Page (ページ)¶
ドキュメントページを表すクラス。ページオブジェクトは Document.load_page() またはドキュメントをインデックスで参照することで作成されます(例: doc[n] ) - 独立したコンストラクタはありません。
ドキュメントとそのページとの親子関係があります。ドキュメントが閉じられるか削除されると、存在するすべてのページオブジェクト(およびそれに関連する子供たちも)が使用できなくなります(「孤児」になります)。ページのプロパティまたはメソッドを使用している場合、例外が発生します。
便宜のために、いくつかのページメソッドには Document (ドキュメント) の対応するメソッドがあります。この章の最後に概要があります。
注釈
この章では何度も 「座標」 という用語を使用しています。それが何を意味するかを少なくとも基本的な理解があること、そして 脚注 のセクションに慣れていることが非常に重要です。
ページの修正¶
ページのプロパティを変更し、ページの内容を追加または変更することは、PDFドキュメントのみで使用可能です。
要するに、PyMuPDFでできることは次のとおりです:
ページの回転とページの可視部分(「クロップボックス」)の変更。
画像、他のPDFページ、テキスト、単純な幾何学的オブジェクトの挿入。
アノテーションとフォームフィールドの追加。
注釈
メソッドには、コンテンツを所望の場所に配置するために座標(ポイント、矩形)が必要です。v1.17.0以降、これらの座標は常に 回転していない ページに対して提供する 必要があります。逆もまた真実です:Page.rect, resp. Page.bound() を除いて(ページが回転したときを 反映 しています)、メソッドと属性が返すすべての座標は回転していないページに関連しています。
したがって、Page.get_image_bbox() などのメソッドの返される値は、Page.set_rotation()を実行しても変更されません。同じことが Page.get_text()、アノテーションの矩形などから返される座標にも当てはまります。オブジェクトが 回転した座標 でどこにあるかを調べたい場合は、座標を:attr:Page.rotation_matrix で乗算します。Page.derotation_matrix とその逆行列もあり、他のリーダーと連携する際に使用できます。この点で異なる動作をするかもしれません。
注釈
ページに注釈、リンク、またはフォームフィールドを追加または更新し、直後にこれらの新しいまたは更新されたアイテムを操作する必要がある場合(つまり ページを離れずに)、Document.reload_page() を使用してページを再読み込みする必要があります。
一般的にはページを再読み込みすることをお勧めしますが、すべてのケースで厳密に必要とされるわけではありません。ただし、PyMuPDFの注釈とウィジェットの種類の一部は、MuPDFと比較して拡張機能を持っています。今後もこれらの拡張機能が増えるかもしれません
ページを再読み込むことで、変更がPDF構造に完全に適用され、Pixa画像を作成したり、アノテーション、リンク、フォームフィールドを正常にイテレートしたりできるようになります。
メソッド / 属性 |
短い説明 |
|---|---|
PDFのみ:キャレットアノテーションを追加します |
|
PDFのみ:円注釈を追加します |
|
PDFのみ:ファイル添付アノテーションを追加します |
|
PDFのみ:テキストアノテーションを追加します |
|
PDFのみ:「ハイライト」アノテーションを追加します |
|
PDFのみ:インク注釈を追加します |
|
PDFのみ:線アノテーションを追加します |
|
PDFのみ:多角形アノテーションを追加します |
|
PDFのみ:多線アノテーションを追加します |
|
PDFのみ:四角アノテーション釈を追加します |
|
PDFのみ:黒塗りアノテーションを追加します |
|
PDFのみ:「波線」アノテーションを追加します |
|
PDFのみ:「スタンプ」アノテーションを追加します |
|
PDFのみ:「取り消し線」アノテーションを追加します |
|
PDFのみ:コメントを追加します |
|
PDFのみ:「下線」アノテーションを追加します |
|
PDFのみ:PDFフォームフィールドを追加します |
|
PDFのみ:アノテーション(およびウィジェット)の名前のリスト |
|
PDFのみ:アノテーション(およびウィジェット)のxrefのリスト |
|
ページ上のアノテーションのジェネレーターを返します |
|
PDFのみ:ページの塗りつぶしを処理します |
|
PDF only: remove page content outside a rectangle |
|
ページの矩形 |
|
PDFのみ:ベクトルグラフィックスの境界ボックス |
|
PDFのみ:アノテーションを削除します |
|
PDFのみ:画像を削除します |
|
PDFのみ:リンクを削除します |
|
PDFのみ:ウィジェット/フィールドを削除します |
|
PDFのみ:三次ベジエ曲線を描画します |
|
PDFのみ:円を描画します |
|
PDFのみ:特別なベジエ曲線を描画します |
|
PDFのみ:直線を描画します |
|
PDFのみ:楕円を描画します |
|
PDFのみ:点のシーケンスを接続します |
|
PDF のみ: クアッドを描く |
|
PDFのみ:四角形を描画します |
|
PDFのみ:円セクタを描画します |
|
PDFのみ:波線を描画します |
|
PDFのみ:ジグザグ線を描画します |
|
ページ上のテーブルを検出します |
|
ページ上のベクトルグラフィックを取得します |
|
PDFのみ:参照されたフォントのリストを取得 |
|
PDFのみ:埋め込まれた画像のバウンディングボックスと行列を取得 |
|
使用されるすべての画像のメタ情報のリストを取得 |
|
PDFのみ: |
|
PDFのみ:参照された画像のリストを取得 |
|
PDFのみ:ページのラベルを返す |
|
すべてのリンクを取得 |
|
ラスターフォーマットのページイメージを作成 |
|
SVGフォーマットのページイメージを作成 |
|
ページのテキストを抽出 |
|
特定の矩形に含まれるテキストを抽出 |
|
ページのOCR付きのTextPageを作成 |
|
ページのTextPageを作成 |
|
PDFのみ:参照されたxobjectのリストを取得 |
|
PDFのみ:ページで使用するフォントを挿入 |
|
PDFのみ:画像を挿入 |
|
PDFのみ:リンクを挿入 |
|
PDFのみ:テキストを挿入 |
|
PDFのみ: 指定された矩形にテキストを追加します。 |
|
PDFのみ:テキストボックスを挿入 |
|
ページ上のリンクのジェネレータを返す |
|
PDFのみ:特定のアノテーションを読み込む |
|
PDFのみ:特定のフィールドを読み込む |
|
ページ上の最初のリンクを返す |
|
PDFのみ:新しい Shape(シェイプ) を作成 |
|
PDF only: change the colorspace of objects |
|
PDF only: set page rotation to 0 |
|
PDFのみ:画像を置換 |
|
文字列を検索 |
|
PDFのみ: |
|
PDFのみ:/BleedBoxを変更 |
|
PDFのみ: |
|
PDFのみ:/MediaBoxを変更 |
|
PDFのみ:ページの回転を設定 |
|
PDFのみ: |
|
PDFのみ:PDFページ画像を表示 |
|
PDFのみ:リンクを変更 |
|
ページ上のフィールドのジェネレータを返す |
|
1つ以上の TextWriter (テキストライター) オブジェクトを書き込む |
|
|
|
ページの |
|
ページの |
|
ページの |
|
ページの |
|
PDFのみ:回転されていないページ空間内の座標を取得 |
|
ページ上の最初の Annot (注釈) |
|
ページ上の最初の Link (リンク) |
|
ページ上の最初のウィジェット(フォームフィールド) |
|
|
|
ページの |
|
ページ番号 |
|
所属するドキュメントオブジェクト |
|
ページの矩形 |
|
PDFのみ:回転したページ空間内の座標を取得 |
|
PDFのみ:ページの回転 |
|
PDFのみ:PDFとMuPDFのスペース間を変換 |
|
PDFのみ:ページの |
クラス API
- class Page¶
- bound()¶
ページの長方形を決定します。下記の
Page.rectプロパティと同じです。PDF文書の場合、通常はmediaboxとcropboxと一致しますが、常にそうとは限りません。たとえば、ページが回転している場合、このメソッドに反映されますが、Page.cropboxは変更されません。- 戻り値の型:
- add_caret_annot(point)¶
PDFのみ: ケアットアイコンを追加します。ケアットアノテーションは通常、ページ上でテキストの編集が存在することを示すために使用される視覚的なシンボルです
- パラメータ:
point (point_like) -- point (point_like) – MuPDFが提供するアイコンを含む20 x 20の長方形の左上のポイント。
- 戻り値の型:
- 戻り値:
作成されたアノテーション。ストロークの色は青=(0, 0, 1)で、塗りつぶしの色はサポートされていません。

Show/hide history
v1.16.0で新たに追加された
- add_text_annot(point, text, icon='Note')¶
PDFのみ: コメントアイコン(「付箋」)を追加し、それに関連するテキストを含めます。アイコンのみが表示され、関連するテキストは非表示で、多くのPDFビューアではアイコンの上にマウスを重ねることで可視化できます。
- パラメータ:
point (point_like) -- 提供されたMuPDFアイコンが含まれる20 x 20の矩形の左上の点。
text (str) -- コメントテキスト。これはダブルクリックまたはアイコンの上にカーソルを合わせることで表示されます。ラテン文字を含むことができます。
icon (str) -- (v1.16.0で新規追加) "Note"(デフォルト)、"Comment"、"Help"、"Insert"、"Key"、"NewParagraph"、"Paragraph" のいずれかを、具体的なテキストの視覚的なシンボルとして選択してください。 [4]
- 戻り値の型:
- 戻り値:
作成された注釈。ストロークカラーは黄色(1, 1, 0)、塗りつぶしカラーのサポートはありません。
- add_freetext_annot(rect, text, *, fontsize=11, fontname='helv', text_color=0, fill_color=None, border_width=0, dashes=None, callout=None, line_end=PDF_ANNOT_LE_OPEN_ARROW, opacity=1, align=TEXT_ALIGN_LEFT, rotate=0, richtext=False, style=None)¶
PDF only: Add text in a given rectangle. Optionally, the appearance of a "callout" shape can be requested by specifying two or three point-like objects -- see below.
- パラメータ:
rect (rect_like) -- the rectangle into which the text should be inserted. Text is automatically wrapped to a new line at box width. Text portions not fitting into the rectangle will be invisible without warning.
text (str) -- the text. May contain any mixture of Latin, Greek, Cyrillic, Chinese, Japanese and Korean characters. If
richtext=True(see below), the string is interpreted as HTML syntax. This adds a plethora of ways for attractive effects.fontsize (float) -- the
fontsize. Default is 11. Ignored ifrichtext=True.fontname (str) --
The font name. Default is "Helv". Ignored if
richtext=True, otherwise the following restritions apply:Accepted alternatives are "Helv" (Helvetica), "Cour" (Courier), "TiRo" (Timnes-Roman), "ZaDb" (ZapfDingBats) and "Symb" (Symbol). The name may be abbreviated to the first two characters, like "Co" for "Cour", lower case accepted.
Bold or italic variants of the fonts are not supported.
text_color (list,tuple,float) -- the text color. Default is black. Ignored if
richtext=True.fill_color (list,tuple,float) -- the fill color. This is used for
rectand the end point of the callout lines when applicable. Default isNone.border_color (list,tuple,float) -- This parameter only has an effect if
richtext=True. Otherwise,text_coloris used.border_width (float) -- the width of border and
calloutlines. Default is 0 (no border), in which case callout lines may still appear with some hairline width, depending on the PDF viewer used. In any case, this value must be positive to see a border line.dashes (list,tuple) -- a list of floats specifying how border and callout lines should be dashed. Default is
None.callout (list,tuple) -- a list / tuple of two or three
point_likeobjects, which will be interpreted as end point [, knee point] and start point (in this sequence) of up to two line segments, converting this annotation into a call-out shape.line_end (int) -- the line end symbol of the call-out line. It is drawn at the first point specified in the
calloutlist. Default is an open arrow. For possible values see 注釈の線の終端スタイル.opacity (float) -- a float
0 <= opacity < 1turning the annotation transparent. Default is no transparency.align (int) -- text alignment, one of TEXT_ALIGN_LEFT, TEXT_ALIGN_CENTER, TEXT_ALIGN_RIGHT - justify is not supported. Ignored if
richtext=True.rotate (int) -- the text orientation. Accepted values are integer multiples of 90°. Invalid entries receive a rotation of 0.
richtext (bool) -- treat
textas HTML syntax. This allows to achieve bold, italic, arbitrary text colors, font sizes, text alignment including justify and more - as far as the PDF subset of HTML and styling instructions supports this. This is similar to what happens inPage.insert_htmlbox(). The base library will for example pull in required fonts if it encounters characters not contained in the standard ones. Some parameters are ignored if this option is set, as mentioned above. Default isFalse.style (str) -- supply optional HTML styling information in CSS syntax. Ignored if
richtext=False.
- 戻り値の型:
- 戻り値:
the created annotation.
