画像¶
ドキュメントページから画像を作成する方法¶
この小さなスクリプトは、文書のファイル名を取得し、各ページからPNGファイルを生成します。
文書の種類は、サポートされている どんな形式でも構いません。
このスクリプトはコマンドラインツールとして動作し、ファイル名をパラメータとして指定することを期待しています。生成された画像ファイル(1ページごとに1つ)は、スクリプトが格納されているディレクトリに保存されます。:
import sys, pymupdf # import the bindings
fname = sys.argv[1] # get filename from command line
doc = pymupdf.open(fname) # open document
for page in doc: # iterate through the pages
pix = page.get_pixmap() # render page to an image
pix.save(f"page-{page.number}.png") # store image as a PNG
スクリプトのディレクトリには、これから page-0.png 、 page-1.png などという名前のPNG画像ファイルが含まれるようになります。画像は各ページの寸法に合わせて整数に丸められた幅と高さを持ちます。例えば、A4縦向きのページであれば595 x 842ピクセルとなります。これらの画像は水平方向と垂直方向の解像度が96 dpiで、透明度はありません。これらの設定を変更することもできます。詳細については、次のセクションをお読みください。
画像の解像度を上げる方法¶
文書ページの画像はPixmapによって表されます。 Pixmap を作成するもっとも簡単な方法は、メソッド Page.get_pixmap() を使うことです。
このメソッドには結果に影響を与える多くのオプションがあります。その中でも最も重要なのは行列(Matrix)であり、これによって結果を拡大、回転、歪ませる、または反転することができます。
Page.get_pixmap() はデフォルトで Identity (アイデンティティ) 行列を使用しますが、これは何も行いません。
以下では、各次元に2倍のズームを適用し、結果として解像度が4倍向上した画像を生成します(そしてサイズも約4倍になります)。:
zoom_x = 2.0 # horizontal zoom
zoom_y = 2.0 # vertical zoom
mat = pymupdf.Matrix(zoom_x, zoom_y) # zoom factor 2 in each dimension
pix = page.get_pixmap(matrix=mat) # use 'mat' instead of the identity matrix
バージョン1.19.2以降では、解像度を設定するより直接的な方法があります。 "dpi" (インチあたりのドット数)というパラメータを "matrix" の代わりに使用することができます。ページの300 dpiの画像を作成するには、 pix = page.get_pixmap(dpi=300) と指定します。略記法の利便性に加えて、この方法の追加の利点は、dpiの値が画像ファイルとともに保存されることです。これはMatrixの記法を使用する場合に自動的に行われることはありません。
部分的なPixmap(クリップ)の作成方法¶
常にページの完全な画像が必要なわけではありませんし、必要ともしない場合があります。例えば、GUIで画像を表示し、ページのズームされた部分でウィンドウを埋めたい場合などが該当します。
GUIウィンドウにフルの文書ページを表示するスペースがあると仮定しましょうが、現在はページの右下の四分の一でこのスペースを埋めたいとします。これにより、解像度が4倍向上します。
これを実現するために、GUIに表示したい領域に等しい矩形を定義し、「クリップ」と呼びます。PyMuPDFでは、矩形を構築する方法の1つは、対角線上にある2つの角を指定することです。これがここで行っていることです。

mat = pymupdf.Matrix(2, 2) # zoom factor 2 in each direction
rect = page.rect # the page rectangle
mp = (rect.tl + rect.br) / 2 # its middle point, becomes top-left of clip
clip = pymupdf.Rect(mp, rect.br) # the area we want
pix = page.get_pixmap(matrix=mat, clip=clip)
上記では、 clip を構築するために、2つの対角線上の点を指定しています:ページ矩形の中心点である mp と、その右下の点である rect.br です。
GUIウィンドウにクリップをズームする方法¶
前のセクションもお読みください。今回は、クリップのズームファクターを計算して、その画像が指定されたGUIウィンドウに最適にフィットするようにします。つまり、画像の幅または高さ(または両方)がウィンドウの寸法と等しくなります。次のコードスニペットでは、GUIウィンドウのWIDTHとHEIGHTを提供する必要があります。それらはページのクリップ矩形を受け取る必要があります。
