テキスト¶
すべてのドキュメントテキストを抽出する方法¶
このスクリプトは、ドキュメントのファイル名を受け取り、そのテキストからテキストファイルを生成します。
ドキュメントは、サポートされている 任意のタイプのものが使用できます。
このスクリプトはコマンドラインツールとして機能し、ドキュメントのファイル名をパラメータとして受け取ります。スクリプトのディレクトリに「filename.txt」という名前のテキストファイルが生成されます。ページのテキストはフォームフィード文字で区切られます。
import sys, pathlib, pymupdf
fname = sys.argv[1] # get document filename
with pymupdf.open(fname) as doc: # open document
text = chr(12).join([page.get_text() for page in doc])
# write as a binary file to support non-ASCII characters
pathlib.Path(fname + ".txt").write_bytes(text.encode())
出力はドキュメント内でコード化された通りのプレーンテキストになるため、見栄えの調整は行いません。特にPDFの場合、通常の読み順にならない出力や予期せぬ改行などが発生するかもしれません。
これを修正するための多くのオプションがあります。詳細は 付録2:埋め込みファイルに関する考慮事項 章「埋め込みファイルに関する考慮事項」を参照してください。以下の方法があります:
テキストをHTML形式で抽出し、HTMLドキュメントとして保存することで、任意のブラウザで表示できるようにします。
Page.get_text("blocks")を使ってテキストブロックのリストとして抽出します。リストの各アイテムにはテキストの位置情報が含まれており、便利な読み順を確立するのに使用できます。
Page.get_text("words")を使って単語のリストを抽出します。各アイテムには位置情報が含まれています。これを使用して特定の四角形に含まれるテキストを決定します。
以下の2つのセクションを見て、例と詳細な説明をご覧ください。
テキストをMarkdown形式で抽出する方法¶
これは、特に RAG/LLM 環境にとって便利です - Outputting as Markdown を参照してください。
ページからキーと値のペアを抽出する方法¶
もしページのレイアウトがある程度予測可能であれば、正規表現を使用せずに、特定のキーワードに対する値を迅速かつ簡単に見つける方法があります。 以下の例のスクリプト を参照してください。
ここでの「予測可能」とは、次のような意味です:
各キーワードの後にはその値が続きます。それらの間に他のテキストはありません。
値の境界ボックスの下端は、キーワードの境界ボックスよりも上にありません。
他の制約はありません:ページのレイアウトが固定されているかどうかは問いませんし、テキストは1つの文字列として保存されている可能性もあります。キーと値はお互いに任意の距離を持つかもしれません。
例として、以下の5つのキーと値のペアが正しく識別されます:
key1 value1
key2
value2
key3
value3 blah, blah, blah key4 value4 some other text key5 value5 ...
四角形内のテキストを抽出する方法¶
現在(v1.18.0)では、これを実現するための複数の方法があります。そのため、私たちは PyMuPDF-Utilities リポジトリに、この特定のトピックに対応するフォルダを作成しました。
自然な読み順でテキストを抽出する方法¶
PDFのテキスト抽出によくある問題の1つは、テキストが特定の読み順に表示されないことです。
これはPDFの作成者(ソフトウェアまたは人間)の責任です。たとえば、ページヘッダーはドキュメントが作成された後の別のステップで挿入された可能性があります。そのような場合、ヘッダーテキストはページテキストの抽出の最後に表示されることがあります(ただし、PDFビューアソフトウェアでは正しく表示されます)。以下のスニペットは、既存のPDFにいくつかのヘッダーとフッターの行を追加します:
doc = pymupdf.open("some.pdf")
header = "Header" # text in header
for page in doc:
page.insert_text((50, 50), header) # insert header
page.insert_text( # insert footer 50 points above page bottom
(50, page.rect.height - 50),
f"Page {page.number + 1} of {doc.page_count}", # text in footer
)
このように変更されたページから抽出されたテキストのシーケンスは次のようになります:
元のテキスト
ヘッダーライン
フッターライン
PyMuPDFには、いくつかの方法で読み順を再確立したり、元のレイアウトに近い形で再生成する手段があります:
Page.get_text()のsortパラメーターを使用します。これにより、出力が左上から右下に向かってソートされます(XHTML、HTML、XML出力には無効です)。CLIで
pymupdfモジュールを使用します:python -m pymupdf gettext ...。これにより、テキストがレイアウトを保持するモードで再配置されたテキストファイルが生成されます。出力を制御するための多くのオプションが利用可能です。
また、上記の スクリプト を自分の変更とともに使用することもできます。
ドキュメントから表の内容を抽出する方法¶
文書で表を見る場合、通常は埋め込まれたExcelなどの識別可能なオブジェクトのようなものではありません。通常、単なる通常の標準テキストで、表のデータとして表示されるようにフォーマットされています。
