부록 3: 기타 기술 정보¶
이 섹션은 서로 관련이 없을 수 있는 다양한 기술 주제를 다룹니다.
이미지 변환 행렬¶
버전 1.18.11부터 이미지 변환 행렬은 텍스트 및 이미지 추출을 위한 일부 메서드에서 반환됩니다: Page.get_text() 및 Page.get_image_bbox().
변환 행렬은 이미지가 문서 페이지의 사각형(그 “경계 상자” = “bbox”)에 맞도록 변환된 방법에 대한 정보를 포함합니다. 페이지의 이미지 bbox와 이 행렬을 검사하면 예를 들어 이미지가 페이지에서 확대/축소되거나 회전되어 표시되는지 여부와 방법을 결정할 수 있습니다.
이미지 크기와 페이지의 bbox 간의 관계는 다음과 같습니다:
- 원본 이미지의 너비와 높이를 사용하여,
이미지 사각형을 정의합니다
imgrect = pymupdf.Rect(0, 0, width, height)“축소 행렬”을 정의합니다
shrink = pymupdf.Matrix(1/width, 0, 0, 1/height, 0, 0).
이미지 사각형을 축소 행렬로 변환하면 단위 사각형이 됩니다:
imgrect * shrink = pymupdf.Rect(0, 0, 1, 1).이미지 변환 행렬 “transform”을 사용하면 다음 단계로 bbox를 계산합니다:
imgrect = pymupdf.Rect(0, 0, width, height) shrink = pymupdf.Matrix(1/width, 0, 0, 1/height, 0, 0) bbox = imgrect * shrink * transform
행렬 곱
shrink * transform을 검사하면 이미지 사각형이 페이지의 bbox에 맞도록 변환된 방법에 대한 모든 정보(회전, 변의 크기 조정 및 원점 이동)를 알 수 있습니다. 예제를 살펴보겠습니다:>>> imginfo = page.get_images()[0] # get an image item on a page >>> imginfo (5, 0, 439, 501, 8, 'DeviceRGB', '', 'fzImg0', 'DCTDecode') >>> #------------------------------------------------ >>> # define image shrink matrix and rectangle >>> #------------------------------------------------ >>> shrink = pymupdf.Matrix(1 / 439, 0, 0, 1 / 501, 0, 0) >>> imgrect = pymupdf.Rect(0, 0, 439, 501) >>> #------------------------------------------------ >>> # determine image bbox and transformation matrix: >>> #------------------------------------------------ >>> bbox, transform = page.get_image_bbox("fzImg0", transform=True) >>> #------------------------------------------------ >>> # confirm equality - permitting rounding errors >>> #------------------------------------------------ >>> bbox Rect(100.0, 112.37525939941406, 300.0, 287.624755859375) >>> imgrect * shrink * transform Rect(100.0, 112.375244140625, 300.0, 287.6247253417969) >>> #------------------------------------------------ >>> shrink * transform Matrix(0.0, -0.39920157194137573, 0.3992016017436981, 0.0, 100.0, 287.6247253417969) >>> #------------------------------------------------ >>> # the above shows: >>> # image sides are scaled by same factor ~0.4, >>> # and the image is rotated by 90 degrees clockwise >>> # compare this with pymupdf.Matrix(-90) * 0.4 >>> #------------------------------------------------
PDF Base 14 글꼴¶
다음 14개의 내장 글꼴 이름은 모든 PDF 뷰어 애플리케이션에서 지원되어야 합니다. 이들은 딕셔너리로 제공되며, 전체 이름과 소문자 약어를 전체 글꼴 기본 이름에 매핑합니다. PyMuPDF 에서 fontname 을 제공해야 하는 곳에서는 딕셔너리의 키 또는 값 을 사용할 수 있습니다:
In [2]: pymupdf.Base14_fontdict
Out[2]:
{'courier': 'Courier',
'courier-oblique': 'Courier-Oblique',
'courier-bold': 'Courier-Bold',
'courier-boldoblique': 'Courier-BoldOblique',
'helvetica': 'Helvetica',
'helvetica-oblique': 'Helvetica-Oblique',
'helvetica-bold': 'Helvetica-Bold',
'helvetica-boldoblique': 'Helvetica-BoldOblique',
'times-roman': 'Times-Roman',
'times-italic': 'Times-Italic',
'times-bold': 'Times-Bold',
'times-bolditalic': 'Times-BoldItalic',
'symbol': 'Symbol',
'zapfdingbats': 'ZapfDingbats',
'helv': 'Helvetica',
'heit': 'Helvetica-Oblique',
'hebo': 'Helvetica-Bold',
'hebi': 'Helvetica-BoldOblique',
'cour': 'Courier',
'coit': 'Courier-Oblique',
'cobo': 'Courier-Bold',
'cobi': 'Courier-BoldOblique',
'tiro': 'Times-Roman',
'tibo': 'Times-Bold',
'tiit': 'Times-Italic',
'tibi': 'Times-BoldItalic',
'symb': 'Symbol',
'zadb': 'ZapfDingbats'}
의무와 달리 모든 PDF 뷰어가 이러한 글꼴을 올바르고 완전하게 지원하는 것은 아닙니다 – 이것은 특히 Symbol과 ZapfDingbats에 해당합니다. 또한 글리프(시각적) 이미지는 각 리더에 따라 다를 수 있습니다.
이러한 글꼴을 사용하는 방법을 보려면 – CJK 내장 글꼴을 포함하여 – Page.insert_font() 의 표를 참조하세요.
Adobe PDF 참조¶
Adobe에서 발행한 이 PDF Reference 매뉴얼은 이 문서 전반에 걸쳐 자주 인용됩니다. opensource.adobe.com 에서 볼 수 있고 다운로드할 수 있습니다.
PyMuPDF 에서 Python 시퀀스를 인수로 사용하기¶
PyMuPDF 객체와 메서드가 숫자 값의 Python list 를 요구할 때, 다른 Python 시퀀스 타입 도 허용됩니다. Python 클래스는 __getitem__() 메서드를 가지고 있으면 시퀀스 프로토콜 을 구현한다고 합니다.
기본적으로 이것은 이러한 경우에 Python list 또는 tuple 또는 array.array, numpy.array 및 bytearray 타입을 상호 교환하여 사용할 수 있음을 의미합니다.
예를 들어, 다음 방법 중 하나로 시퀀스 "s" 를 지정하면
s = [1, 2]– 리스트s = (1, 2)– 튜플s = array.array("i", (1, 2))– array.arrays = numpy.array((1, 2))– numpy 배열s = bytearray((1, 2))– bytearray
다음 예제 표현식에서 사용할 수 있습니다:
pymupdf.Point(s)pymupdf.Point(x, y) + sdoc.select(s)
모든 기하 객체 Rect, IRect, Matrix 및 Point 에도 마찬가지입니다.
모든 PyMuPDF 기하 클래스 자체가 시퀀스의 특수한 경우이므로, 이들은(Quad 제외 – 아래 참조) 숫자 시퀀스를 사용할 수 있는 곳에서 자유롭게 사용할 수 있습니다. 예를 들어 list(), tuple(), array.array() 또는 numpy.array() 와 같은 함수의 인수로 사용할 수 있습니다. 이것이 작동하는 것을 보려면 다음 코드 조각을 참조하세요.
>>> import pymupdf, array, numpy as np
>>> m = pymupdf.Matrix(1, 2, 3, 4, 5, 6)
>>>
>>> list(m)
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0]
>>>
>>> tuple(m)
(1.0, 2.0, 3.0, 4.0, 5.0, 6.0)
>>>
>>> array.array("f", m)
array('f', [1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
>>>
>>> np.array(m)
array([1., 2., 3., 4., 5., 6.])
참고
Quad 도 Python 시퀀스 객체이며 길이가 4입니다. 그러나 항목은 point_like 입니다 – 숫자가 아닙니다. 따라서 위의 설명은 적용되지 않습니다.