Show/hide history
v1.19.6で変更:境界色パラメータを追加
- add_file_annot(point, buffer_, filename, ufilename=None, desc=None, icon='PushPin')¶
PDFのみ: 指定された場所に「PushPin」アイコンを持つファイル添付注釈を追加します。
- パラメータ:
pos (point_like) -- ムPDFで提供される「PushPin」アイコンを含む18x18の四角形の左上のポイント。
buffer (bytes,bytearray,BytesIO) --
格納するデータ(実際のファイルコンテンツ、任意のデータなど)。
v1.14.13で変更: io.BytesIO もサポートされるようになりました。
filename (str) -- データに関連付けるファイル名。
ufilename (str) -- ファイルのPDF Unicodeバージョンのオプション。デフォルトはファイル名です。
desc (str) -- ファイルのオプションの説明。デフォルトはファイル名です。
icon (str) -- v1.16.0で新しく追加された)添付データの視覚的なシンボルとして、次のいずれかを選択します。"PushPin"(デフォルト)、"Graph"、"Paperclip"、"Tag" [4]。
- 戻り値の型:
- 戻り値:
作成された注釈。線の色は黄色(1, 1, 0)、塗りつぶしのサポートはありません。
- add_ink_annot(list)¶
PDFのみ: "freehand"の落書き注釈を追加します。
- パラメータ:
list (sequence) -- 1つまたは複数のリストからなり、それぞれが
point_likeアイテムを含むリストの1つです。これらのサブリスト内の各アイテムは、接続された線が描画される Point (ポイント) として解釈されます。したがって、個々のサブリストは別々の描画ラインを表します。- 戻り値の型:
- 戻り値:
作成された注釈はデフォルトの外観で黒色(0, 0, 0)で、線の幅は1です。塗りつぶしのサポートはありません。
- add_line_annot(p1, p2)¶
PDFのみ: 直線注釈を追加します。
- パラメータ:
p1 (point_like) -- 直線の開始点。
p2 (point_like) -- 直線の終点。
- 戻り値の型:
- 戻り値:
作成された注釈。線(ストローク)の色は赤色(1, 0, 0)で、線の幅は1です。塗りつぶしのサポートはありません。アノテーションの四角形 は、各点を囲む半径 3 * 線幅の円で作成され、各点の周りにシンボルの線の終わりのためのスペースを確保します。
- add_rect_annot(rect)¶
- add_circle_annot(rect)¶
PDFのみ: 長方形、または円の注釈を追加します。
- パラメータ:
rect (rect_like) -- 円または長方形が描かれる矩形。有限で空でない必要があります。矩形が正方形でない場合、楕円が描画されます。
- 戻り値の型:
- 戻り値:
作成された注釈。線(ストローク)の色は赤色(1、0、0)、線の幅は1で、塗りつぶしのサポートがあります
Redactions¶
- add_redact_annot(quad, text=None, fontname=None, fontsize=11, align=TEXT_ALIGN_LEFT, fill=(1, 1, 1), text_color=(0, 0, 0), cross_out=True)¶
PDF only: Add a redaction annotation. A redaction annotation identifies an area whose content should be removed from the document. Adding such an annotation is the first of two steps. It makes visible what will be removed in the subsequent step,
Page.apply_redactions().- パラメータ:
quad (quad_like,rect_like) -- 常に注釈の矩形と等しい削除する領域を指定します。これはrect_likeまたはquad_likeオブジェクトである必要があります。四角形が指定された場合、包括的な矩形が取られます。
text (str) -- (v1.16.12で新機能) 赤字を適用した後に矩形に配置するテキスト(従って古いコンテンツを削除します)。
fontname (str) -- the font to use when
textis given, otherwise ignored. Only CJK and the PDFベース14フォント are supported. Apart from this, the same rules apply as forPage.insert_textbox()-- which is what the methodPage.apply_redactions()internally invokes.fontsize (float) -- 置換テキストに使用する
fontsize。テキストが大きすぎて収まらない場合、fontsizeを4未満にならないように徐々に縮小して、複数の挿入試行が行われます。その後もテキストが収まらない場合、テキストの挿入は行われません。 (v1.16.12 で新規追加)align (int) -- the horizontal alignment for the replacing text. See
insert_textbox()for available values. The vertical alignment is (approximately) centered.fill (sequence) -- 適用後 の赤塗りの四角形の塗りつぶし色です。デフォルトは white = (1, 1, 1) で、
Noneが指定された場合も同様です。塗りつぶし色を抑制するには、Falseを指定します。この場合、四角形は透明のままです。(v1.16.12で新規追加)text_color (sequence) -- (新機能 v1.16.12) 置換テキストの色です。デフォルトは black = (0, 0, 0) です。
cross_out (bool) -- (新機能 v1.17.2) アノテーションの矩形に2つの対角線を追加します。
- 戻り値の型:
- 戻り値:
作成された注釈です。その標準的な外観は、赤い四角形(塗りつぶし色なし)であり、必要に応じて二つの対角線を表示します。色、線の太さ、破線、不透明度、およびブレンドモードは、他の注釈と同様に、
Annot.update()を介して設定および適用できます。(v1.17.2で変更)

Show/hide history
新機能 v1.16.11
- apply_redactions(images=PDF_REDACT_IMAGE_PIXELS | 2, graphics=PDF_REDACT_LINE_ART_REMOVE_IF_COVERED | 1, text=PDF_REDACT_TEXT_REMOVE | 0)¶
PDF only: Remove all content contained in any redaction rectangle on the page.
このメソッドは、ページからすべての赤塗りを適用して削除します。
- パラメータ:
images (int) -- How to redact overlapping images. The default
PDF_REDACT_IMAGE_PIXELS | 2blanks out overlapping pixels.PDF_REDACT_IMAGE_NONE | 0ignores, andPDF_REDACT_IMAGE_REMOVE | 1completely removes images overlapping any redaction annotation. OptionPDF_REDACT_IMAGE_REMOVE_UNLESS_INVISIBLE | 3only removes images that are actually visible.graphics (int) -- How to redact overlapping vector graphics (also called "line-art" or "drawings"). The default
PDF_REDACT_LINE_ART_REMOVE_IF_COVERED | 1removes any overlapping vector graphics.PDF_REDACT_LINE_ART_NONE | 0ignores, andPDF_REDACT_LINE_ART_REMOVE_IF_TOUCHED | 2removes graphics fully contained in a redaction annotation. When removing line-art, please be aware that stroked vector graphics (i.e. type "s" or "sf") have a larger wrapping rectangle than one might expect: first of all, at least 50% of the path's line width have to be added in each direction to truly include all of the drawing. If a so-called "miter limit" is provided (see page 121 of the PDF specification), the enlarging value ismiter * width / 2. So, when letting everything default (width = 1, miter = 10), the redaction rectangle should be at least 5 points larger in every direction.text (int) -- 重なるテキストを塗りつぶすかどうかを指定します。デフォルトでは、
PDF_REDACT_TEXT_REMOVE | 0は、境界ボックスが赤塗り四角形と重なるすべての文字を削除します。これは、元の法的/データ保護の意図に適合しています。ただし、他のユースケースでは、ベクトルグラフィックスや画像を赤塗りする一方で**テキストを保持**する必要がある場合があります。これは、text=True|PDF_REDACT_TEXT_NONE | 1を設定することで実現できます。これは、赤塗り注釈のデータ保護の意図には適合していませんので、自己責任で行ってください。
- 戻り値:
少なくとも1つの赤字注釈が処理された場合は
True、それ以外の場合はFalse。
注釈
赤塗りの四角に含まれるテキストは、物理的に ページから削除されます(適切なゴミオプションを使用したDocument.save()の場合)、テキスト抽出などの場所にはもはや表示されません。また、すべての赤塗りの注釈も削除されます。他の注釈には影響しません。
重なっているすべてのリンクは削除されます。リンクの四角がテキストを覆っている場合、テキストの重なる部分のみが削除されます。画像もリンクの四角によってカバーされている場合、同様のことが適用されます。
画像 の重なり部分は、デフォルトのオプションである
PDF_REDACT_IMAGE_PIXELSでは塗りつぶされます(v1.18.0で変更されました)。オプション0は画像を一切変更せず、1は重なり合う画像をすべて削除します。images=PDF_REDACT_IMAGE_REMOVEのオプションの場合、このページの 画像への参照 のみが削除されます。適切なゴミ収集オプションがあると、画像はファイルから完全に削除されます。images=PDF_REDACT_IMAGE_PIXELSのオプションでは、新しいPNG形式の画像が作成され、ページは元の画像の代わりにそれを使用します。このプロセスの一環として、元の画像は削除されず、他のページでは引き続き元の画像が表示される可能性があります。さらに、新しい変更されたPNG画像は現在 圧縮されていない状態で保存されています 。保存時に適切なゴミ収集メソッドと圧縮オプションを選択する際に、これらの側面を考慮してください。テキストの削除 は文字ごとに行われます:文字のbboxが赤塗りの四角と非空の重なりを持つ場合、文字が削除されます(MuPDF v1.17で変更)。フォントの特性や選択した行の高さに応じて、望ましくないテキスト部分が削除される場合があります。テキスト検索前に
Tools.set_small_glyph_heights()をTrue引数で使用して、これを防ぐのに役立つ場合があります。赤塗りは、PDF内の単語を置き換えるための簡単な方法であり、単語を物理的に削除するためのものです。テキスト抽出または検索方法を使用して単語「秘密」を見つけ、それぞれの出現ごとに代替テキスト「xxxxxx」を使用して赤塗りを挿入します。
注意が必要です。代替テキストが元のテキストよりも長い場合、見栄えが悪くなったり、改行が発生したり、新しいテキストがまったく表示されなくなる可能性があるためです。
いくつかの理由から、新しいテキストは古いテキストとまったく同じ行に配置されないことがあります。特に、代替フォントがCJKまたはPDF PDFベース14フォント の場合には特に当てはまります。
Show/hide history
新機能 v1.16.11
v1.16.12で変更:以前の mark パラメータは削除されました。代わりに、各赤字注釈の個々の塗りつぶし色で各赤字領域が塗りつぶされます。アノテーションで text が指定された場合、そのテキストを挿入するために、redactionで提供されたパラメータを使用して
insert_textbox()が呼び出されます。v1.18.0で変更:赤字領域と重なる画像を処理するためのオプションが追加されました。
Changed in v1.23.27: added option for removing graphics as well.
Changed in v1.24.2: added option
keep_textto leave text untouched.
- add_polyline_annot(points)¶
- add_polygon_annot(points)¶
PDFのみ:指定されたポイントを接続する線から成る注釈を追加します。多角形 (Polygon) の最初と最後のポイントは自動的に接続されますが、PolyLine ではそれが発生しません。各ポイントは半径3の円で囲まれた最小の 四角形 として自動的に作成されます(半径3 = 3 * 線の幅)。以下は、色や線端を変更した「PolyLine」の例を示しています。
- パラメータ:
points (list) -- points(list)–
point_likeオブジェクトのリスト。- 戻り値の型:
- 戻り値:
作成されたアノテーションです。線の色は黒で描画され、線の幅は1で、塗りつぶし色はサポートされています。このような外見を実現するために、Annot (注釈) のメソッドを使用して変更を加えることができます。

- add_underline_annot(quads=None, start=None, stop=None, clip=None)¶
- add_strikeout_annot(quads=None, start=None, stop=None, clip=None)¶
- add_squiggly_annot(quads=None, start=None, stop=None, clip=None)¶
- add_highlight_annot(quads=None, start=None, stop=None, clip=None)¶
PDFのみ: これらのアノテーションは通常、以前に何らかの方法で見つかったテキスト(たとえば、
Page.search_for()を使用して)をマーキングするために使用されます。ただし、これは必須ではありません:何でも「マーク」することができます。通常、アノテーションの種類ごとに標準の(ストロークのみで、塗りつぶし色はサポートされていません)色が選択されます。ハイライト用に 黄色、取り消し線用に 赤色、下線用に 緑色、波線下線用に マゼンタ色 です。
これらの四つのメソッドは、引数を Quad (クアッド) オブジェクトのリストに変換します。その後、アノテーション の矩形は、これらの四角形を包含するように計算されます。
注釈
search_for()は Rect (矩形) または Quad (クアッド) オブジェクトのリストを返します。このようなリストは、これらのアノテーションタイプの引数として直接使用でき、検索文字列のすべての出現に対して 共通のアノテーション を提供します:>>> # prefer quads=True in text searching for annotations! >>> quads = page.search_for("pymupdf", quads=True) >>> page.add_highlight_annot(quads)
注釈
明らかに、テキストマーカーアノテーションは、マークされる領域の上部、下部、左部、右部が何であるかを知る必要があります。引数がquadsの場合、この情報は四角形のポイントのシーケンスによって提供されます。対照的に、矩形ははるかに少ない情報を提供します - これは、四角形の四つの角を使用して24の異なる四角形が構築できるという事実によって示されています。
したがって、正しいアノテーションを確保するために、テキスト検索に
quadsオプションを使用することを 強くお勧めします。同様の考慮事項は、Page.get_text()の「dict」/「rawdict」オプションで抽出された テキストスパン をマークする場合にも適用されます。この場合の四角形の計算方法の詳細については、FAQ の「非水平テキストのマーキング方法」セクションを参照してください。- パラメータ:
quads (rect_like,quad_like,list,tuple) -- (v1.14.20で変更) マーキングする位置、つまり矩形または四角形。リストまたはタプルは、
rect_likeまたはquad_likeのアイテム(またはその混合)で構成されている必要があります。各アイテムは、適用可能な限り有限で凸面で空でなければなりません (v1.16.14で変更) 。このパラメータをNoneに設定すると、次の引数を使用できるようになります。逆もまたしかり:Noneでない場合、残りのパラメータはNoneでなければなりません。start (point_like) -- (v1.16.14で新規) このポイントでテキストマーキングを開始します。clip の左上のポイントがデフォルトです。
quadsがNoneの場合、提供する必要があります。stop (point_like) -- (v1.16.14で新規) このポイントでテキストマーキングを停止します。clip の右下のポイントがデフォルトです。quadsが
Noneの場合、使用する必要があります。clip (rect_like) -- (v1.16.14で新規) この領域と交差するテキスト行のみを考慮します。ページの矩形がデフォルトです。
startおよびstopが提供されている場合にのみ使用してください。
- 戻り値の型:
Annot (注釈) または (v1.16.14で変更)
None- 戻り値:
作成された注釈。 (v1.16.14で変更) quads が空のリストの場合、アノテーションは作成されません。
注釈
v1.16.14以降、開始、停止、および clip というパラメータを使用して、start と stop の間の連続した行をハイライトできます。clip を使用して、選択した行のbboxをさらに縮小し、たとえば多列のページを扱うことができます。次の多行のハイライトは、2つの赤いポイントを指定し、それに応じてクリップを設定することによって、3つのテキスト列を持つページに作成されました。

- cluster_drawings(clip=None, drawings=None, x_tolerance=3, y_tolerance=3, final_filter=True)¶
図形のクラスター(同義語は線画やドローイングです)を、幾何学的な近接性に基づいてグループ化します。このメソッドは、
Page.get_drawings()の出力を処理し、その中で、path["rect"]がある許容値(引数で指定された)よりも近いパスを結合します。結果は、各々が表(格子状の線がある)、円グラフ、棒グラフなどのものを包含する長方形のリストです。- パラメータ:
clip (rect_like) -- only consider paths inside this area. The default is the full page.