# WIDTH: width of the GUI window
# HEIGHT: height of the GUI window
# clip: a subrectangle of the document page
# compare width/height ratios of image and window
if clip.width / clip.height < WIDTH / HEIGHT:
# clip is narrower: zoom to window HEIGHT
zoom = HEIGHT / clip.height
else: # clip is broader: zoom to window WIDTH
zoom = WIDTH / clip.width
mat = pymupdf.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, clip=clip)
逆の場合は、ズームファクターがあると仮定し、フィッティングクリップを計算する必要があります。
この場合、 zoom = HEIGHT/clip.height = WIDTH/clip.width となるので、 clip.height = HEIGHT/zoom および clip.width = WIDTH/zoom と設定する必要があります。クリップ内のページ上の左上の点 tl を選択して、適切なピクマップを計算します。
width = WIDTH / zoom
height = HEIGHT / zoom
clip = pymupdf.Rect(tl, tl.x + width, tl.y + height)
# ensure we still are inside the page
clip &= page.rect
mat = pymupdf.Matrix(zoom, zoom)
pix = pymupdf.Pixmap(matrix=mat, clip=clip)
注釈画像の作成または抑制方法¶
通常、ページのピクマップにはページの注釈も表示されます。しかし、時にはこれが望ましくない場合があります。
描画されたページから注釈画像を抑制するには、 Page.get_pixmap() で annots=False を指定します。
注釈を個別にレンダリングすることもできます。注釈には独自の Annot.get_pixmap() メソッドがあります。結果のピクマップは注釈の矩形と同じ寸法です。
画像の抽出方法:非PDFドキュメント¶
前のセクションとは対照的に、このセクションではドキュメントに含まれる画像の抽出に取り組みます。これにより、これらの画像を1つ以上のページの一部として表示することができます。
元の画像をファイル形式またはメモリ領域として再作成したい場合、基本的に2つのオプションがあります:
ドキュメントをPDFに変換し、その後PDF専用の抽出方法のいずれかを使用します。以下のスニペットはドキュメントをPDFに変換します:
>>> pdfbytes = doc.convert_to_pdf() # this a bytes object >>> pdf = pymupdf.open("pdf", pdfbytes) # open it as a PDF document >>> # now use 'pdf' like any PDF document
「dict」パラメータを使って
Page.get_text()を使用します。これはすべてのドキュメントタイプに対して機能します。これにより、ページに表示されているすべてのテキストと画像がPythonの辞書としてフォーマットされて抽出されます。各画像は、メタ情報とバイナリ画像データを含む画像ブロックに含まれます。辞書の構造の詳細については、 TextPage (テキストページ) を参照してください。この方法はPDFファイルにも同じくうまく機能します。これにより、ページに表示されているすべての画像のリストが作成されます:>>> d = page.get_text("dict") >>> blocks = d["blocks"] # the list of block dictionaries >>> imgblocks = [b for b in blocks if b["type"] == 1] >>> pprint(imgblocks[0]) {'bbox': (100.0, 135.8769989013672, 300.0, 364.1230163574219), 'bpc': 8, 'colorspace': 3, 'ext': 'jpeg', 'height': 501, 'image': b'\xff\xd8\xff\xe0\x00\x10JFIF\...', # CAUTION: LARGE! 'size': 80518, 'transform': (200.0, 0.0, -0.0, 228.2460174560547, 100.0, 135.8769989013672), 'type': 1, 'width': 439, 'xres': 96, 'yres': 96}
画像の抽出方法:PDFドキュメント¶
PDF内の他のオブジェクトと同様に、画像は交差参照番号( xref 、整数)によって識別されます。この番号を知っていれば、画像のデータにアクセスする方法が2つあります:
画像の Pixmap を作成します。指示:
pix = pymupdf.Pixmap(doc, xref)。この方法は非常に高速です(単桁のマイクロ秒)。 Pixmap のプロパティ(幅、高さなど)は、画像のものと同じになります。この場合、埋め込まれたオリジナルの画像形式を判別する方法はありません。画像を抽出します。指示:
img = doc.extract_image(xref)。これはバイナリ画像データを含む辞書です。多くのメタデータも提供されますが、主に画像の Pixmap で見つけることができるものとほぼ同じです。主な違いは、文字列 img["ext"] であり、画像形式を指定します。"png" 以外にも "jpeg" 、 "bmp"、 "tiff" などの文字列が出現することがあります。ディスクに保存する場合は、この文字列をファイル拡張子として使用します。このメソッドの実行速度は、以下のステートメントの組み合わせ速度pix = pymupdf.Pixmap(doc, xref);pix.tobytes()と比較する必要があります。埋め込まれた画像がPNG形式の場合、Document.extract_image()の速度はほぼ同じで(バイナリ画像データも同じです)、それ以外の場合は、このメソッドは数千倍高速であり、画像データも小さくなります
「どのようにして画像の'xref'番号を知るのか?」 これには2つの答えがあります:
「ページオブジェクトを検査する」 :
Page.get_images()の項目をループ処理します。これはリストのリストであり、項目は[xref、smask、...]のようになっており、画像のxrefを含んでいます。このxrefを上記の方法の1つで使用できます。これは有効(損傷していない)なドキュメントに使用しますが、同じ画像が複数回(異なるページで)参照されることがあるため、複数回の抽出を避けるメカニズムを提供することが望ましいかもしれません。「知る必要はありません」:ドキュメントのすべての
xrefのリストをループ処理し、各xrefに対してDocument.extract_image()を実行します。返される辞書が空であれば、続けて次のxrefを処理します。このxrefは画像ではありません。これはPDFが損傷している(使用できないページがある)場合に使用します。PDFにはしばしば他の画像の透明度を定義する特別な目的の「擬似画像」(ステンシルマスク)が含まれていることに注意してください。これらを抽出から除外するためのロジックを提供することがあるかもしれません。次のセクションも参照してください。
これらの抽出方法の両方に対して、一般的な用途のスクリプトが存在します。
extract-from-pages.py はページごとに画像を抽出します。
extract-from-xref.py はxrefテーブルによって画像を抽出します。
画像マスクの処理方法¶
PDF内の一部の画像には画像マスクが付属しています。最も単純な形式では、マスクは別の画像として格納されたアルファ(透明度)バイトを表します。画像の元の形を復元するには、そのマスクから取得した透明度バイトを使用して画像を「補完」する必要があります。
PyMuPDFでは、画像にそのようなマスクがあるかどうかは次の2つの方法で認識できます:
Document.get_page_images()の項目は一般的な形式(xref、smask、...)を持ちます。ここで、xrefは画像のxrefであり、 「smask」 が正の場合、それはマスクのxrefです。Document.extract_image()の結果(辞書)には、キー「smask」があります。このキーには、マスクのxrefが含まれています。
smask == 0 の場合、 xref を介して遭遇した画像はそのまま処理できます。
PyMuPDFを使用して元の画像を復元するためには、以下に示す手順を実行する必要があります:
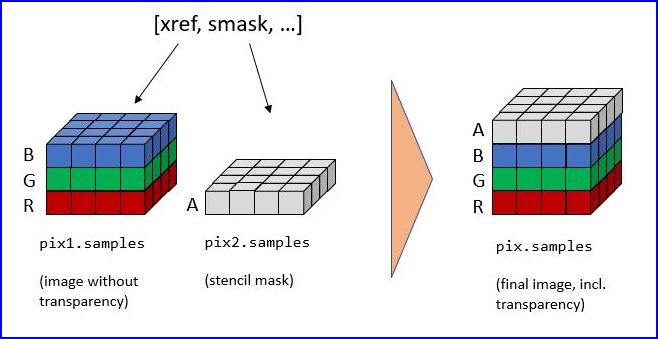
>>> pix1 = pymupdf.Pixmap(doc.extract_image(xref)["image"]) # (1) pixmap of image w/o alpha
>>> mask = pymupdf.Pixmap(doc.extract_image(smask)["image"]) # (2) mask pixmap
>>> pix = pymupdf.Pixmap(pix1, mask) # (3) copy of pix1, image mask added
ステップ(1)では、基本画像のピクマップを作成します。ステップ(2)では、同じことを画像マスクで行います。ステップ(3)では、アルファチャンネルを追加し、透明情報で埋めます。
また、上記の extract-from-pages.py および extract-from-xref.py というスクリプトにもこのロジックが含まれています。
すべての写真(またはファイル)を1つのPDFにする方法¶
以下に、(画像およびその他の)ファイルのリストを受け取り、それらをすべて1つのPDFに結合する3つのスクリプトを示します。
方法1:画像をページとして挿入する方法
最初の方法では、各画像を同じ寸法のPDFページに変換します。結果は、1つの画像に1ページのPDFとなります。ただし、 サポートされている 画像ファイル形式のみで動作します。:
import os, pymupdf