PyMuPDF 에서 중요한 객체의 일관성 보장¶
PyMuPDF 는 C 라이브러리 MuPDF 에 대한 Python 바인딩입니다. MuPDF 의 제작자들이 객체 지향적 동작을 근사하기 위해 많은 노력을 기울였지만, C 언어의 기본적인 한계를 극복할 수는 없었습니다.
반면 Python은 OO 모델을 매우 깔끔하게 구현합니다. PyMuPDF 와 MuPDF 사이의 인터페이스 코드는 두 개의 기본 파일로 구성됩니다: pymupdf.py 와 fitz_wrap.c. 이들은 각 새 버전에 대해 우수한 SWIG 도구로 생성됩니다.
PyMuPDF 의 객체나 메서드 중 하나를 사용하면 pymupdf.py 의 일부 코드가 실행되고, 이것은 차례로 fitz_wrap.c 로 컴파일된 일부 C 코드를 호출합니다.
SWIG가 Python과 C 레벨을 동기화하기 위해 많은 노력을 기울이기 때문에, 특정 규칙 집합을 엄격히 따르면 모든 것이 잘 작동합니다. 예를 들어: 소유 Document 를 닫았거나(또는 삭제하거나 None 으로 설정한 후) Page 객체에 절대 액세스하지 마세요. 또는 덜 명확한 경우: 문서 메서드 select(), delete_page(), insert_page() 등을 실행한 후 페이지나 그 자식(링크 또는 주석)에 절대 액세스하지 마세요.
그러나 무효화된 객체에 더 이상 액세스하지 않는 것만으로는 충분하지 않습니다: C 레벨 리소스(할당된 메모리)도 해제하기 위해 완전히 삭제해야 합니다.
이러한 규칙의 이유는 문서와 그 페이지 사이, 그리고 페이지와 그 링크/주석 사이에 계층적 2단계 일대다 관계가 있다는 사실에 있습니다. 일관된 상황을 유지하기 위해 위의 작업 중 하나라도 완전한 재설정으로 이어져야 합니다 – Python과 동기적으로 C에서.
SWIG는 이것을 알 수 없으므로 결과적으로 이를 수행하지 않습니다.
따라서 필요한 로직이 다음과 같은 방식으로 PyMuPDF 자체에 내장되었습니다.
페이지가 소유 문서를 “잃거나” 자체적으로 삭제되면, 현재 존재하는 모든 주석과 링크가 Python에서 사용할 수 없게 되고, C 레벨의 대응 항목이 삭제되고 할당 해제됩니다.
문서가 닫히거나(또는 삭제되거나
None으로 설정되거나) 구조가 변경되면, 마찬가지로 현재 존재하는 모든 페이지와 그 자식이 사용할 수 없게 되고, 해당 C 레벨 삭제가 발생합니다. “구조 변경”에는 select(), delete_page(), insert_page(), insert_pdf() 등의 메서드가 포함됩니다: 이들 모두 객체 삭제의 연쇄를 초래합니다.
프로그래머는 일반적으로 이것을 인식하지 못합니다. 그러나 무효화된 객체에 액세스하려고 하면 예외가 발생합니다.
무효화된 객체는 del page 또는 page = None 등의 Python 문으로 직접 삭제할 수 없습니다. 대신 __del__ 메서드를 호출해야 합니다.
모든 페이지, 링크 및 주석은 소유 객체를 가리키는 parent 속성을 가집니다. 이것은 애플리케이션 레벨에서 확인할 수 있는 속성입니다: obj.parent == None 이면 객체의 부모가 사라진 것이며, 속성이나 메서드에 대한 참조는 이 “고아” 상태에 대해 알리는 예외를 발생시킵니다.
샘플 세션:
>>> page = doc[n]
>>> annot = page.first_annot
>>> annot.type # everything works fine
[5, 'Circle']
>>> page = None # this turns 'annot' into an orphan
>>> annot.type
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
>>>
>>> # same happens, if you do this:
>>> annot = doc[n].first_annot # deletes the page again immediately!