drawings (list) -- (任意)以前に生成された
Page.get_drawings()の出力を提供します。Noneの場合、メソッドが実行されます。y_tolerance (float x_tolerance /) -- Assume vector graphics to be close enough neighbors for belonging to the same rectangle. Default is 3 points.
final_filter (bool) -- If
True(default), the method will to remove rectangles having width or height smaller than the respective tolerance value. IfFalseno such filtering is done.
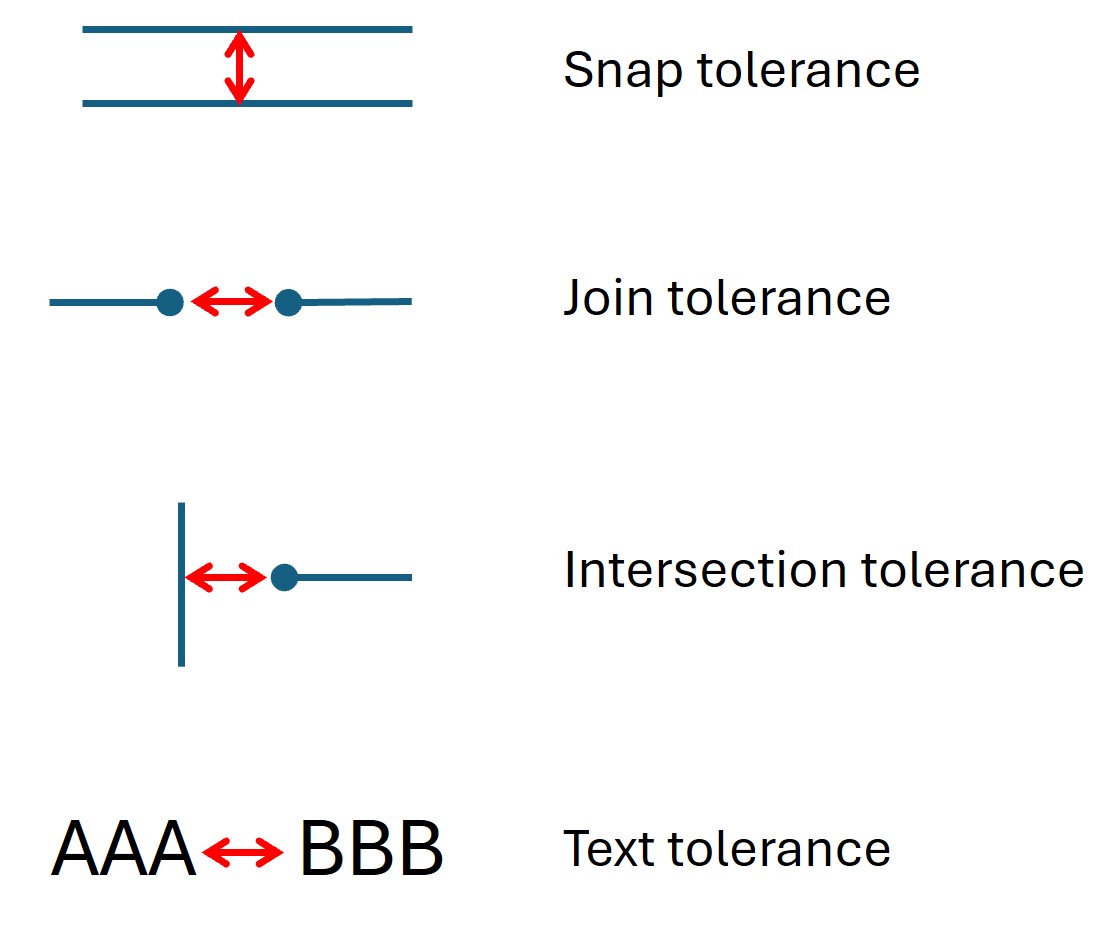
- find_tables(clip=None, strategy=None, vertical_strategy=None, horizontal_strategy=None, vertical_lines=None, horizontal_lines=None, snap_tolerance=None, snap_x_tolerance=None, snap_y_tolerance=None, join_tolerance=None, join_x_tolerance=None, join_y_tolerance=None, edge_min_length=3, min_words_vertical=3, min_words_horizontal=1, intersection_tolerance=None, intersection_x_tolerance=None, intersection_y_tolerance=None, text_tolerance=None, text_x_tolerance=None, text_y_tolerance=None, add_lines=None, add_boxes=None, paths=None, use_layout=True)¶
ページ上のテーブルを見つけ、関連情報を含むオブジェクトを返します。通常、多くのパラメータのデフォルト値は十分です。調整が必要なのは、極めてまれなケースのみです。
- パラメータ:
clip (rect_like) -- ページの長方形内で考慮する領域を指定します。デフォルトはページ全体です。
strategy (str) -- テーブル検出**戦略をリクエストします。有効な値は、**「lines」、「lines_strict」 、「text」 です
horizontal_lines (sequence[floats]) -- 行のy座標を含む浮動小数点数のリスト。指定した場合、追加のテーブル行を識別しないようにします。
vertical_lines (sequence[floats]) -- 列のx座標を含む浮動小数点数のリスト。指定した場合、追加のテーブル列を識別しないようにします。
min_words_vertical (int) -- 垂直戦略オプション「text」に関連します。少なくともこの数の単語が一致する必要があり、仮想の列境界を確立します。
min_words_horizontal (int) -- 水平戦略オプション「text」に関連します。少なくともこの数の単語が一致する必要があり、仮想の行境界を確立します。
snap_tolerance (float) -- 各縦線は、y値の差がこの値以下であれば、一つに結合されます。同様に、各横線も結合されます。デフォルトは3です。この値の代わりに、次元ごとに異なる値を指定することもできます。
snap_x_toleranceおよびsnap_y_toleranceを使用してください。join_tolerance (float) -- 2つのラインの終点と始点の間の差がこの値(ポイント単位)以下の場合、それらは1つのラインに 結合されます 。デフォルトは3です。この値の代わりに、
join_x_toleranceとjoin_y_toleranceを使用して寸法ごとに別々の値を指定できます。edge_min_length (float) -- この値(ポイント単位)を超えない場合、線を無視します。デフォルトは3です
intersection_tolerance (float) -- 直交するラインをセルの境界線に結合する際に、それらの直交するラインはこの値(ポイント単位)以内である必要があります。デフォルトは3です。この値の代わりに、次元ごとに個別の値を指定することもできます。
intersection_x_toleranceとintersection_y_toleranceを使用します。text_tolerance (float) -- 文字が単語に結合されるのは、その距離がこの値(ポイント)を超えない場合のみです。デフォルト値は3です。この値の代わりに、次元ごとに別々の値を指定することもできます。
text_x_toleranceとtext_y_toleranceを使用します。add_lines (tuple,list) -- Specify a list of "lines" (i.e. pairs of
point_likeobjects) as additional, "virtual" vector graphics. These lines may help with table and / or cell detection and will not otherwise influence the detection strategy. Especially, in contrast to parametershorizontal_linesandvertical_lines, they will not prevent detecting rows or columns in other ways. These lines will be treated exactly like "real" vector graphics in terms of joining, snapping, intersecting, minimum length and containment in thecliprectangle. Similarly, lines not parallel to any of the coordinate axes will be ignored.add_boxes (tuple,list) -- Specify a list of rectangles (
rect_likeobjects) as additional, "virtual" vector graphics. These rectangles may help with table and / or cell detection and will not otherwise influence the detection strategy. Especially, in contrast to parametershorizontal_linesandvertical_lines, they will not prevent detecting rows or columns in other ways. These rectangles will be treated exactly like "real" vector graphics in terms of joining, snapping, intersecting, minimum length and containment in thecliprectangle.paths (list) -- list of vector graphics in the format as returned be
Page.get_drawings(). Using this parameter will prevent the method to extract vector graphics itself. This is useful if the vector graphics are already available. This can save execution time significantly.use_layout (bool) -- use layout analysis to gate line-based table candidates. Set to
Falsefor pure line-based detection.
- 戻り値:
TableFinderオブジェクトには、次の重要な属性があります:cells: ページ上でテーブルのセルとして識別されたすべてのバウンディングボックスのリスト(すべてのテーブルを対象にします)。各セルは座標のタプル (x0, y0, x1, y1) または
Noneです。tables: Table オブジェクトのリスト。ページにテーブルが含まれていない場合、これは
[]になります。単一のテーブルはこのリストのアイテムとして見つけることができますが、TableFinderオブジェクト自体もそのテーブルのシーケンスです。つまり、tabsがTableFinderオブジェクトである場合、テーブル番号 "n" はtabs.tables[n]およびより短いtabs[n]によって提供されます。Tableオブジェクトには次の属性があります:bbox: the bounding box of the table as a tuple(x0, y0, x1, y1).cells: bounding boxes of the table's cells (list of tuples). A cell may also beNone.extract(): this method returns the text content of each table cell as a list of list of strings.to_markdown(): this method returns the table as a string in markdown format (compatible to Github). Markdown viewers can render the string as a table. This output is optimized for small token sizes, which is especially beneficial for LLM/RAG feeds. Pandas DataFrames (see methodto_pandas()below) offer an equivalent markdown table output which however is better readable for the human eye. Any line breaks (\n) in cells are replaced by HTML line breaks tags<br>.to_pandas(): this method returns the table as a pandas DataFrame. DataFrames are very versatile objects allowing a plethora of table manipulation methods and outputs to almost 20 well-known formats, among them Excel files, CSV, JSON, markdown-formatted tables and more.DataFrame.to_markdown()generates a Github-compatible markdown format optimized for human readability. This method however requires the package tabulate to be installed in addition to pandas itself.header: テーブルのヘッダー情報を含む
TableHeaderオブジェクト。col_count: an integer containing the number of table columns.row_count: an integer containing the number of table rows.rows: a list ofTableRowobjects containing two attributes,bboxis the boundary box of the row, andcellsis a list of table cells contained in this row.
TableHeaderオブジェクトには次の属性があります:bbox: ヘッダーのバウンディングボックス。
cells: 各列の名前を含むバウンディングボックスのリスト。
names: 各セルのバウンディングボックス内のテキストを含む文字列のリスト。これらは列の名前を表します。これらはテーブルを pandas DataFrame または CSV などにエクスポートする際に使用できます。
external: ヘッダーのバウンディングボックスがテーブル本体の外部にあるかどうかを示すブール値(
Trueの場合、外部)。テーブルのヘッダーは TableFinder のロジックによって識別されないため、external が True の場合、ヘッダーセルはTableFinderによって識別された任意のセルの一部ではありません。external == Falseの場合、最初のテーブル行がヘッダーです。
これらの Jupyter notebooks をご覧ください。これらのノートブックでは、1つのページに複数のテーブルがある場合や、複数のページにまたがるテーブル断片を結合するなど、標準的な状況がカバーされています。
注意
The lifetime of the
TableFinderobject, as well as that of all its tables equals the lifetime of the page. If the page object is deleted or reassigned, all tables are no longer valid.The only way to keep table content beyond the page's availability is to extract it via methods
Table.to_markdown(),Table.to_pandas()or a copy ofTable.extract()(e.g.Table.extract()[:]).注釈
Once a table has been extracted to a Pandas DataFrame with
to_pandas()it is easy to convert to other file types with the Pandas API:
Show/hide history
新機能バージョン1.23.0
1.23.19で変更された点:新しい引数
add_lines。
重要
必要に応じて、テーブル抽出を行う pdf2docx extract tables method も利
- add_stamp_annot(rect, stamp=0)¶
PDF only: Add a "rubber stamp" annotation to e.g. indicate the document's intended use ("DRAFT", "CONFIDENTIAL", etc.). The parameter may be either an integer to select text from a predefined array of standard texts or an image.