したがって、そのようなページ領域から表のデータを抽出するには、まず表の領域(つまり、その境界ボックス)を特定する方法を見つける必要があり、その後(1)グラフィカルに表と列の境界を示し、(2)この情報に基づいてテキストを抽出する必要があります。
これは、線、四角形、またはその他のサポートベクトルグラフィックの存在または不在などの詳細に依存するため、非常に複雑なタスクになる可能性があります。
Method Page.find_tables() は、高い表検出精度を備えて、すべてをあなたのために行います。その大きな利点は、外部ライブラリの依存関係がないこと、人工知能や機械学習技術を使用する必要がないことです。また、データ分析のためのPythonパッケージである pandas のための統合されたインターフェースも提供します。
標準的な状況をカバーする例の Jupyter ノートブックをご覧いただければ幸いです。これには、1つのページに複数の表や複数のページにまたがる表の断片を結合するなどの状況が含まれています。
抽出したテキストをマークする方法¶
ページ上で任意のテキストを検索するための標準的な検索機能があります: Page.search_for() です。これは、見つかったテキストを囲む Rect (矩形) オブジェクトのリストを返します。これらの四角形は、見つかったテキストを目に見えるようにマークするために自動的に注釈を挿入するのに使用できます。
この方法には利点と欠点があります。利点は次のとおりです:
検索文字列には空白を含めることができ、行をまたぐことができます。
大文字と小文字は同じように扱われます。
行末での単語のハイフネーションが検出され、解決されます。
返り値は Quad (クアッド) オブジェクトのリストになる場合もあり、これにより軸に対して平行でないテキストを正確に位置付けることができます。ページの回転がゼロでない場合には、 Quad (クアッド) の出力を使用することも推奨されます。
ただし、他にも選択肢があります:
import sys
import pymupdf
def mark_word(page, text):
"""Underline each word that contains 'text'.
"""
found = 0
wlist = page.get_text("words", delimiters=None) # make the word list
for w in wlist: # scan through all words on page
if text in w[4]: # w[4] is the word's string
found += 1 # count
r = pymupdf.Rect(w[:4]) # make rect from word bbox
page.add_underline_annot(r) # underline
return found
fname = sys.argv[1] # filename
text = sys.argv[2] # search string
doc = pymupdf.open(fname)
print(f"underlining words containing '{word}' in document '{doc.name}'")
new_doc = False # indicator if anything found at all
for page in doc: # scan through the pages
found = mark_word(page, text) # mark the page's words
if found: # if anything found ...
new_doc = True
print(f"found '{text}' {found} times on page {page.number + 1}")
if new_doc:
doc.save("marked-" + doc.name)
このスクリプトは、cliパラメーターを介して渡された文字列を検索するためにPage.get_text("words")を使用します。この方法では、ページのテキストがスペースと改行を区切りとして「単語」に分割されます。さらなる注釈:
文字列が見つかった場合、検索文字列だけでなく、その文字列を含む完全な単語がマークされます(アンダーラインが引かれます)。
検索文字列には単語の区切り文字を含めることはできません。デフォルトでは、単語の区切り文字は空白と非改行空白
chr(0xA0)です。もし、page.get_text("words", delimiters="./,")のような追加の区切り文字を使用する場合は、これらの文字を検索文字列に含めてはいけません。ここで示したように、大文字と小文字は区別されますが、
mark_word関数でlower()メソッド(または正規表現)を使用することで変更できます。上限はありません。すべての出現を検出します。
単語をマークするために何を使用しても構いません:「アンダーライン」、「ハイライト」、「取り消し線」、「四角」の注釈などがあります。
以下は、このマニュアルのページの一部の例スニペットで、「MuPDF」が検索文字列として使用されています。注意:「MuPDF」を含むすべての文字列が完全にアンダーラインで引かれていることに注意してください(検索文字列だけでなく)。

検索したテキストをマークする方法¶
このスクリプトはテキストを検索してマークします:
# -*- coding: utf-8 -*-
import pymupdf
# the document to annotate
doc = pymupdf.open("tilted-text.pdf")
# the text to be marked
needle = "¡La práctica hace el campeón!"