>>> annot.type # so, 'annot' is 'born' orphaned
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
이것은 연쇄 효과를 보여줍니다:
>>> doc = pymupdf.open("some.pdf")
>>> page = doc[n]
>>> annot = page.first_annot
>>> page.rect
pymupdf.Rect(0.0, 0.0, 595.0, 842.0)
>>> annot.type
[5, 'Circle']
>>> del doc # or doc = None or doc.close()
>>> page.rect
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
>>> annot.type
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
참고
위의 관계 외부의 객체는 이 메커니즘에 포함되지 않습니다. 예를 들어 toc = doc.get_toc() 로 목차를 만든 후 문서를 닫거나 변경하면, 이것은 변수 toc 를 어떤 방식으로도 변경할 수 없고 변경하지 않습니다. 필요에 따라 이러한 변수를 새로 고치는 것은 사용자의 책임입니다.
메서드 Page.show_pdf_page() 의 설계¶
목적 및 기능¶
이 메서드는 다른 PDF 문서의 (“소스”) 페이지 이미지를 현재 (“포함”, “대상”) 페이지의 지정된 사각형 내에 표시합니다.
Page.insert_image()와 대조적으로, 이 표시는 벡터 기반이므로 확대/축소 수준에서도 정확하게 유지됩니다.Page.insert_image()와 마찬가지로, 표시 크기는 주어진 사각형에 맞게 조정됩니다.
다음과 같은 표시 변형이 현재 지원됩니다:
- Bool 매개변수
"keep_proportion"은 종횡비를 유지할지 여부를 제어합니다(기본값). 사각형 매개변수
"clip"은 소스 페이지 사각형의 보이는 부분을 제한합니다. 기본값은 전체 페이지입니다.
- Bool 매개변수
float
"rotation"은 표시를 임의의 각도(도)로 회전시킵니다. 각도가 90의 정수 배가 아니고"keep_proportion"도 true인 경우, 4개 모서리 중 2개만 대상 경계에 위치할 수 있습니다.Bool 매개변수
"overlay"는 이미지를 현재 페이지 콘텐츠 위(전경, 기본값)에 배치할지 여부를 제어합니다(배경).
사용 사례에는 다음이 포함됩니다(이에 국한되지 않음):
회사 로고나 워터마크와 같은 동일한 이미지로 현재 문서의 일련의 페이지에 “스탬프”를 찍습니다.
임의의 입력 페이지를 하나의 출력 페이지로 결합하여 “북렛” 또는 양면 인쇄( “4-up”, “n-up” 으로 알려짐)를 지원합니다.
(큰) 입력 페이지를 여러 임의의 조각으로 분할합니다. 이것은 “포스터화”라고도 하며, 예를 들어 A4 페이지를 가로와 세로로 분할하고, 4개 조각을 확대하여 별도의 A4 페이지로 인쇄한 다음 원본 페이지의 A2 버전을 얻을 수 있기 때문입니다.
기술적 구현¶
이것은 PDF “Form XObjects” 를 사용하여 수행됩니다. Adobe PDF 참조 의 217페이지 섹션 8.10을 참조하세요. Page.show_pdf_page() 를 실행하면 다음이 발생합니다:
소스 문서의 소스 페이지의
resources및contents객체가 대상 문서로 복사되어 다음 속성을 가진 새로운 Form XObject 를 공동으로 생성합니다. 이 객체의 PDFxref번호는 메서드에 의해 반환됩니다.
/BBox는 소스 페이지의/Mediabox와 같습니다
/Matrix는 항등 행렬과 같습니다.