import PySimpleGUI as psg # for showing a progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where the pics are
imglist = os.listdir(imgdir) # list of them
imgcount = len(imglist) # pic count
for i, f in enumerate(imglist):
img = pymupdf.open(os.path.join(imgdir, f)) # open pic as document
rect = img[0].rect # pic dimension
pdfbytes = img.convert_to_pdf() # make a PDF stream
img.close() # no longer needed
imgPDF = pymupdf.open("pdf", pdfbytes) # open stream as PDF
page = doc.new_page(width = rect.width, # new page with ...
height = rect.height) # pic dimension
page.show_pdf_page(rect, imgPDF, 0) # image fills the page
psg.EasyProgressMeter("Import Images", # show our progress
i+1, imgcount)
doc.save("all-my-pics.pdf")
これにより、結合された画像のサイズとほとんど変わらないPDFが生成されます。パフォーマンスに関するいくつかの数値:
上記のスクリプトは、149枚の画像で合計サイズが514 MBの場合、私のマシン上で約1分かかりました(生成されたPDFのサイズもほぼ同じです)。

より完全なソースコードは こちら をご覧ください:ディレクトリ選択ダイアログを提供し、サポートされていないファイルやファイルでないエントリをスキップします。
注釈
Page.insert_image() の代わりに Page.show_pdf_page() を使用することもできましたが、結果として似たような外観のファイルになります。ただし、画像の種類によっては、非圧縮で画像を保存する場合があります。そのため、適切なファイルサイズを得るためには、保存オプションとして deflate = True を使用する必要がありますが、これにより大量の画像の場合、実行時間が大幅に増加します。そのため、この代替方法はお勧めできません。
方法2:ファイルの埋め込み
2つ目のスクリプトは、画像だけでなく、任意のファイルを埋め込みます。技術的な理由で必要なので、結果として得られるPDFには1つだけ(空の)ページがあります。埋め込まれたファイルに後でアクセスするためには、埋め込まれたファイルを表示または抽出できる適切なPDFビューアが必要です:
import os, pymupdf
import PySimpleGUI as psg # for showing progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where my files are
imglist = os.listdir(imgdir) # list of pictures
imgcount = len(imglist) # pic count
imglist.sort() # nicely sort them
for i, f in enumerate(imglist):
img = open(os.path.join(imgdir,f), "rb").read() # make pic stream
doc.embfile_add(img, f, filename=f, # and embed it
ufilename=f, desc=f)
psg.EasyProgressMeter("Embedding Files", # show our progress
i+1, imgcount)
page = doc.new_page() # at least 1 page is needed
doc.save("all-my-pics-embedded.pdf")

これは断然最も高速な方法であり、可能な限り最小の出力ファイルサイズを生成します。上記の画像は私のマシンで20秒かかり、PDFのサイズは510 MBになりました。より完全なソースコードは こちら をご覧ください:ディレクトリ選択ダイアログを提供し、ファイルでないエントリをスキップします。
方法3:ファイルの添付
このタスクを達成する第3の方法は、ページの注釈を介してファイルを添付する方法です。完全なソースコードについては こちら をご覧ください。
これは前のスクリプトと同様のパフォーマンスを持ち、似たようなファイルサイズも生成します。それぞれの添付ファイルに対して「FileAttachment」アイコンが表示されるPDFページを生成します。
注釈
埋め込みと添付の両方の方法は、画像だけでなく任意のファイルにも使用できます。
注釈
長時間にわたるタスクに対して進捗メーターを表示するために、素晴らしいパッケージ PySimpleGUI の使用を強くお勧めします。これは純粋なPythonであり、Tkinter(追加のGUIパッケージは不要)を使用し、たった1行のコードを追加するだけで使えます!