# work with first page only
page = doc[0]
# get list of text locations
# we use "quads", not rectangles because text may be tilted!
rl = page.search_for(needle, quads=True)
# mark all found quads with one annotation
page.add_squiggly_annot(rl)
# save to a new PDF
doc.save("a-squiggly.pdf")
結果は以下のようになります:

非水平テキストをマークする方法¶
前のセクションでは、テキスト検索によって検出された非水平テキストのマークの例が既に示されています。
しかし、 Page.get_text() の「dict」/「rawdict」オプションを使用したテキスト抽出では、x軸に対してゼロでない角度のテキストも返される場合があります。これは、行の辞書の "dir" キーの値によって示されます:それはその角度に対する (cosine, sine) のタプルです。 line["dir"] != (1, 0) であれば、すべてのスパンのテキストは (同じ) 角度 != 0 によって回転しています。
ただし、このメソッドによって返される「bboxes」は四角形のみであり、クワッドではありません。したがって、スパンテキストを正しくマークするには、行とスパンの辞書に含まれるデータからクワッドを回復する必要があります。以下のユーティリティ関数を使用してください(v1.18.9で新しく追加されました):
span_quad = pymupdf.recover_quad(line["dir"], span)
annot = page.add_highlight_annot(span_quad) # this will mark the complete span text
一度に完全な行またはその一部のスパンをマークしたい場合は、以下のスニペットを使用してください(v1.18.10以降で動作します)
line_quad = pymupdf.recover_line_quad(line, spans=line["spans"][1:-1])
page.add_highlight_annot(line_quad)

上記の spans 引数は、line["spans"] の任意の部分リストを指定できます。上記の例では、2番目から最後から2番目のスパンがマークされます。省略すると、完全な行が取得されます
フォントの特性を分析する方法¶
PDF内のテキストの特性を分析するには、以下の初歩的なスクリプトを出発点として使用します:
import sys
import pymupdf
def flags_decomposer(flags):
"""Make font flags human readable."""
l = []
if flags & 2 ** 0:
l.append("superscript")
if flags & 2 ** 1:
l.append("italic")
if flags & 2 ** 2:
l.append("serifed")
else:
l.append("sans")
if flags & 2 ** 3:
l.append("monospaced")
else:
l.append("proportional")
if flags & 2 ** 4:
l.append("bold")
return ", ".join(l)
doc = pymupdf.open(sys.argv[1])
page = doc[0]
# read page text as a dictionary, suppressing extra spaces in CJK fonts
blocks = page.get_text("dict", flags=11)["blocks"]
for b in blocks: # iterate through the text blocks
for l in b["lines"]: # iterate through the text lines
for s in l["spans"]: # iterate through the text spans
print("")
s_font = s['font']
s_flags = flags_decomposer(s['flags'])
s_size = s['size']
s_color = s['color']
print(f"Text: '{s['text']}'") # simple print of text
print(f"Font: '{s_font}' ({s_flags}), size {s_size}, color #{s_color:06x}")
以下はPDFページとスクリプトの出力です。

テキストの挿入方法¶
PyMuPDFは、以下の機能を備えて新しいまたは既存のPDFページにテキストを挿入する方法を提供しています:
フォントの選択:組み込みのフォントやファイルとして利用可能なフォントを選択できます。
テキストの特性の選択:太字、斜体、フォントサイズ、フォントカラーなど、テキストの特性を選択できます。
テキストの配置方法:
特定のポイントを起点として単純な行指向の出力として配置することができます。
ボックスにテキストをフィットさせる場合は、テキストの配置を選択することもできます。この場合、テキストの整列オプションも利用できます。
テキストを前面に配置するか選択できます(既存のコンテンツをオーバーレイします)。
テキストは任意に「変形」されることができます。つまり、行列を使用して拡大、せん断、反転などの効果を得ることができます。
変形とは別に、テキストを90度の整数倍で回転させることもできます。
以上のすべては、それぞれの基本的な Page (ページ) 、Shape(シェイプ) メソッドによって提供されています。
Page.insert_font()- ページにフォントをインストールして後で参照できるようにします。その結果は、Document.get_page_fonts()の出力に反映されます。フォントは以下の方法で提供できます:ファイルとして提供する。
Font (フォント) を使用して提供する(その場合、
Font.bufferを使用します)。既にこのPDFまたは別のPDFのどこかに存在する。
組み込みフォントである。
Page.insert_text()- テキストの行を書き込みます。内部的にはShape.insert_text()を使用します。Page.insert_textbox()- 指定された矩形にテキストをフィットさせます。ここでは、テキストの整列機能(左揃え、右揃え、中央揃え、両端揃え)を選択できます。また、テキストが実際にフィットするかどうかの制御もできます。内部的にはShape.insert_textbox()を使用します。
注釈
テキスト挿入の両方の方法は、必要に応じてフォントを自動的にインストールします。
テキスト行を書く方法¶
ページにいくつかのテキスト行を出力する方法:
import pymupdf
doc = pymupdf.open(...) # new or existing PDF
page = doc.new_page() # new or existing page via doc[n]
p = pymupdf.Point(50, 72) # start point of 1st line
text = "Some text,\nspread across\nseveral lines."