- パラメータ:
rect (rect_like) -- アノテーションを配置する矩形領域。
stamp (multiple) --
The following options are available:
The id number (int) of the stamp text. For available stamps see スタンプ注釈アイコン.
A string specifying an image file path.
A
bytes,bytearrayorio.BytesIOobject for an image in memory.A Pixmap.
Text-based stamps
Annot.rectis automatically calculated as the largest rectangle with an aspect ratio ofwidth:height = 3.8that fits in the providedrect. Its position is vertically and horizontally centered.選択されるフォントは「Times Bold」で、テキストは大文字になります。
The appearance can be modified using
Annot.set_opacity()and by setting the "stroke" color. By PDF specification, stamp annotations have no "fill" color.

Image-based stamps
The image is scaled to fit into the rectangle Rect (矩形) such that the image's center and the center of Rect (矩形) coincide. The aspect ratio of the image is preserved, so the image may not fill the entire rectangle. However, at least one of the given rectangle's width or height are fully covered.
The annotation can be modified via
Annot.set_opacity(). This method therefore is a way to display images transparently even if no alpha channel is present.Setting colors has no effect on image stamps.
Rotating image-based stamps is not supported. Setting the rotation may lead to unexpected results.
- add_widget(widget)¶
PDFのみ:ページにPDFフォームフィールド(ウィジェット)を追加します。これにより、PDFがフォームPDFに変換されます。ウィジェットにはさまざまなオプションがあるため、フォームフィールドの作成と更新の両方に使用する必要があるため、可能なPDFフィールド属性を含む新しいクラス Widget (ウィジェット) を開発しました。
- パラメータ:
widget (Widget (ウィジェット)) -- 事前に作成されている必要がある Widget (ウィジェット) オブジェクト。
- 戻り値:
ウィジェットアノテーション。
- delete_annot(annot)¶
v1.16.6 で変更: 削除操作には、現在は関連する 'Popup' や応答アノテーションおよび関連するオブジェクトも含まれます。
PDFのみ:ページから注釈を削除し、次の注釈を返します。
- パラメータ:
annot (Annot (注釈)) -- 削除するアノテーション。
- 戻り値の型:
- 戻り値:
削除された注釈の後に続く注釈。物理的な削除には、ガベージ> 0で新しいファイルに保存する必要があることを覚えておいてください。
- delete_widget(widget)¶
PDFのみ:ページからフィールドを削除し、次のフィールドを返します。
- パラメータ:
widget (Widget (ウィジェット)) -- 削除するウィジェット。
- 戻り値の型:
- 戻り値:
削除されたウィジェットの後に続くウィジェット。物理的な削除には、ガベージ> 0で新しいファイルに保存する必要があることを覚えておいてください。
Show/hide history
v1.18.4で変更
- delete_link(linkdict)¶
PDFのみ:ページから指定したリンクを削除します。パラメータは
get_links()の元のアイテムである必要があります(以下参照)。これは辞書の 「xref」 キーがPDFオブジェクトを識別するための理由です。- パラメータ:
linkdict (dict) -- 削除するリンクです。
- insert_link(linkdict)¶
PDFのみ:このページに新しいリンクを挿入します。パラメータは
get_links()で提供される形式の辞書である必要があります(以下参照)。- パラメータ:
linkdict (dict) -- 挿入するリンクです。
- update_link(linkdict)¶
PDFのみ:指定されたリンクを変更します。パラメータは
get_links()(以下参照)の 元のアイテム である必要があります(変更された場合)。これは辞書の 「xref」 キーがPDFオブジェクトを識別するための理由です。- パラメータ:
linkdict (dict) -- 変更するリンクです。
警告
URIリンク(
"kind": LINK_URI)を更新/挿入する場合は、"uri"キーの値を必ず「http://」、「https://」、「file://」、「ftp://」、「mailto:」などの区別可能な文字列で始めるようにしてください。そうしないと、ブラウザや他の「コンシューマ」ソフトウェアによって、予期しないデフォルトの仮定が不要な動作につながる可能性があります。
- get_label()¶
PDFのみ:ページのラベルを返します。
- 戻り値の型:
str
- 戻り値:
ローマ数字の「vii」などのラベル文字列、または定義されていない場合は ""。
Show/hide history
v1.18.6で新規追加
- get_links()¶
ページの すべて のリンクを取得します。
- 戻り値の型:
list
- 戻り値:
辞書のリスト。辞書エントリの説明については以下を参照してください。ページのリンクを変更する意図がある場合は、
Page.links()メソッドまたはこれを常に使用してください。
- links(kinds=None)¶
ページのリンクをイテレーターとして返します。結果は
Page.get_links()のエントリと同じです。- パラメータ:
kinds (sequence) -- 1つ以上のリンク種別をダウン選択するための整数のシーケンス。デフォルトはすべてのリンクです。例:kinds=(pymupdf.LINK_GOTO,) は内部リンクのみを返します。
- 戻り値の型:
generator
- 戻り値:
各イテレーションごとの
Page.get_links()のエントリ。
Show/hide history
v1.16.4で新規追加
- annots(types=None)¶
ページの注釈をイテレーターとして返します。
- パラメータ:
types (sequence) -- 1つ以上の注釈タイプをダウン選択するための整数のシーケンス。デフォルトはすべての注釈です。例:
types=(pymupdf.PDF_ANNOT_FREETEXT, pymupdf.PDF_ANNOT_TEXT)は「FreeText」および「Text」注釈のみを返します。- 戻り値の型:
generator
- 戻り値:
各イテレーションごとの Annot (注釈)。
注意
このジェネレータ内から アノテーションを安全に更新することはできません。これは、ほとんどの注釈の更新にはpage = doc.reload_page(page)を介してページを再読み込みする必要があるためです。この制限を回避するために、まず注釈のxref番号のリストを作成し、その後これらの番号を繰り返し処理します:
In [4]: xrefs = [annot.xref for annot in page.annots(types=[...])] In [5]: for xref in xrefs: ...: annot = page.load_annot(xref) ...: annot.update() ...: page = doc.reload_page(page) In [6]:
Show/hide history
v1.16.4で新規追加
- widgets(types=None)¶
フォームフィールドのジェネレーターを返します。
- パラメータ:
types (sequence) -- 1つ以上のウィジェットタイプに選択を絞り込むための整数のシーケンス。デフォルトではすべてのフォームフィールドが対象です。例:
types=(pymupdf.PDF_WIDGET_TYPE_TEXT,)を指定すると 'Text' フィールドのみが返されます。- 戻り値の型:
generator
- 戻り値:
各イテレーションでの Widget (ウィジェット)
Show/hide history
v1.16.4で新規追加
- write_text(rect=None, writers=None, overlay=True, color=None, opacity=None, keep_proportion=True, rotate=0, oc=0)¶
PDF のみ: 1つ以上の TextWriter (テキストライター) オブジェクトのテキストをページに書き込みます。
- パラメータ:
rect (rect_like) -- テキストを配置する場所。省略した場合、テキストライターの矩形の合併が使用されます。
writers (sequence) -- 1つ以上の TextWriter (テキストライター) オブジェクトのタプル/リスト、または単一の TextWriter (テキストライター) です。
opacity (float) -- 透明度を設定し、テキストライターの値を上書きします。
color (sequ) -- テキストの色を設定し、テキストライターの値を上書きします。
overlay (bool) -- テキストを前景または背景に配置するかどうか。
keep_proportion (bool) -- アスペクト比を保持するかどうか。
rotate (float) -- テキストを任意の角度で回転します。
注釈
overlay、keep_proportion、rotate、oc パラメーターは
Page.show_pdf_page()と同じ意味を持ちます。Show/hide history
v1.16.18 で追加された新機能です。
- insert_text(point, text, *, fontsize=11, fontname='helv', fontfile=None, idx=0, color=None, fill=None, render_mode=0, miter_limit=1, border_width=0.05, encoding=TEXT_ENCODING_LATIN, rotate=0, morph=None, stroke_opacity=1, fill_opacity=1, overlay=True, oc=0)¶
PDF only: Insert text lines starting at
point_likepoint. SeeShape.insert_text().Show/hide history
v1.18.4 で変更
- insert_textbox(rect, buffer, *, align=TEXT_ALIGN_LEFT, border_width=1, color=None, encoding=TEXT_ENCODING_LATIN, expandtabs=8, fill=None, fill_opacity=1, fontfile=None, fontname='helv', fontsize=11, lineheight=None, miter_limit=1, morph=None, oc=0, overlay=True, render_mode=0, rotate=0, set_simple=False, stroke_opacity=1)¶
PDF only: Insert text into the specified
rect_likerect.- パラメータ:
overlay -- see
Shape.commit().
For other args, see
Shape.insert_textbox.Show/hide history
v1.18.4 で変更
- insert_htmlbox(rect, text, *, css=None, scale_low=0, archive=None, rotate=0, oc=0, opacity=1, overlay=True)¶
PDFのみ: 指定された矩形にテキストを挿入します。このメソッドは、
Page.insert_textbox()メソッドとTextWriter.fill_textbox()メソッドと類似していますが、はるかに強力です。これは、Story (ストーリー) (ストーリー) オブジェクトに必要なすべての処理を行わせることで実現されます。Parameter
textmay be a string as in the other methods. But it will be interpreted as HTML source and may therefore also contain HTML language elements -- including styling. Thecssparameter may be used to pass in additional styling instructions.Automatic line breaks are generated at word boundaries. The "soft hyphen" character
"­"(or­) can be used to cause hyphenation and thus may also cause line breaks. Forced line breaks however are only achievable via the HTML tag<br>-\nis ignored and will be treated like a space.このメソッドでは、次のことが可能です。
太字、斜体、テキストの色、テキストの配置、フォントサイズ、またはフォントの切り替えなどのスタイル効果
テキストには、右から左に書かれる言語を含む 任意の言語を含めることができます。
Devanagari やその他のアジアの文字など、2つ以上のUnicodeが一つのグリフに変換される複雑なリガチャーのあるスクリプトは、正しい出力を生成するためにソフトウェアパッケージ HarfBuzz を使用しています。
画像はHTMLタグ
<img>を介して含めることができ、Storyが適切なレイアウトを担当します。これは、Page.insert_image()と比較した画像の挿入の代替オプションです。HTMLテーブル(
<table>タグ)をテキストに含めることができ、適切に処理されます。リンクが存在する場合、自動的にリンクが生成されます。
もしコンテンツが長方形に収まらない場合、開発者には2つの選択肢があります。:
それとも 、このことについての情報のみを受け取り(他のテキストボックスの挿入メソッドと同様に、何も起こらないことを受け入れる)、
または (
scale_low=0- デフォルト)コンテンツを収まるまで縮小します。
- パラメータ:
rect (rect_like) -- テキストを配置する長方形の領域。
text (str,Story) -- 書き込むテキスト。スタイル指示を含むプレーンテキストとHTMLタグの混合物であることができます。代替として、 :ref:`Story`(ストーリー)オブジェクトを指定することもできます(その場合、内部のストーリー生成ステップは省略されます)。必要なすべてのスタイリングとアーカイブ情報で生成されたストーリーを指定する必要があります。
css (str) -- optional string containing additional CSS instructions. This parameter is ignored if
textis a Story. See CSS Support for more.scale_low (float) -- コンテンツがターゲットの長方形に収まるまで必要に応じてコンテンツのスケーリングを行います。これはダウンスケーリングの制限を設定します。デフォルトは0で、制限なしを意味します。値が1の場合、ダウンスケーリングは許可されません。たとえば、0.2の値は、最大で80%のダウンスケーリングを意味します。
archive (Archive) -- an Archive object that points to locations where to find images or non-standard fonts. If
textrefers to images or non-standard fonts, this parameter is required. This parameter is ignored iftextis a Story.rotate (int) --
0、90、180、270のいずれかの値。これに応じて、テキストが埋められます:
0:左上から右下に。
90:左下から右上に。
180:右下から左上に。
270:右上から左下に。

oc (int) --
OCG(オプションコンテンツグループ)/OCMD(オプションコンテンツメタデータ)のxrefまたは0。詳細については、Page.show_pdf_page()を参照してください。opacity (float) -- コンテンツの塗りつぶしとストロークの不透明度を設定します。
0 <= opacity < 1の値のみ考慮されます。overlay (bool) -- テキストを他のコンテンツの前に配置します。詳細については、
Page.show_pdf_page()を参照してください。
- 戻り値:
浮動小数点数のタプル
(spare_height, scale)です。spare_height: The (positive) height of the remaining space in Rect (矩形) below the text, or -1 if we failed to fit.
scale: The scaling required;
0 < scale <= 1. Will bescale_lowif we failed to fit.
