = 수직 |
dir |
쓰기 방향, |
spans |
범위 딕셔너리의 list |
키 “dir” 의 값은 텍스트가 x축에 대해 가진 각도의 단위 벡터 dir = (cosine, -sine) 입니다 [2]. 다음 그림을 참조하세요: 각 사분면(오른쪽 위에서 오른쪽 아래로 반시계 방향)의 단어는 각각 30, 120, 210, 300도 회전됩니다.

범위 딕셔너리¶
범위에는 실제 텍스트가 포함됩니다. 줄은 다른 글꼴 속성을 가진 텍스트를 포함하는 경우에만 하나 이상의 범위 를 포함합니다.
버전 1.14.17에서 변경됨: 범위에 이제 bbox 키가 다시 있습니다.
버전 1.17.6에서 변경됨: 범위에 이제 origin 키가 있습니다.
키 |
값 |
|---|---|
bbox |
범위 사각형, |
origin |
첫 번째 문자의 원점, |
font |
글꼴 이름 (str) |
ascender |
글꼴의 상승부 (float) |
descender |
글꼴의 하강부 (float) |
size |
글꼴 크기 (float) |
flags |
글꼴 특성 (int) |
char_flags |
문자 특성 (int) |
color |
sRGB 형식의 텍스트 색상 0xRRGGBB (int). |
alpha |
텍스트 불투명도 0..255 (int). |
text |
( |
chars |
( |
Show/hide history
(버전 1.25.3.0에서 새로 추가됨): “alpha” 항목 추가.
(버전 1.16.0에서 새로 추가됨): “color” 는 sRGB (int) 형식으로 인코딩된 텍스트 색상입니다. 예: 빨간색의 경우 0xFF0000. 이 정수를 다시 형식으로 변환하는 함수가 있습니다: (r, g, b) (0에서 1까지의 float 값, PDF) sRGB_to_pdf(), 또는 (R, G, B) sRGB_to_rgb() (0에서 255까지의 정수 값).
(v1.18.5에서 새로 추가됨): “ascender” 와 “descender” 는 fontsize 1에 상대적인 글꼴 속성입니다. descender는 음수 값입니다. 다음 그림은 다른 값 및 속성과의 관계를 보여줍니다.

이 숫자는 문자(또는 범위)의 최소 높이를 계산하는 데 사용할 수 있습니다. “bbox” 값에 제공된 표준 높이(실제로 줄 높이 를 나타냄)와 대조됩니다. 다음 코드는 범위 bbox를 fontsize 높이로 재계산하여 내부 텍스트에 정확히 맞도록 합니다:
>>> a = span["ascender"]
>>> d = span["descender"]
>>> r = pymupdf.Rect(span["bbox"])
>>> o = pymupdf.Point(span["origin"]) # its y-value is the baseline
>>> r.y1 = o.y - span["size"] * d / (a - d)
>>> r.y0 = r.y1 - span["size"]
>>> # r now is a rectangle of height 'fontsize'
조심
위 계산은 더 큰 높이를 제공할 수 있습니다! 예를 들어 OCR된 문서에서 이런 일이 발생할 수 있으며, 모든 종류의 텍스트 아티팩트 위험이 높습니다. MuPDF 는 PDF에서 찾은 fontsize 와 독립적으로 합리적인 bbox 높이를 제시하려고 합니다. 따라서 span["bbox"] 의 높이가 span["size"] 보다 큰지 확인하세요.
참고
pymupdf.TOOLS.set_small_glyph_heights(True) 를 실행하여 PyMuPDF 가 위의 모든 작업을 자동으로 수행하도록 요청할 수 있습니다. 이것은 전역 매개변수를 설정하여 모든 후속 텍스트 검색 및 텍스트 추출이 의미 있는 경우 감소된 글리프 높이를 기반으로 하도록 합니다.
다음은 빨간색으로 표시된 원본 범위 사각형과 파란색으로 표시된 재계산된 높이의 사각형을 보여줍니다.

“flags” 는 첫 번째 비트 0을 제외한 글꼴 속성을 나타내는 정수입니다. 다음과 같이 해석됩니다:
비트 0: 위첨자 (
TEXT_FONT_SUPERSCRIPT) – 글꼴 속성이 아니며 MuPDF 코드에 의해 감지됩니다.비트 1: 기울임꼴 (
TEXT_FONT_ITALIC)비트 2: 세리프 (
TEXT_FONT_SERIFED)비트 3: 고정폭 (
TEXT_FONT_MONOSPACED)비트 4: 굵게 (
TEXT_FONT_BOLD)
다음과 같이 이러한 특성을 테스트합니다:
>>> if flags & pymupdf.TEXT_FONT_BOLD & pymupdf.TEXT_FONT_ITALIC:
print(f"{span['text']=} is bold and italic")
비트 1부터 4까지는 글꼴 속성, 즉 글꼴 프로그램에 인코딩된 것입니다. 이 정보가 반드시 정확하거나 완전하지는 않습니다. 글꼴은 여기에 잘못된 데이터를 포함하는 경우가 많습니다.
“char_flags” 는 추가 문자 속성을 나타내는 정수입니다:
비트 0: 취소선.
비트 1: 밑줄.
비트 2: 합성 (항상 0, 문자 딕셔너리 참조).
비트 3: 채움.
비트 4: 획.
비트 5: 클리핑.
예를 들어 채워지지 않고 획이 없으면 (if not (char_flags & 2**3 & 2**4): ...) 텍스트가 보이지 않습니다.
(char_flags 는 v1.25.2에서 새로 추가됨.)
extractRAWDICT() 의 문자 딕셔너리¶
키 |
값 |
|---|---|
origin |
문자의 왼쪽 기준선 점, |
bbox |
문자 사각형, |
synthetic |
bool. |
c |
문자 (유니코드) |
(synthetic 는 v1.25.3에서 새로 추가됨.)
이 이미지는 문자의 bbox와 quad 간의 관계를 보여줍니다: 
각주