/Resources는 소스 페이지의 것과 같습니다. 이것은 계층적으로 중첩된 다른 객체(글꼴, 이미지 등 포함)의 deep-copy” 를 포함합니다. 여기에 관련된 복잡성은 MuPDF 의 grafting [1] 기술 함수로 처리됩니다.이것은 스트림 객체 타입이며, 그 스트림은 소스 페이지의
contents객체의 결합된 데이터의 정확한 복사본입니다.이 Form XObject는 표시된 소스 페이지당 한 번만 실행됩니다. 동일한 소스 페이지의 후속 표시는 이 단계를 건너뛰고 이 객체에 대한 “포인터” Form XObjects만 생성합니다(다음 단계에서 수행).
그런 다음 대상 페이지가 표시를 호출하는 데 사용하는 두 번째 Form XObject 가 생성됩니다. 이 객체는 다음 속성을 가집니다:
/BBox는 소스 페이지의/CropBox(또는"clip")와 같습니다.
/Matrix는/BBox를 대상 사각형으로 매핑하는 것을 나타냅니다.
/XObject는 고정된 이름fullpage를 통해 이전 Form XObject를 참조합니다.이 객체의 스트림은 정확히 하나의 고정된 문을 포함합니다:
/fullpage Do.메서드의
"oc"인수가 주어지면, 그 값이 이 Form XObject에/OC로 할당됩니다.대상 페이지의
resources및contents객체는 다음과 같이 수정됩니다.
/Resources의/XObject딕셔너리에fzFrm이라는 이름으로 항목을 추가합니다(n은 이 항목이 페이지에서 고유하도록 선택됨).
"overlay"에 따라 페이지의/Contents배열에q /fzFrm<n> Do Q문을 포함하는 새 객체를 앞에 추가하거나 뒤에 추가합니다.
이 설계 접근 방식은 다음을 보장합니다:
(잠재적으로 큰) 소스 페이지는 대상 PDF에 한 번만 복사됩니다. 소스 페이지를 표시하기 위해 각 대상 페이지당 작은 “포인터” Form XObjects 객체만 생성됩니다.
각 참조 대상 페이지는 소스 페이지의 가시성을 개별적으로 제어하기 위해 자체
"oc"매개변수를 가질 수 있습니다.
진단¶
PyMuPDF 메시지¶
PyMuPDF 는 텍스트 진단을 표시하기 위한 메시지 시스템을 가지고 있습니다.
기본적으로 메시지는 sys.stdout 에 기록됩니다. 이것은 두 가지 방법으로 제어할 수 있습니다:
PyMuPDF 를 가져오기 전에 환경 변수
PYMUPDF_MESSAGE를 설정합니다.set_messages()를 호출합니다:
MuPDF 오류 및 경고¶
MuPDF 는 텍스트 오류 및 경고를 생성합니다.
이러한 오류 및 경고는 내부 목록에 추가되며,
Tools.mupdf_warnings()로 액세스할 수 있습니다.Tools.reset_mupdf_warnings()도 참조하세요.기본적으로 이러한 오류 및 경고는 PyMuPDF 메시지 시스템에도 전송됩니다.
이것은
mupdf_display_errors()및mupdf_display_warnings()로 제어할 수 있습니다.이러한 메시지는 각각
MuPDF error:및MuPDF warning:접두사가 붙습니다.
일부 MuPDF 오류는 Python 예외를 유발할 수 있습니다.