# the same result is achievable by
# text = ["Some text", "spread across", "several lines."]
rc = page.insert_text(p, # bottom-left of 1st char
text, # the text (honors '\n')
fontname = "helv", # the default font
fontsize = 11, # the default font size
rotate = 0, # also available: 90, 180, 270
)
print(f"{rc} lines printed on page {page.number}.")
doc.save("text.pdf")
この方法では、ページの高さを超えないように行の数だけを制御します。余剰の行は書き込まれず、実際の行数が返されます。計算には、fontsize と36ポイント(0.5インチ)のボトムマージンから計算された行の高さが使用されます。
行の幅は無視されます。行の余剰部分は単に見えなくなります。
ただし、組み込みのフォントには、行の幅を事前に計算する方法があります。 get_text_length() を参照してください。
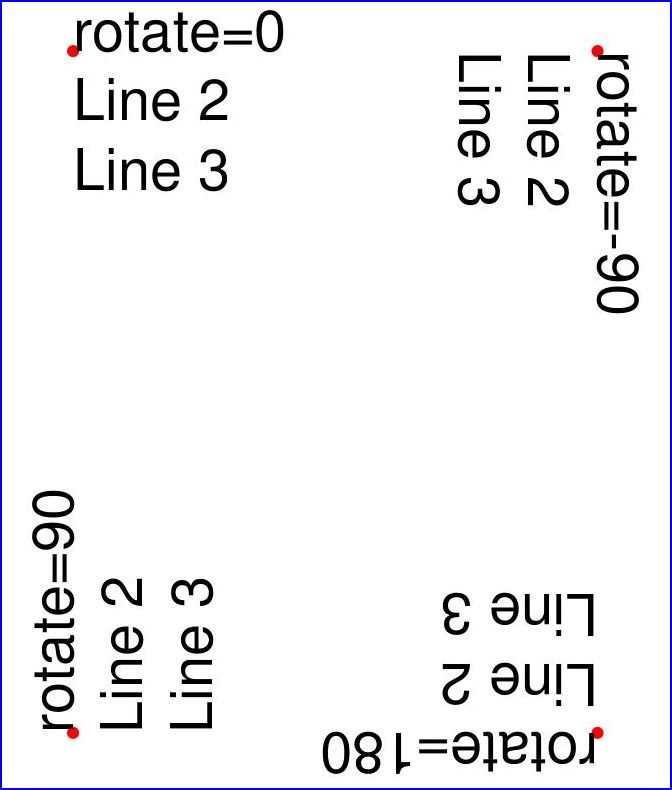
以下は別の例です。4つの異なる回転オプションを使用してテキスト文字列を挿入し、それにより、望む結果を得るためにどのようにテキスト挿入ポイントを選択すべきかを説明しています:
import pymupdf
doc = pymupdf.open()
page = doc.new_page()
# the text strings, each having 3 lines
text1 = "rotate=0\nLine 2\nLine 3"
text2 = "rotate=90\nLine 2\nLine 3"
text3 = "rotate=-90\nLine 2\nLine 3"
text4 = "rotate=180\nLine 2\nLine 3"
red = (1, 0, 0) # the color for the red dots
# the insertion points, each with a 25 pix distance from the corners
p1 = pymupdf.Point(25, 25)
p2 = pymupdf.Point(page.rect.width - 25, 25)
p3 = pymupdf.Point(25, page.rect.height - 25)
p4 = pymupdf.Point(page.rect.width - 25, page.rect.height - 25)
# create a Shape to draw on
shape = page.new_shape()
# draw the insertion points as red, filled dots
shape.draw_circle(p1,1)
shape.draw_circle(p2,1)
shape.draw_circle(p3,1)
shape.draw_circle(p4,1)
shape.finish(width=0.3, color=red, fill=red)
# insert the text strings
shape.insert_text(p1, text1)
shape.insert_text(p3, text2, rotate=90)
shape.insert_text(p2, text3, rotate=-90)
shape.insert_text(p4, text4, rotate=180)
# store our work to the page
shape.commit()
doc.save(...)