このレシピの例を参照してください:HTMLテキストでボックスを埋める方法。
Show/hide history
New in v1.26.5:
do additional scaling to fit long words.
If we succeeded and scaled down, the returned
spare_heightis now generally positive instead of being fixed to zero, because the final rect's height is usually not an exact multiple of the font line height.
New in v1.23.8: rebased-only.
New in v1.23.9:
opacityparameter.
描画メソッド
- draw_line(p1, p2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF のみ:p1 から p2 までの直線を描画します(
point_likes)。Shape.draw_line()を参照してください。Show/hide history
v1.18.4 で変更
- draw_zigzag(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF のみ:p1 から p2 までのジグザグ線を描画します(
point_likes)。Shape.draw_zigzag()を参照してください。Show/hide history
v1.18.4 で変更
- draw_squiggle(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF のみ:p1 から p2 までの波線(うねり)を描画します(
point_likes)。Shape.draw_squiggle()を参照してください。Show/hide history
v1.18.4 で変更
- draw_circle(center, radius, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF のみ:center を中心に、半径 radius の円を描画します
point_like。Shape.draw_circle()を参照してください。Show/hide history
v1.18.4 で変更
- draw_oval(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDF のみ:指定された
rect_likeまたはquad_like内に楕円を描画します。Shape.draw_oval()を参照してください。Show/hide history
v1.18.4 で変更
- draw_sector(center, point, angle, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, fullSector=True, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDFのみ: 円形セクターを描画し、オプションで円の中心とアークを接続します(パイの一部のように)。
Shape.draw_sector()を参照してください。Show/hide history
v1.18.4 で変更
- draw_polyline(points, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDFのみ: 一連の
point_likes ポイントによって定義された接続された複数のラインを描画します。Shape.draw_polyline()を参照してください。Show/hide history
v1.18.4 で変更
- draw_bezier(p1, p2, p3, p4, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDFのみ: 制御ポイント p2 および p3 を使用して、p1 から p4 へのキュービックベジエ曲線を描画します(すべてのポイントは
point_likeです)。Shape.draw_bezier()を参照してください。Show/hide history
v1.18.4 で変更
- draw_curve(p1, p2, p3, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDFのみ: これは draw_bezier() の特別なケースです。
Shape.draw_curve()を参照してください。Show/hide history
v1.18.4 で変更
- draw_rect(rect, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, radius=None, oc=0)¶
PDFのみ: 四角形を描画します。
Shape.draw_rect()を参照してください。Show/hide history
v1.18.4 で変更
v1.22.0で変更:パラメーター radius を追加しました。
- draw_quad(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)¶
PDFのみ: 四辺形を描画します。
Shape.draw_quad()を参照してください。Show/hide history
v1.18.4 で変更
- insert_font(fontname='helv', fontfile=None, fontbuffer=None, set_simple=False, encoding=TEXT_ENCODING_LATIN)¶
PDFのみ: テキスト出力メソッドで使用する新しいフォントを追加し、その
xrefを返します。ファイルにまだ存在しない場合、フォントの定義が追加されます。組み込みのBase14_Fontsおよび CJK フォントがサポートされており、「予約済み」 フォント名を介して使用できます。フォントはファイルパスまたはフォントファイルのイメージを含むメモリ領域として提供することもできます。- パラメータ:
fontname (str) --
このフォントをこのページ上でテキスト出力する際に参照される名前。 一般的に、ここで「自由な」選択ができます(ただし、Adobe PDFリファレンス、ページ16、セクション7.3.5を参照して正当なPDF名の形式的な説明を確認してください)。ただし、
Base14_FontsまたはCJKフォントのいずれかと一致する場合、fontfile および fontbuffer は 無視されます。言い換えれば、フォントを fontfile / fontbuffer 経由で挿入し、予約されたフォント名も指定することはできません。
注釈
予約されたフォント名は、大文字と小文字の組み合わせで指定でき、それでも適切な組み込みフォントの定義に一致します。フォント名「helv」、「Helv」、「HELV」、「Helvetica」などはすべて同じフォント定義「Helvetica」につながります。ただし、ページの観点からはこれらは 異なる参照 です。同じフォントの異なる エンコーディング バリアント(ラテン、ギリシャ、キリル文字など)をページ上で使用する場合、この事実を利用できます。
fontfile (str) -- フォントファイルへのパス。使用する場合、fontname は すべての予約済みの名前と異なる必要があります。
fontbuffer (bytes/bytearray) -- フォントファイルのメモリイメージ。使用する場合、fontname は すべての予約済みの名前と異なる 必要があります。通常、このパラメーターは
Font.bufferを介してサポート/利用可能な Font (フォント) に使用されます。set_simple (int) -- fontfile / fontbuffer ケースにのみ適用可能:「シンプル」フォントとしての扱いを強制します。つまり、文字コードが255までしか使用しないフォントです。
encoding (int) --
Base14_Fontsの「Helvetica」、「Courier」、「Times」セットにのみ適用可能。利用可能なエンコーディングのうち、ラテン(0)、キリル文字(2)、ギリシャ文字(1)のいずれかを選択します。「Symbol」と「ZapfDingBats」についてはデフォルト(0 = ラテン)のみを使用してください。
- Rytpe:
int
- 戻り値:
インストールされたフォントの
xref。
注釈
組み込みフォントはフォントファイルの追加を必要とせず、結果として生成されるPDFファイルは小さく保たれます。ただし、PDFビューアソフトウェアは適切な外観を生成する責任があり、それぞれがこれをどのように行うかには違い があります。これは特にCJKフォントに関して当てはまります。しかし、シンボルとZapfDingbatsも一部のケースで正しく扱われていないことがあります。以下は Font Names とそれに対応するインストールされた Base Font 名です:
ベース14フォント [1]
フォント名
インストールされたベースフォント
コメント
helv
Helvetica
通常
heit
Helvetica-Oblique
斜体
hebo
Helvetica-Bold
太字
hebi
Helvetica-BoldOblique
太字斜体
cour
Courier
通常
coit
Courier-Oblique
斜体
cobo
Courier-Bold
太字
cobi
Courier-BoldOblique
太字斜体
tiro
Times-Roman
通常
tiit
Times-Italic
斜体
tibo
Times-Bold
太字
tibi
Times-BoldItalic
太字斜体
symb
Symbol
zadb
ZapfDingbats
CJKフォント [2] (中国、日本、韓国)
フォント名
インストールされたベースフォント
コメント
china-s
Heiti
簡体字中国語
china-ss
Song
簡体字中国語(セリフ)
china-t
Fangti
繁体字中国語
china-ts
Ming
繁体字中国語(セリフ)
japan
Gothic
Japanese
japan-s
Mincho
Japanese (serif)
korea
Dotum
Korean
korea-s
Batang
Korean (serif)
- insert_image(rect, *, alpha=-1, filename=None, height=0, keep_proportion=True, mask=None, oc=0, overlay=True, pixmap=None, rotate=0, stream=None, width=0, xref=0)¶
PDFのみ:指定された矩形内に画像を配置します。画像はすでにPDF内に存在するか、ピクスマップ、ファイル、またはメモリ領域から取得できます。
- パラメータ:
rect (rect_like) -- 画像を配置する場所。有限で空でない必要があります。
alpha (int) -- 非推奨であり、無視されます。
filename (str) -- 画像ファイルの名前(MuPDFでサポートされているすべての形式 – サポートされている入力画像フォーマット を参照)。
height (int)
keep_proportion (bool) -- アスペクト比を保持するかどうか。
mask (bytes,bytearray,io.BytesIO) -- メモリ内の画像 -- ベース画像のマスク(アルファ値)として使用されます。指定する場合、ベース画像はファイル名またはストリームとして提供する必要があります。また、既にマスクを持つ画像ではない必要があります。
oc (int) -- (
xref) この画像の表示をこのOCGまたはOCMDに依存させます。複数回の挿入の最初の後には無視されます。このプロパティは生成された PDF 画像オブジェクトに格納されるため、PDF 全体で画像の表示を制御します。overlay -- 共通パラメータ を参照してください。
pixmap (Pixmap) -- 画像を含むピクスマップ。
rotate (int) -- (v1.14.11で新機能)* 画像を回転させます。90度の整数倍である必要があります。正の値は反時計回りに回転します。任意の角度での回転が必要な場合は、まず画像をPDFに変換(
Document.convert_to_pdf())し、Page.show_pdf_page()を使用することを検討してください。stream (bytes,bytearray,io.BytesIO) -- メモリ内の画像(MuPDFでサポートされているすべての形式 – サポートされている入力画像フォーマット を参照)。
width (int)
xref (int) -- PDF内にすでに存在する画像の
xref。指定された場合、filename、 Pixmap 、stream、alpha、およびmaskパラメータは無視されます。ページは単純に既存の画像への参照を受け取ります。
- 戻り値:
埋め込まれた画像の
xrefです。この値は、画像を再度挿入する場合のxref引数として使用でき、非常に大幅なパフォーマンス向上に役立ちます。
この例では、ドキュメントのすべてのページに同じ画像を配置します:
>>> doc = pymupdf.open(...) >>> rect = pymupdf.Rect(0, 0, 50, 50) # put thumbnail in upper left corner >>> img = open("some.jpg", "rb").read() # an image file >>> img_xref = 0 # first execution embeds the image >>> for page in doc: img_xref = page.insert_image(rect, stream=img, xref=img_xref, 2nd time reuses existing image ) >>> doc.save(...)
注釈
このメソッドは、同じ画像が複数回挿入される場合(上記の例のように)を検出し、データは最初の実行時にのみ保存されます。これは、デフォルトの
xref=0を使用している場合でも(性能は劣るが)同様ですこのメソッドは、ファイルを開く前に同じ画像がすでにファイルの一部であるかどうかを検出できません。
このメソッドを使用して、ページの背景または前景画像(著作権表示や透かしのようなもの)を提供できます。ただし、前景に透明な画像が必要な場合は、そのことを覚えておいてください...
画像は非圧縮で挿入されることがあります。たとえば、
Pixmapを使用するか、画像にアルファチャンネルがある場合です。したがって、ファイルを保存する際には deflate=True を使用することを検討してください。また、透明性が関与する場合でも、画像サイズを効果的に制御する方法が存在します。ドキュメンテーションの PDFページに画像を追加する方法 セクションをご覧ください。画像はPDF内でその元の品質で保存されます。これは、ディスプレイに必要なものよりもはるかに優れている場合があります。挿入前に 画像サイズを減少させる ことを検討してください。たとえば、Pixmapオプションを使用してから縮小または縮小することができます(Pixmap の章を参照)。PILメソッドの Image.thumbnail() もそのために使用できます。ファイルサイズの節約は非常に大きい場合があります。
同じ画像を複数のページで効率的に表示する別の方法は、別のメソッドです:
show_pdf_page()。そのメソッドで使用可能な中間のPDFを取得する方法については、Document.convert_to_pdf()
Show/hide history
v1.14.1で変更:デフォルトでは、画像はアスペクト比を保持します
Changed in v1.14.11: Added args
keep_proportion,rotate.v1.14.17で変更されました
The image is now always placed centered in the rectangle, i.e. the centers of image and rectangle are equal.
Added support for
streamasio.BytesIO.
v1.17.6で変更:挿入矩形はもはやページの
Page.cropbox[5] と非空の交差を持つ必要はありません。Changed in v1.18.1: Added
maskarg.Changed in v1.18.3: Added
ocarg.Changed in v1.18.13:
Changed in v1.19.3: deprecate and ignore
alphaarg.
- replace_image(xref, filename=None, pixmap=None, stream=None)¶
xrefで指定された画像を別の画像で置き換えます。
- パラメータ:
filename、Pixmap、streamの引数は、特にPage.insert_image()での意味と同じです。特に、これらのうちの1つだけを指定する必要があります。これは グローバルな置換 です:新しい画像は、古い画像がファイル全体で表示されていた場所でも表示されます。
このメソッドは主に技術的な目的で存在しています。典型的な使用例には、大きな画像を解像度の低いバージョン、カラーではなくグレースケールなど、より小さなバージョンで置き換えることが含まれます。または透明度を変更することもあります。
Show/hide history
v1.21.0で新たに追加
- delete_image(xref)¶
画像のxrefを削除します。これはわずかに誤解を招くかもしれませんが、実際には、画像は上記の
Page.replace_image()を使用して小さな透明な Pixmap で置き換えられます。しかし、視覚的な効果は同等です。- パラメータ:
xref (int) -- 画像の
xref。
これは グローバルな置換です: 新しい画像は、古い画像がファイル全体で表示されていた場所でも表示されなくなります。
Page.get_images()、Page.get_image_info()、またはPage.get_text()などのメソッドを使用してページの画像を調査/抽出する場合、置き換えられた「ダミー」画像は次のように検出されます`(45, 47, 1, 1, 8, 'DeviceGray', '', 'Im1', 'FlateDecode')` 、また同じ境界ボックスをページ上に「覆う」ように見えます。Show/hide history
v1.21.0で新たに追加
- get_text(option, *, clip=None, flags=None, textpage=None, sort=False, delimiters=None)¶
Retrieves the content of a page in a variety of formats. Depending on the
flagsvalue, this may include text, images and several other object types. The method is a wrapper for multiple TextPage (テキストページ) methods by choosing the output optionoptas follows:"text" --
TextPage.extractTEXT(), default. Always includes text only."blocks" --
TextPage.extractBLOCKS(). Includes text and may include image meta information."words" --
TextPage.extractWORDS(). Always includes text only."html" --
TextPage.extractHTML(). May include text and images."xhtml" --
TextPage.extractXHTML(). May include text and images."xml" --
TextPage.extractXML(). Always includes text only."dict" --
TextPage.extractDICT(). May include text and images."json" --
TextPage.extractJSON(). May include text and images."rawdict" --
TextPage.extractRAWDICT(). May include text and images."rawjson" --
TextPage.extractRAWJSON(). May include text and images.