복구 가능한 오류 에 대한 예제 출력입니다. 손상된 PDF를 열고 있지만 MuPDF 는 이를 복구할 수 있고 발생한 일에 대한 약간의 정보를 제공합니다. 그런 다음 문서를 나중에 증분 저장할 수 있는지 확인하는 방법을 설명합니다. 이 시점에서 Document.is_dirty 속성을 확인하면 pymupdf.open 중에 문서를 복구해야 했음을 나타냅니다:
>>> import pymupdf
>>> doc = pymupdf.open("damaged-file.pdf") # leads to a sys.stderr message:
mupdf: cannot find startxref
>>> print(pymupdf.TOOLS.mupdf_warnings()) # check if there is more info:
cannot find startxref
trying to repair broken xref
repairing PDF document
object missing 'endobj' token
>>> doc.can_save_incrementally() # this is to be expected:
False
>>> # the following indicates whether there are updates so far
>>> # this is the case because of the repair actions:
>>> doc.is_dirty
True
>>> # the document has nevertheless been created:
>>> doc
pymupdf.Document('damaged-file.pdf')
>>> # we now know that any save must occur to a new file
복구 불가능한 오류 에 대한 예제 출력:
>>> import pymupdf
>>> doc = pymupdf.open("does-not-exist.pdf")
mupdf: cannot open does-not-exist.pdf: No such file or directory
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
doc = pymupdf.open("does-not-exist.pdf")
File "C:\Users\Jorj\AppData\Local\Programs\Python\Python37\lib\site-packages\fitz\pymupdf.py", line 2200, in __init__
_pymupdf.Document_swiginit(self, _pymupdf.new_Document(filename, stream, filetype, rect, width, height, fontsize))
RuntimeError: cannot open does-not-exist.pdf: No such file or directory
>>>
좌표¶
이것은 이 문서에서 가장 자주 사용되는 용어 중 하나입니다. 좌표 는 일반적으로 사각형의 모서리(Rect), Point 등과 같은 위치를 나타내는 숫자 쌍 (x, y) 를 의미합니다. 두 값은 일반적으로 float이지만, 정수만 허용하는 이미지와 같은 객체도 있습니다.
실제로 좌표의 위치를 찾으려면, x 와 y 의 참조 점도 알아야 합니다 – 즉, 위치 (0, 0) 이 어디에 있는지 알아야 합니다. (0, 0) (“원점”)이 알려지면 “좌표계”라고 말합니다.
문서 처리에는 여러 좌표계가 존재합니다. 예를 들어, PDF 페이지와 그것으로부터 생성된 이미지의 좌표계는 다릅니다. 따라서 한 시스템에서 다른 시스템으로 좌표를 변환 하는 방법이 필요합니다(때로는 역으로도). 이것이 Matrix 의 작업입니다. 이것은 점이나 사각형과 “곱할” 수 있는 인수처럼 작동하여 다른 좌표계에서 해당 점/사각형을 제공하는 수학 함수입니다. 변환 행렬의 역행렬을 사용하여 변환을 되돌릴 수 있습니다. 예를 들어 3을 곱하는 것을 결과를 3으로 나누거나(또는 1/3을 곱함)하여 되돌릴 수 있는 것과 매우 유사합니다.
좌표 및 이미지¶
이미지는 정수 좌표를 가진 좌표계를 가집니다. 원점 (0, 0) 은 왼쪽 위 점입니다. x 값은 range(width) 에 있어야 하고, y 값은 range(height) 에 있어야 합니다. 따라서 아래로 가면 y 값이 증가 합니다. 모든 이미지에 대해 유한한 수 의 좌표만 있습니다. 즉, width * height 입니다. 이미지의 위치는 “픽셀”이라고도 합니다.
예를 들어 인쇄할 때 이미지가 얼마나 큰지 (센티미터 또는 인치)는 추가 정보인 “해상도”에 따라 다릅니다. 이것은 DPI (인치당 도트 또는 인치당 픽셀)로 측정됩니다. 따라서 이미지의 인쇄 크기를 찾으려면 너비와 높이를 해당 DPI 값으로 나누어야 하며(너비와 높이에 대해 별도의 값이 있을 수 있음) 각각의 인치 수를 얻을 수 있습니다.
원점, 포인트 크기 및 Y축¶
PDF 에서 페이지의 원점 (0, 0) 은 왼쪽 아래 점 에 있습니다. MuPDF 에서 페이지의 원점 (0, 0) 은 왼쪽 위 점 에 있습니다.