ベクター画像の作成方法¶
ドキュメントページから画像を作成する通常の方法は、 Page.get_pixmap() を使用することです。ピクマップはラスター画像を表しますので、作成時にその品質(つまり解像度)を決定する必要があります。後から変更することはできません。
PyMuPDFはまた、SVG形式(XML構文で定義されたスケーラブルベクターグラフィックス)でページのベクター画像を作成する方法を提供しています。SVG画像はズームレベルで正確性を保持します(もちろん、埋め込まれたラスターグラフィックス要素を除く)。
指示 svg = page.get_svg_image(matrix=pymupdf.Identity) はUTF-8文字列 svg を提供します。これは ".svg" の拡張子で保存できます。
画像の変換方法¶
PyMuPDFの画像変換も他の機能と同様に簡単です。多くの場合、PIL/Pillowなどの他のグラフィックスパッケージを使用する必要がないかもしれません。
ただし、Pillowとの連携はほとんど自明です。
入力フォーマット |
出力フォーマット |
説明 |
|---|---|---|
BMP |
. |
Windows Bitmap |
JPEG |
JPEG |
Joint Photographic Experts Group |
JXR |
. |
JPEG Extended Range |
JPX/JP2 |
. |
JPEG 2000 |
GIF |
. |
Graphics Interchange Format |
TIFF |
. |
Tagged Image File Format |
PNG |
PNG |
Portable Network Graphics |
PNM |
PNM |
Portable Anymap |
PGM |
PGM |
Portable Graymap |
PBM |
PBM |
Portable Bitmap |
PPM |
PPM |
Portable Pixmap |
PAM |
PAM |
Portable Arbitrary Map |
. |
PSD |
Adobe Photoshop Document |
. |
PS |
Adobe Postscript |
一般的なスキームは以下の2行です:
pix = pymupdf.Pixmap("input.xxx") # any supported input format
pix.save("output.yyy") # any supported output format
コメント
pymupdf.Pixmap(arg)の入力引数は、画像を含むファイルまたはbytes/io.BytesIOオブジェクトを指定できます。出力ファイルの代わりに、
pix.tobytes("yyy")を使用してbytesオブジェクトを作成し、それを渡すこともできます。もちろん、入力と出力のフォーマットは、色空間と透過性の面で互換性が必要です。 Pixmap クラスには、必要に応じて調整を行うための組み込みの機能が備わっています。
注釈
JPEGをPhotoshopに変換する:
pix = pymupdf.Pixmap("myfamily.jpg")
pix.save("myfamily.psd")
注釈
アルファ付きのPNGをTkinterのPhotoImageに変換してください。これには、PPMへの変換を行う前にアルファバイトを削除する必要があります。
import tkinter as tk
pix = pymupdf.Pixmap("input.jpg") # or any RGB / no-alpha image
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
注釈
アルファ付きのPNGをTkinterのPhotoImageに変換します。このためには、PPMへの変換を行う前にアルファバイトを取り除く必要があります。
import tkinter as tk
pix = pymupdf.Pixmap("input.png") # may have an alpha channel
if pix.alpha: # we have an alpha channel!