- パラメータ:
opt (str) -- A string indicating the requested format, one of the above. A mixture of upper and lower case is supported. If misspelled, option "text" is silently assumed.
clip (rect-like) -- restrict the extraction to this rectangle. If
None(default), the visible part of the page is taken. Any content (text, images) that is not fully contained inclipwill be completely omitted. To avoid clipping altogether useclip=pymupdf.INFINITE_RECT(). Only then the extraction will contain all items. This parameter has no effect on options "html", "xhtml" and "xml".flags (int) -- 画像を含めるか、テキストをどのように空白や
ligaturesに対応させるかを制御するための指示ビット。 使用可能な指示ビットについては、 Font Properties を参照してください。 また、デフォルト設定については、 テキスト抽出フラグのデフォルト値 を参照してください。 (v1.16.2で新規追加)textpage -- use a previously created TextPage (テキストページ). This reduces execution time very significantly: by more than 50% and up to 95%, depending on the extraction option. If specified, the 'flags' and 'clip' arguments are ignored, because they are textpage-only properties. If omitted, a new, temporary textpage will be created.
sort (bool) -- sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order. Has no effect on (X)HTML and XML. For options "blocks", "dict", "json", "rawdict", "rawjson", sorting happens by coordinates
(y1, x0)of the respective block bbox. For options "words" and "text", the text lines are completely re-synthesized to follow the reading sequence and appearance in the document -- which even establishes the original layout to some extent.delimiters (str) -- これらの文字を、追加の単語の区切りとして、"words" 出力オプションで使用します(それ以外の場合は無視されます)。デフォルトでは、すべての空白(非改行スペース
0xA0を含む)が単語の開始と終了を示します。これにより、さらにこれを引き起こす文字を指定できます。例えば、デフォルトでは "john.doe@outlook.com" は1つの単語として返されます。delimiters="@."と指定すると、"john"、"doe"、"outlook"、"com" の4つの単語が返されます。その他の可能な用途には、句読点を無視するためのdelimiters = string.punctuationがあります。"word" 文字列には、区切り文字は含まれません。 (v1.23.5で新たに追加)
- 戻り値の型:
str, list, dict
- 戻り値:
ページの内容を表す文字列、リスト、または辞書。詳細については対応するTextPageメソッドを参照してください。
注釈
このメソッドを、any supported document type からTEXT、HTML、XHTML、またはXMLドキュメントのいずれかに変換する ドキュメント変換ツール として使用できます。
The inclusion of text via the clip parameter is decided on a by-character level: a character becomes part of the output, if its bbox is contained in
clip. This deviates from the algorithm used in redaction annotations: a character will be removed if its bbox intersects any redaction annotation.
Show/hide history
v1.19.0で変更:TextPage (テキストページ) パラメータを追加
v1.19.1で変更:
sortパラメータを追加v1.19.6で変更:各メソッドごとのデフォルトフラグを定義するための新しい定数を追加
Changed in v1.23.5: added
delimitersparameterChanged in v1.24.11: changed the effect of
sort_Truefor "text" and "words" to closely follow natural reading sequence.
- get_textbox(rect, textpage=None)¶
指定された矩形に含まれるテキストを取得します。
- パラメータ:
rect (rect-like) -- 矩形のようなもの。
textpage -- 使用する TextPage (テキストページ)。省略した場合、新しい一時的なテキストページが作成されます。
- 戻り値:
必要に応じて改行が挿入された文字列。v1.19.0 で変更: それは専用のコードに基づいています。典型的な使用例は、
Page.search_for()の結果をチェックすることです>>> rl = page.search_for("currency:") >>> page.get_textbox(rl[0]) 'Currency:' >>>
Show/hide history
新機能 v1.17.7
v1.19.0 で変更: TextPage (テキストページ) パラメータを追加
- get_textpage(clip=None, flags=3)¶
ページ用の TextPage (テキストページ) を作成します
- パラメータ:
flags (int) -- 後続のテキスト抽出と検索で使用可能なコンテンツを制御する指示ビット –
Page.get_text()のパラメータを参照してください。clip (rect-like) -- (v1.17.7 で新機能) 抽出されたテキストをこの領域に制限します。
- 戻り値:
Show/hide history
v1.16.5 で新機能。
v1.17.7 で変更:
clipパラメータが導入されました。
- get_textpage_ocr(flags=3, language='eng', dpi=72, full=False, tessdata=None)¶
Optical Character Recognition (OCR) technology can be used to extract text data for pages where text is in raster image or vector graphic format. Use this method to OCR a page for subsequent text extraction.
This method returns a TextPage (テキストページ) for the page that includes OCRed text. MuPDF will invoke Tesseract-OCR if this method is used.
- パラメータ:
flags (int) -- 後続のテキスト抽出と検索に使用可能なコンテンツを制御する指示ビット –
Page.get_text()のパラメータを参照してください。language (str) -- 期待される言語。複数の言語が期待される場合は "+" で区切って指定します。たとえば英語とスペイン語の場合は "eng+spa" です。
dpi (int) -- インチ当たりのドット数で指定された解像度。認識品質(および実行時間)に影響を与えます。
full (bool) -- whether to OCR the full page, or only page areas that contain no legible text.
tessdata (str) -- The name of Tesseract's language support folder
tessdata. If omitted, the name is determined using functionget_tessdata().
注釈
This method does not support a clip parameter -- OCR (full or partial) will always happen for the complete page rectangle.
- 戻り値:
TextPage (テキストページ)。実行時間は
Page.get_textpage()よりも大幅に長くなる場合があります。
For
full=TrueOCR, all text will have the font "GlyphLessFont" from Tesseract. In case of partial OCR (full=False), legible normal text will keep its properties, and only recognized text will have the GlyphLessFont.Recognized / OCR text will follow (legible) normal text for partial OCR and will thus not be in reading order. Establishing reading order is -- as always -- your responsibility.
注釈
Text extraction results, including any OCR, are stored in the returned TextPage (テキストページ). To access them, you must use the
textpageparameter in all subsequent text extraction and search methods.This Jupyter notebook walks through an example for using OCR textpages.
Show/hide history
v1.19.0 で新機能
v1.19.1 で変更: ページのフルと部分的な OCR をサポート
changed in v1.27.2: For partial OCR, all page areas outside legible text are now OCRed, not just those within images. This means that OCR will now also be performed for vector graphics, and for text containing illegible characters.
- get_drawings(extended=False)¶
ページのベクトルグラフィックスを返します。これらは線、四角形、四角形または曲線を描画するための命令で、色、透明度、線の幅、点線などのプロパティを含みます。代替用語は「ラインアート」と「ドローイング」です。
- 戻り値:
辞書のリスト。各辞書アイテムには、同じプロパティ(色、破線など)を持つ1つ以上の単一の描画コマンドが含まれます。これらはPDFでは "path" と呼ばれ、ここではその名前を採用していますが、このメソッドは すべてのドキュメントタイプに対して機能します。
fill、stroke、fill-strokeパスのパス辞書は、Shape(シェイプ) クラスと互換性があるように設計されています。次のキーがあります:
キー
値
closePath
Shape(シェイプ) のパラメーターと同じです。
color
ストロークカラー(Shape(シェイプ) を参照)。
dashes
破線の仕様(Shape(シェイプ) を参照)。
even_odd
領域のオーバーラップの塗りつぶし色(Shape(シェイプ) を参照)。
fill
塗りつぶしカラー(Shape(シェイプ) を参照)。
items
描画コマンド(直線、四角形、四角形、曲線など)のリスト。
lineCap
3つの数値からなるタプル。出力時に Shape(シェイプ) との最大値を使用します。
lineJoin
Shape(シェイプ) のパラメーターと同じです。
fill_opacity
v1.18.17で新しく追加された塗りつぶしカラーの透明度(Shape(シェイプ) を参照)。
stroke_opacity
v1.18.17で新しく追加されたストロークカラーの透明度(Shape(シェイプ) を参照)。
rect
このパスでカバーされるページ領域。情報のみ。
layer
v1.22.0で新しく追加された適用可能なオプションコンテンツグループの名前
level
v1.22.0で新しく追加された
extended=Trueの場合の階層レベルseqno
v1.19.0で新しく追加されたページ表示を構築する際のコマンド番号
type
このパスのタイプ。 (v1.18.17で新規追加)
width
ストロークラインの幅(Shape(シェイプ) を参照)。
(バージョン1.18.17で変更) キー
"opacity"は新しいキー"fill_opacity"および "stroke_opacity"` に置き換えられました。これは、Shape.finish()の対応するパラメーターと互換性があるようになりました。グループやクリップ以外のパスに対して、キー
"type"は次のいずれかの値を取ります:"f" - これは fill-only のパスです。この操作に関連するキーの値のみが意味を持ち、適用されないものは値が
Noneで存在します。:"color"、"lineCap"、"lineJoin"、"width"、"closePath"、"dashes"` は無視すべきです。"s" - これは stroke-only のパスです。以前と同様に、キー
"fill"は値がNoneで存在します。"fs" - これは fill と stroke の組み合わせ操作を実行するパスです
path["items"]の各アイテムは、次のいずれかです:("l", p1, p2)- p1 から p2 への直線(Point (ポイント) オブジェクト)。("c", p1, p2, p3, p4)- p1 から p4 へ の三次ベジエ曲線(p2 と p3 は制御点です)。すべてのオブジェクトは Point (ポイント) タイプです。("re", rect, orientation)- a Rect (矩形) 同じパス内の複数の矩形が検出されます (v1.18.17で変更)。整数のorientationは、含まれる領域が左に回転しているかどうかを示します (1 = 反時計回り)。または右に回転しているかどうかを示します [7] (v1.19.2で変更)("qu", quad)- Quad (クアッド)。バージョン1.18.17で新しく追加され、バージョン1.19.2で変更されました: 3つまたは4つの連続する線が Quad を実際に表すことが検出されます。
Using class Shape(シェイプ), you should be able to recreate the original drawings on a separate (PDF) page with high fidelity under normal, not too sophisticated circumstances. Please see the following comments on restrictions. A coding draft can be found in How to Extract Drawings.