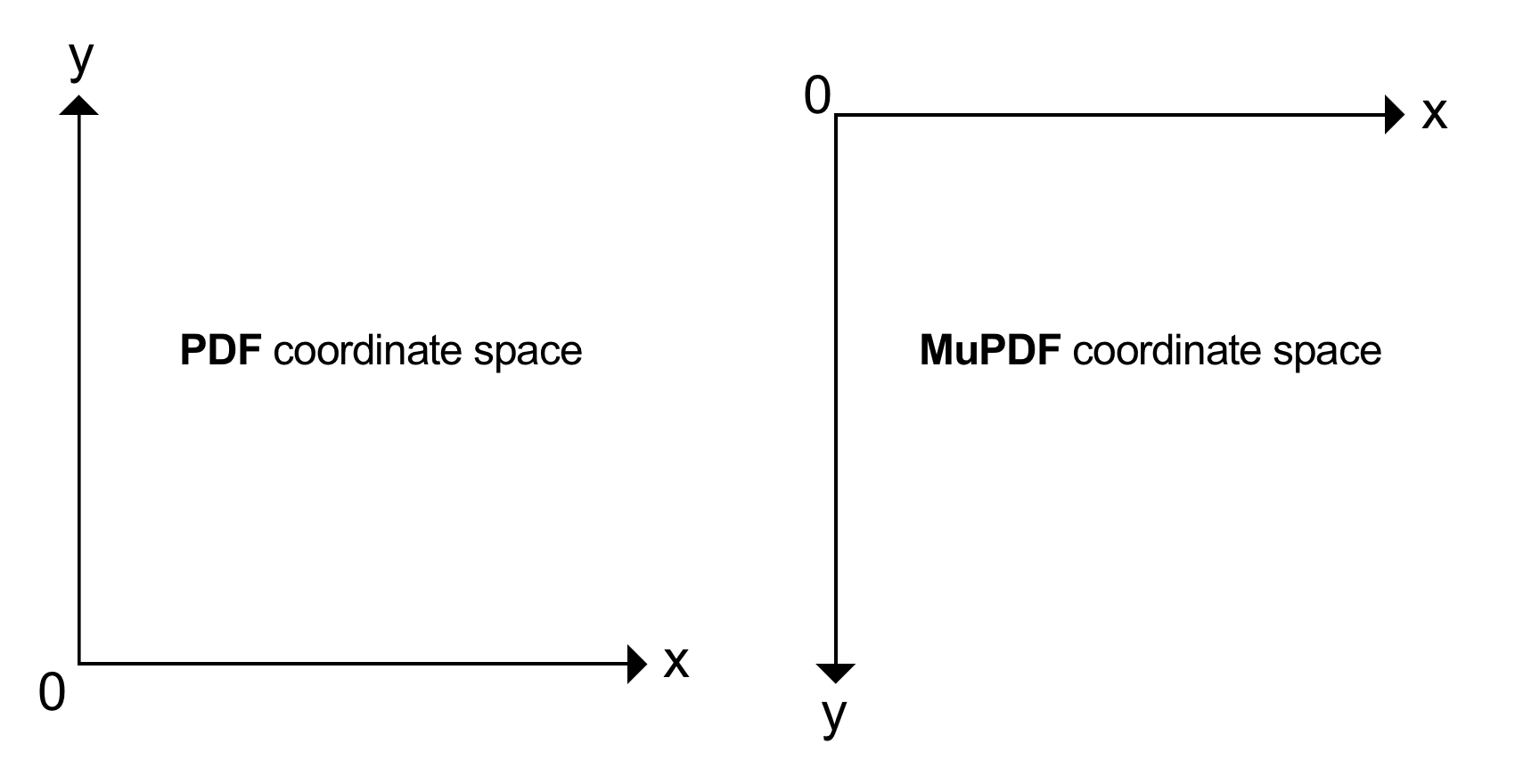
좌표는 float 숫자이며 포인트 단위로 측정됩니다. 여기서:
1포인트는 1/72인치 와 같습니다.
일반적인 문서 페이지 크기는 ISO A4 및 Letter 입니다. Letter 페이지는 8.5 x 11인치 크기를 가지며, 이는 612 x 792 포인트 에 해당합니다. PDF 좌표계에서 Letter 페이지의 왼쪽 위 점은 y축이 위를 가리키므로 좌표 (0, 792) 를 가집니다. 이제 문서 크기를 알았으므로 MuPDF 좌표계에서 오른쪽 아래는 좌표 (612, 792) 가 됩니다(PDF 에서는 이 좌표가 (612,0) 이 됩니다).