これが結果です。
テキストボックスの塗りつぶし方¶
このスクリプトは、異なる回転値を選択して、4つの異なる長方形にテキストを塗りつぶします。
import pymupdf
doc = pymupdf.open() # new or existing PDF
page = doc.new_page() # new page, or choose doc[n]
# write in this overall area
rect = pymupdf.Rect(100, 100, 300, 150)
# partition the area in 4 equal sub-rectangles
CELLS = pymupdf.make_table(rect, cols=4, rows=1)
t1 = "text with rotate = 0." # these texts we will written
t2 = "text with rotate = 90."
t3 = "text with rotate = 180."
t4 = "text with rotate = 270."
text = [t1, t2, t3, t4]
red = pymupdf.pdfcolor["red"] # some colors
gold = pymupdf.pdfcolor["gold"]
blue = pymupdf.pdfcolor["blue"]
"""
We use a Shape object (something like a canvas) to output the text and
the rectangles surrounding it for demonstration.
"""
shape = page.new_shape() # create Shape
for i in range(len(CELLS[0])):
shape.draw_rect(CELLS[0][i]) # draw rectangle
shape.insert_textbox(
CELLS[0][i], text[i], fontname="hebo", color=blue, rotate=90 * i
)
shape.finish(width=0.3, color=red, fill=gold)
shape.commit() # write all stuff to the page
doc.ez_save(__file__.replace(".py", ".pdf"))
上記ではいくつかのデフォルト値が使用されました:フォント「Helvetica」、フォントサイズ11、テキストの配置は「左寄せ」です。結果は以下のようになります。

HTMLテキストでボックスを埋める方法¶
メソッド Page.insert_htmlbox() は、矩形にテキストを挿入するための より強力な 方法を提供します。
このメソッドは、単純なプレーンテキストではなく、HTMLソースを受け入れます。HTMLタグのみならず、フォント、フォントの太さ(太字)、スタイル(イタリック)、色などを含むスタイル指示も含まれます。
複数のフォントや言語を混在させ、HTMLテーブルを出力し、画像やURIリンクを挿入することも可能です。
さらなるスタイリングの柔軟性を求める場合、追加のCSSソースを指定することもできます。
このメソッドは、 Story (ストーリー) (ストーリー)クラスに基づいています。そのため、デーヴァナーガリ、ネパール語、タミル語などの複雑な文字体系がサポートされ、HarfBuzzライブラリを使用して正しく書き込まれています - これがいわゆる 「テキストの形成」 機能を提供します。
文字を出力するために必要なフォントは、--オプションで提供される--ユーザーフォントが一部のグリフを含んでいない場合のフォールバックとして、Google NOTOフォントライブラリから自動的に取得されます。
ここで提供される機能の一端をご覧いただくために、以下のHTMLエンリッチされたテキストを出力します:
import pymupdf
rect = pymupdf.Rect(100, 100, 400, 300)
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: #f00;">reprehenderit</span>
in <span style="color: #0f0;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
doc = pymupdf.Document()
page = doc.new_page()
page.insert_htmlbox(rect, text, css="* {font-family: sans-serif;font-size:14px;}")
doc.ez_save(__file__.replace(".py", ".pdf"))
「css」パラメータが、デフォルトの「sans-serif」フォントとフォントサイズ14をグローバルに選択する方法に注意してください。
結果は以下のようになります:

HTMLテーブルや画像を出力する方法¶
以下は、このメソッドを使用してテーブルを出力する別の例です。今回は、すべてのスタイリングをHTMLソース自体に含めています。また、テーブルセル内に画像を含める方法についても、ご注意ください:
import pymupdf
import os
filedir = os.path.dirname(__file__)
text = """
<style>
body {
font-family: sans-serif;
}
td,
th {
border: 1px solid blue;
border-right: none;
border-bottom: none;
padding: 5px;
text-align: center;
}
table {
border-right: 1px solid blue;
border-bottom: 1px solid blue;
border-spacing: 0;
}
</style>
<body>
<p><b>Some Colors</b></p>
<table>
<tr>
<th>Lime</th>
<th>Lemon</th>
<th>Image</th>
<th>Mauve</th>
</tr>
<tr>
<td>Green</td>
<td>Yellow</td>
<td><img src="img-cake.png" width=50></td>
<td>Between<br>Gray and Purple</td>
</tr>
</table>
</body>
"""
doc = pymupdf.Document()
page = doc.new_page()
rect = page.rect + (36, 36, -36, -36)
# we must specify an Archive because of the image
page.insert_htmlbox(rect, text, archive=pymupdf.Archive("."))