extended=Trueを指定すると、出力が大幅に変更されます。最も重要なのは、新しい辞書タイプが存在することです: "clip" および "group"。すべてのパスは、新しい整数キー "level"、つまり階層レベルでエンコードされた階層構造に組織されます。各グループまたはクリップは、新しい階層を確立し、それ以降のすべてのパスに適用されます。 (v1.22.0で新規)
前任者よりも小さいレベル値を持つパスは、少なくとも前の階層レベルのスコープを終了します。前のクリップと同じレベルの "clip" パスは、そのクリップのスコープを終了します。同様に、グループも同じです。これは、次の例で最もよく説明されます:
+------+------+--------+------+--------+ | line | lvl0 | lvl1 | lvl2 | lvl3 | +------+------+--------+------+--------+ | 0 | clip | | | | | 1 | | fill | | | | 2 | | group | | | | 3 | | | clip | | | 4 | | | | stroke | | 5 | | | fill | | ends scope of clip in line 3 | 6 | | stroke | | | ends scope of group in line 2 | 7 | | clip | | | | 8 | fill | | | | ends scope of line 0 +------+------+--------+------+--------+
行0の「clip」は行7を含む行全体に適用されます。行2の「group」は行3から5までの行に適用され、行3の「clip」は行4にのみ適用されます。
行4の「stroke」は行2の「group」と行3の「clip」(それ自体が行0の「clip」のサブセットです)の制御下にあります。
「clip」 辞書。その値(特に「scissor」)は、後続の辞書が「level」の値が大きい限り、有効で適用されます。
キー
値
closePath
「stroke」または「fill」の辞書と同じ
even_odd
「stroke」または「fill」の辞書と同じ
items
「stroke」または「fill」の辞書と同じ
rect
「stroke」または「fill」の辞書と同じ
layer
「stroke」または「fill」の辞書と同じ
level
「stroke」または「fill」の辞書と同じ
scissor
クリップ矩形
type
"clip"
「group」辞書。その値は、後続の辞書が「level」の値が大きい限り、有効で適用されます。同じレベルまたはそれ以下の辞書がこのグループを終了します。
キー
値
rect
「stroke」または「fill」の辞書と同じ
layer
「stroke」または「fill」の辞書と同じ
level
「stroke」または「fill」の辞書と同じ
isolated
(ブール)このグループが孤立しているかどうか
knockout
(ブール)これが「Knockout Group」であるかどうか
blendmode
BlendModeの名前、デフォルトは「Normal」
opacity
範囲[0、1]内の浮動小数点値
type
"group"
注釈
このメソッドは、
Page.get_cdrawings()の出力に基づいています。これははるかに高速ですが、出力の処理には多少の注意が必要です。Show/hide history
v1.18.0で新規追加
v1.18.17で変更
v1.19.0で変更: “seqno”キーを追加、“clippings”キーを削除
v1.19.1で変更: “color” / “fill”キーは常にRGBタプルまたはNoneのいずれかであるように変更。これにより、異常なカラースペースに起因する問題が解消されます。
v1.19.2で変更: "re" アイテムでカバーされる領域の "orientation" を示すインジケーターを追加
v1.22.0で変更: 新しいキー
"layer"を追加。これにはパスのオプションコンテンツグループの名前が含まれます(またはNone)。v1.22.0で変更: クリッピングとグループパスも返すようにするためのパラメーター
extendedを追加
- get_cdrawings(extended=False)¶
ページ上のベクトルグラフィックスを抽出します。技術的な違いを除いて、
Page.get_drawings()と機能的に同等ですが、はるかに高速です:各パスタイプには関連するキーのみ含まれます。たとえば、ストロークパスには
"fill"カラーキーはありません。Page.get_drawings()メソッドのコメントを参照してください。座は
point_like、rect_like、quad_likeの tuples として与えられます。Point (ポイント)、Rect (矩形)、Quad (クアッド) オブジェクトとしてではなく。
性能が懸念される場合、このメソッドを使用することを検討してください。バージョン1.18.17より前と比較して、応答時間が大幅に短縮されるはずです。以前は2秒かかったページが、このメソッドを使用すると200ミリ秒で完了する場合もあります。
Show/hide history
新機能(v1.18.17)
v1.19.0で変更:「clippings」キーを削除、新たに「seqno」キーを追加。
v1.19.1で変更:常にRGBカラータプルを生成します。
v1.22.0で変更:新たに「layer」というキーが追加され、パスのオプションコンテンツグループの名前(またはNone)が含まれます。
Changed in v1.22.0: added parameter
extendedto also return clipping paths.
- get_fonts(full=False)¶
PDFのみ:ページで参照されているフォントのリストを返します。
Document.get_page_fonts()のラッパーです。
- get_images(full=False)¶
PDFのみ:ページで参照されているイメージのリストを返します。
Document.get_page_images()のラッパーです。
- get_image_info(hashes=False, xrefs=False)¶
Return a list of meta information dictionaries for all images displayed by the page. This works for all document types.
- パラメータ:
hashes (bool) -- 新機能(v1.18.13):各イメージのMD5ハッシュコードを計算し、イメージの重複を識別できるようにします。これにより、出力に
"digest"キーが追加され、その値は16バイトのバイトオブジェクトです。xrefs (bool) -- PDF only. Try to find the
xreffor each image. Implieshashes=True. Adds the"xref"key to the dictionary. If not found, the value is 0, which means, the image is either "inline" or its xref is undetectable for some reason. Please note that this option has an extended response time, because the MD5 hashcode will be computed at least two times for each image with an xref. (New in v1.18.13)
- 戻り値の型:
list[dict]
- 戻り値:
A list of dictionaries. This includes information for exactly those images, that are shown on the page -- including "inline images". The dictionary layout is similar to that of image blocks in
page.get_text("dict").In contrast to images included in
Page.get_text(), image binary content is not loaded by this method, which drastically reduces memory usage. Another difference is that image detection is not restricted to the visible part of the page or anyclipparameter: methodPage.get_text()will only extract images fully contained in the providedclip.キー
値
number
block number (
int)bbox
ページ上の画像の境界ボックス、
rect_likewidth
original image width (
int)height
original image height (
int)cs-name
colorspace name (
str)colorspace
colorspace.n (
int)xres
resolution in x-direction (
int) [10]yres
resolution in y-direction (
int) [10]bpc
bits per component (
int)size
storage occupied by image (
int)digest
MD5 hashcode (
bytes), ifhashesis truexref
画像の
xrefまたは0、xrefs がtrueの場合transform
画像の境界ボックスをbboxに変換するための行列、
matrix_likehas-mask
whether the image is transparent and has a mask (
bool)同じ画像の複数の出現は常に報告されます。digestの値を比較して重複を検出できます。
Show/hide history
新機能(v1.18.11)
v1.18.13で変更: イメージのMD5ハッシュコードの計算と
xrefの検索が追加されました。
- get_xobjects()¶
PDFのみ:ページで参照されているフォームXObjectのリストを返します。
Document.get_page_xobjects()のラッパーです。
- get_image_rects(item, transform=False)¶
PDFのみ:埋め込み画像の境界ボックスと変換行列を返します。これは
Page.get_image_bbox()の改良バージョンで、次の違いがあります:画像が どのように 呼び出されるかに制限はありません(ページまたはそのフォームXObjectのいずれかによって)。結果は常に完全かつ正確です。
結果は Rect (矩形) または(Rect (矩形)、Matrix (マトリックス))オブジェクトのリストです(transform に応じて異なります)。各リスト項目は、ページ上の画像の1つの場所を表します。
Page.get_image_bbox()では複数の出現を検出できない場合があります。このメソッドは、
xrefs=TrueでPage.get_image_info()を呼び出すため、Page.get_image_bbox()よりも明らかに長い応答時間がかかります。
- パラメータ:
item (list,str,int) --
Page.get_images()のリストアイテム、そのようなアイテムの参照 name エントリ(item[7])、または画像のxref。transform (bool) -- 画像の矩形をbboxに変換するために使用される行列も返すかどうか。trueの場合、タプル
(bbox, matrix)が返されます。
- 戻り値の型:
list
- 戻り値:
ページ上の各画像出現に対する境界ボックスとそれに対応する変換行列。アイテムがページ上にない場合、空のリスト
[]が返されます。
Show/hide history
New in v1.18.13
- get_image_bbox(item, transform=False)¶
PDFのみ:埋め込まれたイメージの境界ボックスと変換行列を返します。
- パラメータ:
item (list,str) --
Page.get_images()のリストのアイテムで full=True が指定されているもの、またはそのようなアイテムの参照名 name エントリ、つまりitem[-3](またはitem[7])。transform (bool) -- (v1.18.11で新規) イメージの矩形をページのbboxに変換するために使用される行列も返すかどうか。デフォルトはbboxのみです。 trueの場合、タプル
(bbox, matrix)が返されます。
- 戻り値の型:
- 戻り値:
イメージの境界ボックス - オプションでその変換行列も。
Show/hide history
(Changed in v1.16.7): If the page in fact does not display this image, an infinite rectangle is returned now. In previous versions, an exception was raised. Formally invalid parameters still raise exceptions.
(Changed in v1.17.0): Only images referenced directly by the page are considered. This means that images occurring in embedded PDF pages are ignored and an exception is raised.
(Changed in v1.18.5): Removed the restriction introduced in v1.17.0: any item of the page's image list may be specified.
(Changed in v1.18.11): Partially re-instated a restriction: only those images are considered, that are either directly referenced by the page or by a Form XObject directly referenced by the page.
(Changed in v1.18.11): Optionally also return the transformation matrix together with the bbox as the tuple
(bbox, transform).
注釈
Page.get_images()には「不要な」エントリが含まれている場合があることに注意してください。これはPDF作成者によって意図的に設定されたものであり、エラーではありません。この場合、例外は発生しませんが、無限の矩形が返されます。このような状況を回避するには、このメソッドの前にPage.clean_contents()を実行することができます。イメージの「変換行列」は、
bbox / transform == pymupdf.Rect(0, 0, 1, 1)という式が真であるための行列であり、詳細はこちらを参照してください:画像変換行列。
Show/hide history
変更点 v1.18.11:イメージの変換行列を返すようになりました
- get_svg_image(matrix=pymupdf.Identity, text_as_path=True)¶
ページからSVGイメージを作成します。現在、フルページのイメージのみがサポートされています。
- パラメータ:
matrix (matrix_like) -- 行列、デフォルトは Identity (アイデンティティ) です。
text_as_path (bool) -- テキストの表現方法を制御します。
Trueは、各文字を一連の基本的な描画コマンドとして出力し、これによりブラウザでのテキスト表示がより正確になりますが、テキスト指向のページの場合、非常に大きな出力になります。Falseの場合、表示品質は現在のシステムに参照されるフォントの存在に依存します。欠落しているフォントの場合、インターネットブラウザはいくつかのデフォルトにフォールバックします -- これにより見栄えが悪くなります。SVGのテキストを解析したい場合はFalseを選択してください。(v1.17.5で新規追加)
- 戻り値:
UTF-8エンコードされた文字列で、イメージを含みます。 SVGにはXML構文があるため、テキストファイルに保存でき、標準の拡張子は
.svgです。注釈
PDFの場合、メソッドを使用する前に、ページのCropBoxを変更して「フルページイメージのみ」制限を回避できます。
- get_pixmap(*, matrix=pymupdf.Identity, dpi=None, colorspace=pymupdf.csRGB, clip=None, alpha=False, annots=True)¶
ページからピクスマップを作成します。おそらく、Pixmap を作成するために最も頻繁に使用されるメソッドでしょう。
すべてのパラメータは keyword-only. です。
- パラメータ:
matrix (matrix_like) -- デフォルトは Identity (アイデンティティ) です。
dpi (int) -- desired resolution in x and y direction. If not
None, the"matrix"parameter is ignored. (New in v1.19.2)colorspace (str or Colorspace (カラースペース)) -- 所望のカラースペース、"GRAY"、"RGB"、または"CMYK"のいずれか(大文字/小文字を区別しない)。または、Colorspace (カラースペース) のように、事前定義されたもののいずれかを指定できます:
csGRAY、csRGB、csCMYK。clip (irect_like) -- ページの矩形とこの領域の交差に描画を制限します。
alpha (bool) --
透明チャネルを追加するかどうか。本当に透明性が必要でない場合は、常にデフォルトの
Falseを受け入れてください。これにより、メモリ(RGBの場合25%…ピクスマップは通常大きいです!)と処理時間が大幅に節約されます。また、画像がレンダリングされる方法についても重要な違いに注意してください:Trueの場合、ピクスマップのサンプル領域は0x00で事前クリアされます。これにより、ページが空白の場所には透明な領域が表示されます。Falseの場合、ピクスマップのサンプルは 0xff で事前クリアされます。これにより、ページに表示する内容がない場所には white が表示されます。Show/hide history
- v1.14.17で変更されました
デフォルトのalpha値は
Falseになりました。alpha=True で生成されたもの

alpha=False で生成されたもの

annots (bool) -- (v1.16.0で新たに追加) アノテーションをレンダリングするか抑制するか。注釈用に個別にピクスマップを作成できます。
- 戻り値の型:
- 戻り値:
ページのピクスマップ。生成されたイメージを細かく制御するために、最も重要なパラメータは matrix です。たとえば、Matrix(xzoom, yzoom)を使用してイメージの解像度を増減させることができます。zoom > 1の場合、より高い解像度が得られ、zoom=2はその方向のピクセル数を2倍にし、したがって2倍の大きさのイメージを生成します。非正の値は水平または垂直に反転させます。同様に、行列は回転やシアーも可能にし、行列の乗算を介して効果を組み合わせることもできます。詳細については、Matrix (マトリックス) セクションをご覧ください。
注釈
The pixmap will have "premultiplied" pixels if
alpha=True. To learn about some background, e.g. look for "Premultiplied alpha" here.このメソッドはページの回転を尊重し、
clipとPage.cropboxの交差を超えません。ページのmediaboxが必要な場合(およびこれが異なる矩形の場合)、次のようなスニペットを使用してこれを実現できます:In [1]: import pymupdf In [2]: doc=pymupdf.open("demo1.pdf") In [3]: page=doc[0] In [4]: rotation = page.rotation In [5]: cropbox = page.cropbox In [6]: page.set_cropbox(page.mediabox) In [7]: page.set_rotation(0) In [8]: pix = page.get_pixmap() In [9]: page.set_cropbox(cropbox) In [10]: if rotation != 0: ...: page.set_rotation(rotation) ...: In [11]:
Show/hide history
v1.19.2で変更:dpiパラメータのサポートを追加。
- annot_names()¶
PDFのみ:アノテーション、ウィジェット、およびリンクの名前のリストを返します。技術的には、これらはページの /Annots 配列で見つかるすべてのPDFオブジェクトの /NM 値です。
- 戻り値の型:
list
Show/hide history
新機能 v1.16.10
- annot_xrefs()¶
PDFのみ:アノテーション、ウィジェット、およびリンクの
xref番号のリストを返します。技術的には、これらはページの/Annots配列で見つかるすべてのエントリのxrefです。- 戻り値の型:
list
- 戻り値:
xref、タイプがアノテーションのタイプであるアイテム (xref, type) のリスト。リンク、フィールド、およびアノテーションを区別するためにタイプを使用します。アノテーションタイプ を参照してください。
Show/hide history
新機能 v1.17.1
- load_annot(ident)¶
PDFのみ:ident で識別されるアノテーションを返します。これはその一意の名前(PDF
/NMキー)またはxrefかもしれません。- パラメータ:
ident (str,int) -- アノテーションの名前またはxref。
- 戻り値の型:
- 戻り値:
アノテーションまたは
None。
注釈
メソッド
Page.annot_names()、Page.annot_xrefs()は、アイテムが取得およびこのメソッドを介して読み込まれる名前またはxrefのリストを提供します。Show/hide history
新機能 v1.17.1
- load_widget(xref)¶
PDFのみ:
xrefで識別されるフィールドを返します。- パラメータ:
xref (int) -- フィールドのxref。
- 戻り値の型:
- 戻り値:
フィールドまたは
None。
注釈
これはメソッド
Page.load_annot()と同様ですが、ここでは識別子としてxrefのみがサポートされています。Show/hide history
新機能 v1.19.6
- load_links()¶
最初のリンクを返します。プロパティ
first_linkの同義語です。- 戻り値の型:
- 戻り値:
ページ上の最初のリンク(または
None)。
- set_rotation(rotate)¶
PDFのみ:ページの回転を設定します。
- パラメータ:
rotate (int) -- 度数で指定された必要な回転を表す整数。90の整数倍である必要があります。値は0、90、180、270のいずれかに変換されます。
- recolor(components=1)¶
PDF only: Change the colorspace components of all objects on page.