이론적으로 PDF 페이지에는 무한히 많은 좌표 위치가 있습니다. 그러나 실제로는 합리적인 정밀도를 위해 최대 처음 5자리 소수점이면 충분합니다.
MuPDF 에서는 여러 문서 형식이 지원됩니다 – PDF 는 12개 이상의 다른 형식 중 하나일 뿐입니다. 이미지도 MuPDF 에서 문서로 지원됩니다(따라서 일반적으로 한 페이지를 가짐). 이것이 MuPDF 가 원점
(0, 0)이 모든 문서 페이지의 왼쪽 위 점인 좌표계를 사용하는 이유 중 하나입니다. y축은 아래를 가리킵니다, 이미지와 마찬가지입니다. MuPDF 의 좌표는 어떤 경우든 PDF 와 마찬가지로 float입니다.예를 들어 MuPDF (따라서 PyMuPDF )에서
Rect(0, 0, 100, 100)사각형은 길이가 100포인트(= 1.39인치 또는 3.53센티미터)인 변을 가진 정사각형입니다. 왼쪽 위 모서리가 원점입니다. 두 좌표계 PDF 와 MuPDF 사이를 전환하려면 모든 Page 객체는Page.transformation_matrix를 가집니다. 그 역행렬을 사용하여 사각형의 PDF 좌표를 계산할 수 있습니다. 이렇게 하면 MuPDF 의Rect(0, 0, 100, 100)이 PDF 의Rect(0, 692, 100, 792)와 같다는 것을 편리하게 찾을 수 있습니다. 이 코드 조각을 참조하세요:>>> page = doc.new_page(width=612, height=792) # make new Letter page >>> ptm = page.transformation_matrix >>> # the inverse matrix of ptm is ~ptm >>> pymupdf.Rect(0, 0, 100, 100) * ~ptm Rect(0.0, 692.0, 100.0, 792.0)
CSS Support¶
For now, only a subset of CSS properties are supported.
The underlying C library MuPDF supports a subset of HTML4 and CSS2. The primary goal of the HTML/CSS support is to serve as a popular and convenient way to style text — not to faithfully reproduce websites in PDF.
What Works¶
The following list shows the supported properties, grouped by category.
Box Model & Layout¶
margin, margin-top, margin-right, margin-bottom, margin-left, padding, padding-top, padding-right, padding-bottom, padding-left, width, height, display, position, top, right, bottom, left, inset, overflow-wrap, columns
참고
The properties position & display are supported in a very limited way. Only the values position: relative and display: block are supported.
Border¶
border, border-top, border-right, border-bottom, border-left, border-color, border-style, border-width, border-spacing, border-collapse, border-top-color, border-right-color, border-bottom-color, border-left-color, border-top-style, border-right-style, border-bottom-style, border-left-style, border-top-width, border-right-width, border-bottom-width, border-left-width
Background¶
background, background-color
참고
Background images are not supported, but the background property can be used to set a background color for a text block, which is then rendered as a filled rectangle behind the text.
Font¶
font, font-family, font-size, font-style, font-variant, font-weight
Text¶
color, letter-spacing, line-height, text-align, text-decoration, text-indent, text-transform, word-spacing, white-space, vertical-align, direction, hyphens
List¶
list-style, list-style-image, list-style-position, list-style-type
Page¶
page-break-before, page-break-after, orphans, widows
Visibility¶
visibility
MuPDF-specific / WebKit extensions¶
-mupdf-leading, -webkit-text-fill-color, -webkit-text-stroke-color, -webkit-text-stroke-width
Other¶
src (for @font-face), overflow-wrap
What Doesn’t Work¶
Modern CSS (CSS3+): no flexbox, grid, custom properties (–vars), calc(), transitions, animations, float, clear.
각주