doc.ez_save(__file__.replace(".py", ".pdf"))
結果は以下のようになります:

世界の言語を出力する方法¶
3つ目の例では、自動多言語サポートを示します。これには、デーヴァナーガリや右から左への言語などの複雑なスクリプトシステムに対する自動 テキスト整形 も含まれます:
import pymupdf
greetings = (
"Hello, World!", # english
"Hallo, Welt!", # german
"سلام دنیا!", # persian
"வணக்கம், உலகம்!", # tamil
"สวัสดีชาวโลก!", # thai
"Привіт Світ!", # ucranian
"שלום עולם!", # hebrew
"ওহে বিশ্ব!", # bengali
"你好世界!", # chinese
"こんにちは世界!", # japanese
"안녕하세요, 월드!", # korean
"नमस्कार, विश्व !", # sanskrit
"हैलो वर्ल्ड!", # hindi
)
doc = pymupdf.open()
page = doc.new_page()
rect = (50, 50, 200, 500)
# join greetings into one text string
text = " ... ".join([t for t in greetings])
# the output of the above is simple:
page.insert_htmlbox(rect, text)
doc.save(__file__.replace(".py", ".pdf"))
これが結果です。

独自のフォントを指定する方法¶
@font-face ステートメントを使用して、CSS構文でフォントファイルを定義します。サポートされるフォントのウェイトとスタイル(太字や斜体など)の組み合わせごとに、個別の @font-face が必要です。以下の例では、有名な MS Comic Sans フォントの 4 つのバリアント(通常、太字、斜体、太字斜体)を使用しています。
これらの 4 つのフォントファイルがシステムのフォルダ C:/Windows/Fonts にあるため、このメソッドには、そのフォルダを指す Archive (アーカイブ) (アーカイブ)の定義が必要です。
"""
How to use your own fonts with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
We need an Archive object to show where font files are located.
We intend to use the font family "MS Comic Sans".
"""
arch = pymupdf.Archive("C:/Windows/Fonts")
# These statements define which font file to use for regular, bold,
# italic and bold-italic text.
# We assign an arbitrary common font-family for all 4 font files.
# The Story algorithm will select the right file as required.
# We request to use "comic" throughout the text.
css = """
@font-face {font-family: comic; src: url(comic.ttf);}
@font-face {font-family: comic; src: url(comicbd.ttf);font-weight: bold;}
@font-face {font-family: comic; src: url(comicz.ttf);font-weight: bold;font-style: italic;}
@font-face {font-family: comic; src: url(comici.ttf);font-style: italic;}
* {font-family: comic;}
"""
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150) # make small page
page.insert_htmlbox(page.rect, text, css=css, archive=arch)
doc.subset_fonts(verbose=True) # build subset fonts to reduce file size
doc.ez_save(__file__.replace(".py", ".pdf"))

テキストの配置をリクエストする方法¶
この例では、複数の要件を組み合わせています
テキストを90度反時計回りに回転させます。
pymupdf-fonts パッケージからフォントを使用します。この場合、該当するCSS定義がはるかに簡単であることに気付くでしょう。
テキストを "justify" オプションで配置します。
"""
How to use a pymupdf font with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
This is similar to font file support. However, we can use a convenience
function for creating required CSS definitions.
We still need an Archive for finding the font binaries.
"""
arch = pymupdf.Archive()
# We request to use "myfont" throughout the text.
css = pymupdf.css_for_pymupdf_font("ubuntu", archive=arch, name="myfont")
css += "* {font-family: myfont;text-align: justify;}"
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150)
page.insert_htmlbox(page.rect, text, css=css, archive=arch, rotate=90)
doc.subset_fonts(verbose=True)
doc.ez_save(__file__.replace(".py", ".pdf"))

色付きのテキストを抽出する方法¶
テキストブロックを繰り返し処理し、必要な情報のテキストスパンを見つけます。
for page in doc:
text_blocks = page.get_text("dict", flags=pymupdf.TEXTFLAGS_TEXT)["blocks"]
for block in text_blocks:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
color = pymupdf.sRGB_to_rgb(span["color"])
print(f"Text: {text}, Color: {color}")