pix = pymupdf.Pixmap(pix, 0) # remove it
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
ピクスマップの使用方法:画像の結合¶
これは、ピクスマップを純粋にグラフィカルで、文書ではない目的で使用する方法を示しています。スクリプトは画像ファイルを読み込み、元の画像の3 * 4タイルからなる新しい画像を作成します。
import pymupdf
src = pymupdf.Pixmap("img-7edges.png") # create pixmap from a picture
col = 3 # tiles per row
lin = 4 # tiles per column
tar_w = src.width * col # width of target
tar_h = src.height * lin # height of target
# create target pixmap
tar_pix = pymupdf.Pixmap(src.colorspace, (0, 0, tar_w, tar_h), src.alpha)
# now fill target with the tiles
for i in range(col):
for j in range(lin):
src.set_origin(src.width * i, src.height * j)
tar_pix.copy(src, src.irect) # copy input to new loc
tar_pix.save("tar.png")
これが入力画像です。

こちらが出力結果です。

ピクスマップの使用方法:フラクタルの作成¶
ここでは、もう一つのピクスマップの例を紹介します。シェルピンスキーのカーペット(Sierpinski's Carpet)と呼ばれるフラクタルで、カントール集合を2次元に一般化したものです。正方形のカーペットにおいて、9つの部分正方形(3行3列)をマークし、中央の正方形を切り抜きます。残りの8つの部分正方形に対しても同じ操作を行い、無限に続けます。その結果、面積がゼロであり、フラクタル次元は1.8928...となります。
このスクリプトは、1ピクセルの精度にまで細かくなったPNGの近似画像を作成します。画像の精度を高めるには、n(精度)の値を変更してください:
import pymupdf, time
if not list(map(int, pymupdf.VersionBind.split("."))) >= [1, 14, 8]:
raise SystemExit("need PyMuPDF v1.14.8 for this script")
n = 6 # depth (precision)
d = 3**n # edge length
t0 = time.perf_counter()
ir = (0, 0, d, d) # the pixmap rectangle
pm = pymupdf.Pixmap(pymupdf.csRGB, ir, False)
pm.set_rect(pm.irect, (255,255,0)) # fill it with some background color
color = (0, 0, 255) # color to fill the punch holes
# alternatively, define a 'fill' pixmap for the punch holes
# this could be anything, e.g. some photo image ...
fill = pymupdf.Pixmap(pymupdf.csRGB, ir, False) # same size as 'pm'
fill.set_rect(fill.irect, (0, 255, 255)) # put some color in
def punch(x, y, step):
"""Recursively "punch a hole" in the central square of a pixmap.
Arguments are top-left coords and the step width.
Some alternative punching methods are commented out.
"""
s = step // 3 # the new step
# iterate through the 9 sub-squares
# the central one will be filled with the color
for i in range(3):
for j in range(3):
if i != j or i != 1: # this is not the central cube
if s >= 3: # recursing needed?
punch(x+i*s, y+j*s, s) # recurse
else: # punching alternatives are:
pm.set_rect((x+s, y+s, x+2*s, y+2*s), color) # fill with a color
#pm.copy(fill, (x+s, y+s, x+2*s, y+2*s)) # copy from fill
#pm.invert_irect((x+s, y+s, x+2*s, y+2*s)) # invert colors
return
#==============================================================================
# main program
#==============================================================================
# now start punching holes into the pixmap
punch(0, 0, d)
t1 = time.perf_counter()
pm.save("sierpinski-punch.png")
t2 = time.perf_counter()
print (f"{round(t1-t0,3)} sec to create / fill the pixmap")
print (f"{round(t2-t1,3)} sec to save the image")
結果は以下のようになるはずです:

NumPyとのインターフェース方法¶
これは、NumPy配列からPNGファイルを作成する方法を示しています(他の方法よりも数倍高速です)。
import numpy as np
import pymupdf
#==============================================================================
# create a fun-colored width * height PNG with pymupdf and numpy
#==============================================================================
height = 150
width = 100
bild = np.ndarray((height, width, 3), dtype=np.uint8)
for i in range(height):
for j in range(width):
# one pixel (some fun coloring)
bild[i, j] = [(i+j)%256, i%256, j%256]
samples = bytearray(bild.tostring()) # get plain pixel data from numpy array
pix = pymupdf.Pixmap(pymupdf.csRGB, width, height, samples, alpha=False)
pix.save("test.png")
PDFページに画像を追加する方法¶
PDFページに画像を追加するには、2つの方法があります: Page.insert_image() と Page.show_pdf_page() です。両方の方法には共通点がありますが、違いもあります。
基準 |
||
|---|---|---|
表示可能なコンテンツ |
画像ファイル、メモリ内の画像、ピクスマップ |
PDFページ |
表示解像度 |
画像の解像度 |
ベクトル化(ラスターページコンテンツを除く) |
回転 |
0度、90度、180度または270度 |
任意の角度 |
クリッピング |
いいえ(全体の画像のみ) |
はい |
アスペクト比を保持 |
はい(デフォルトオプション) |
はい(デフォルトオプション) |
透明性(ウォーターマーキング) |
画像による |
ページによる |
位置/配置 |
ターゲットの矩形にフィットするようにスケーリング |
ターゲットの矩形にフィットするようにスケーリング |
パフォーマンス |
重複の自動防止 |
重複の自動防止 |
マルチページ画像のサポート |
いいえ |
はい |
使いやすさ |
シンプルで直感的 |
シンプルで直感的; |
Page.insert_image() の基本的なコードパターン。 filename / stream / pixmap のうち、1つだけを指定する必要があります(既存の画像を再挿入しない場合):
page.insert_image(
rect, # where to place the image (rect-like)
filename=None, # image in a file
stream=None, # image in memory (bytes)
pixmap=None, # image from pixmap
mask=None, # specify alpha channel separately
rotate=0, # rotate (int, multiple of 90)
xref=0, # re-use existing image
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
Page.show_pdf_page() の基本的なコードパターン。ソースとターゲットのPDFは異なる Document (ドキュメント) オブジェクトである必要があります(ただし、同じファイルから開くこともできます):
page.show_pdf_page(
rect, # where to place the image (rect-like)
src, # source PDF
pno=0, # page number in source PDF
clip=None, # only display this area (rect-like)
rotate=0, # rotate (float, any value)
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
ピクスマップの使用方法:テキストの表示可否の確認¶
特定のテキストが実際にページ上で表示されるかどうかは、いくつかの要因に依存します:
テキストは他のオブジェクトによって隠されていないが、背景と同じ色を持っている場合があります。例えば、白文字が白地になっているなどです。
テキストは画像やベクトルグラフィックスによって隠されている場合があります。これを検出することは重要な機能であり、例えば不適切に匿名化された法的文書を解明するために使用されます。
テキストが非表示に作成される場合があります。これは通常、OCRツールが認識されたテキストをページ上の非表示レイヤーに保存するために使用されます。
以下では、1.の状況を検出する方法、または2.の状況を検出する方法(カバーしているオブジェクトが単色である場合)を示します:
pix = page.get_pixmap(dpi=150) # make page image with a decent resolution
# the following matrix transforms page to pixmap coordinates
mat = page.rect.torect(pix.irect)
# search for some string "needle"
rlist = page.search_for("needle")
# check the visibility for each hit rectangle
for rect in rlist:
if pix.color_topusage(clip=rect * mat)[0] > 0.95:
print("'needle' is invisible here:", rect)
メソッド Pixmap.color_topusage() は、タプル (ratio, pixel) (比率、ピクセル)を返します。ここで、0 < ratio <= 1であり、pixelは色のピクセル値です。複数のヒット矩形がある場合、ピクスマップを1回だけ作成することに注意してください。これにより、処理時間を大幅に節約できます。
上記のコードのロジックは次の通りです:もしニードルの矩形が「ほぼ」(95%以上)単色であれば、テキストは表示されないと判断します。テキストが表示される場合の典型的な結果は、背景の色(主に白)と比率が0.7から0.8程度で返されることがあります。例えば、(0.685, b'xffxffxff') のような結果が得られます。