- パラメータ:
components (int) -- The desired count of color components. Must be one of 1, 3 or 4, which results in color spaces DeviceGray, DeviceRGB or DeviceCMYK respectively. The method affects text, images and vector graphics. For instance, with the default value 1, a page will be converted to grayscale. If a page is already grayscale, the method will not cause visible changes -- independent of the value of
components.
These changes are permanent and cannot be reverted.
- clip_to_rect(rect)¶
PDF only: Permanently remove page content outside the given rectangle. This is similar to
Page.set_cropbox(), but the page's rectangle will not be changed, only the content outside the rectangle will be removed.- パラメータ:
rect (rect_like) -- The rectangle to clip to. Must be finite and its intersection with the page must not be empty.
The method works best for text: All text on the page will be removed (decided by single character) that has no intersection with the rectangle. For vector graphics, the method will remove all paths that have no intersection with the rectangle. For images, the method will remove all images that have no intersection with the rectangle. Vectors and images having an intersection with the rectangle, will be kept in their entirety.
The method roughly has the same effect as if four redactions had been applied that cover the rectangle's outside.
New in v1.26.4.
- remove_rotation()¶
PDFのみ:外観とページ内容を維持しながらページの回転を0に設定します。
- 戻り値:
この変更を実現するために使用される反転した行列。ページが回転していない場合(回転0)、Identity (アイデンティティ) が返されます。メソッドは、ページに存在するアノテーション、リンク、およびウィジェットの矩形を自動的に再計算します
- show_pdf_page(rect, docsrc, pno=0, keep_proportion=True, overlay=True, oc=0, rotate=0, clip=None)¶
PDF only: Display a page of another PDF. This is similar to
Page.insert_image()but the source page will appear like a copy of itself and will not be rasterized. This is a multi-purpose method. For example, you can use it to:既存のPDFファイルの「n-up」バージョンを作成し、複数の入力ページを1つの出力ページに結合します(例: combine.py を参照)。
「ポスター化」されたPDFファイルを作成します。つまり、各入力ページは別々の出力ページを作成する部分に分割されます(posterize.py を参照)。
include PDF-based vector images like company logos, watermarks, etc., see svg.py, which puts an SVG-based logo on each page.
- パラメータ:
rect (rect_like) -- 現在のページに画像を配置する場所。有限である必要があり、ページとの交差部分が空でない必要があります。
docsrc (Document (ドキュメント)) -- ページを含むソースPDFドキュメント。異なるドキュメントオブジェクトである必要がありますが、同じファイルであることもあります。
pno (int) -- 表示するページ番号(0から始まる、
-∞ < pno < docsrc.page_count)。指定されたページ。keep_proportion (bool) -- 幅高さ比率を維持するかどうか(デフォルト)。falseの場合、4つの角は常にターゲット矩形の境界に配置されます(回転値に関係なく)。一般的に、これは歪んだおよび/または非四角形の画像を提供します。
overlay (bool) -- 画像を前景(デフォルト)または背景に配置します。
oc (int) -- (v1.18.3で新機能) (
xref)このOCG/OCMD(ターゲットPDFで定義されている必要があります)に依存する可視性を作成します [9]。rotate (float) -- (v1.14.10で新機能) ソースの矩形を一定の角度で表示します
clip (rect_like) -- 表示するソースページの一部を選択します。デフォルトはフルページですが、有限である必要があり、ソースページとの交差部分が空でない必要があります。
注釈
In contrast to method
Document.insert_pdf(), this method does not copy annotations, widgets or links, so these objects are not included in the target [6]. But all its other resources (text, images, fonts, etc.) will be imported into the current PDF. They will therefore appear in text extractions and inget_fonts()andget_images()lists -- even if they are not contained in the visible area given by clip.例:同じソースページを90度と-90度回転して表示します。
>>> doc = pymupdf.open() # new empty PDF >>> page=doc.new_page() # new page in A4 format >>> >>> # upper half page >>> r1 = pymupdf.Rect(0, 0, page.rect.width, page.rect.height/2) >>> >>> # lower half page >>> r2 = r1 + (0, page.rect.height/2, 0, page.rect.height/2) >>> >>> src = pymupdf.open("PyMuPDF.pdf") # show page 0 of this >>> >>> page.show_pdf_page(r1, src, 0, rotate=90) >>> page.show_pdf_page(r2, src, 0, rotate=-90) >>> doc.save("show.pdf")
Show/hide history
v1.14.11で変更:パラメータreuse_xrefは非推奨となりました。ソースの矩形をターゲットの矩形の中央に配置します。任意の回転角度がサポートされます。
v1.18.3で変更:新しいパラメータ
ocが追加されました。
- new_shape()¶
PDFのみ:ページ用の新しい Shape(シェイプ) オブジェクトを作成します。
- 戻り値の型:
- 戻り値:
複合描画に使用する新しい Shape(シェイプ) オブジェクト。詳細はそちらの説明を参照してください。
- search_for(needle, *, clip=None, quads=False, flags=TEXT_DEHYPHENATE | TEXT_PRESERVE_WHITESPACE | TEXT_PRESERVE_LIGATURES | TEXT_MEDIABOX_CLIP, textpage=None)¶
ページ上で needle を検索します。
TextPage.search()のラッパーです。- パラメータ:
needle (str) -- 検索対象のテキスト。スペースを含めることができます。大文字/小文字は無視されますが、ASCII文字に対してのみ機能します:たとえば、needleが「COMPÉTENCES」の場合、needleが「compétences」の場合には見つかりません。「compÉtences」の場合は見つかります。同様に、ドイツ語のウムラウトなどにも当てはまります。
clip (rect_like) -- only search within this area. (New in v1.18.2)
quads (bool) -- 四角形の代わりに Quad (クアッド) オブジェクトのタイプを返します。
flags (int) -- 基本となる TextPage (テキストページ) によって抽出されるデータを制御します。デフォルトでは、リガチャと空白を保持し、ハイフン化 [8] が検出されます。
textpage -- 以前に作成された TextPage (テキストページ) (テキストページ)を使用します。これにより、実行時間が大幅に短縮されます。指定された場合、 'flags'および 'clip'引数は無視されます。省略された場合、一時的なテキストページが作成されます。 (v1.19.0で新規)
- 戻り値の型:
list
- 戻り値:
Rect (矩形) または Quad (クアッド) オブジェクトのリストで、通常、needleの一致を1つ囲みます。ただし、needleの一部が複数の行にまたがる場合、それぞれの部分に対して別のアイテムが生成されます。したがって、
needle = "search string"の場合、2つの四角形が生成される可能性があります。Show/hide history
Changes in v1.18.2:
リストの長さに制限はもうありません(
hit_maxパラメータの削除)。単語が行の区切りでハイフン化されている場合でも、検出されます。たとえば、needleが行の区切りで「meth-od」としてハイフン化されていても、「method」としてハイフン化されていない部分を囲む1つの四角形と、「od」としてハイフン化されていない部分を囲む別の四角形が返されます。
注釈
このメソッドは、複数行のテキストマーカーアノテーションをサポートしており、返されたリスト全体を1つのパラメータとして使用してアノテーションを作成できます。
注意
トリッキーな側面があります。検索ロジックは、連続した複数の needle の出現を1つと見なします。つまり、needle が「abc」で、ページに「abc」と「abcabc」が含まれている場合、2つの矩形のみが返され、1つは「abc」に、もう1つは「abcabc」になります。
常に
Page.get_textbox()を使用して、各矩形で実際に囲まれているテキストを確認できます。
注釈
"needle"文字列を指定する際に正規表現をサポートする機能が何度も要求されていますが、これを行う方法はありません。この方向性の何かが必要な場合は、まず希望の形式でテキストを抽出し、それを正規表現パターンと一致させて結果をサブセレクトしてください。単語を一致させる例を以下に示します。>>> pattern = re.compile(r"...") # the regex pattern >>> words = page.get_text("words") # extract words on page >>> matches = [w for w in words if pattern.search(w[4])]
matchesリストには、指定されたパターンに一致する単語が含まれます。同様の方法で、page.get_text("dict")の出力からspan["text"]を選択できます。Show/hide history
v1.18.2で変更:
clipパラメータを追加。hit_maxパラメータを削除。デフォルトの「デハイフェネート」を追加。v1.19.0で変更:TextPage (テキストページ) パラメータを追加。
- set_mediabox(r)¶
PDFのみ: ページのオブジェクト定義内で
mediaboxを設定することにより、物理ページの寸法を変更します。- パラメータ:
r (rect-like) -- 新しい
mediaboxの値。
注釈
このメソッドは、ページの他の(オプションの)矩形(
cropbox、ArtBox、TrimBox、Bleedbox)も削除し、一貫性のない状況を防ぐためにそれらをデフォルト値に戻します。注意
これにより、非空のページでは望ましくない効果が発生する可能性があるため、すべてのコンテンツの位置がこの値に依存し、したがって位置が変わるか、完全に消える可能性があります。
Show/hide history
v1.16.13で新規追加
v1.19.4で変更: 他のすべての矩形定義を削除しました。
- set_cropbox(r)¶
PDFのみ: ページの表示領域を変更します。
- パラメータ:
r (rect_like) -- ページの新しい表示領域。これは回転していない座標で指定する必要があり、空ではなく、無限ではなく、
Page.mediaboxに完全に含まれている必要があります。
実行後(ページが回転していない場合)、
Page.rectはこの矩形と等しくなりますが、必要に応じて左上の位置(0、0)にシフトされます。以下は例セッションです:>>> page = doc.new_page() >>> page.rect pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> page.cropbox # cropbox and mediabox still equal pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # now set cropbox to a part of the page >>> page.set_cropbox(pymupdf.Rect(100, 100, 400, 400)) >>> # this will also change the "rect" property: >>> page.rect pymupdf.Rect(0.0, 0.0, 300.0, 300.0) >>> >>> # but mediabox remains unaffected >>> page.mediabox pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # revert CropBox change >>> # either set it to MediaBox >>> page.set_cropbox(page.mediabox) >>> # or 'refresh' MediaBox: will remove all other rectangles >>> page.set_mediabox(page.mediabox)
- set_artbox(r)¶
- set_bleedbox(r)¶
- set_trimbox(r)¶
PDFのみ: ページオブジェクト内の対応する矩形を設定します。これらのオブジェクトの意味については、Adobe PDFリファレンス の77ページを参照してください。パラメータと制約は
Page.set_cropbox()と同じです。Show/hide history
v1.19.4で新規追加
- rotation¶
ページの回転角度を度数で含みます(非PDFタイプでは常に0)。
「ページを表示または印刷する際に、時計回りに回転させる度数。値は90の倍数でなければなりません。デフォルト値:0」
PyMuPDFでは、この属性が常に0、90、180、または270のいずれかであることを確認しています。
- Type:
int
- cropbox_position¶
PDFの場合、ページの
/CropBoxの左上の点を含みます。それ以外の場合は Point(0, 0)。- Type:
- cropbox¶
PDFのページの
/CropBoxです。常に 回転していない ページの矩形が返されます。非PDFの場合、これは常にページの矩形と等しいです。注釈
PDFでは、
/MediaBox、/CropBox、およびページの矩形の関係は混乱することがあります。MediaBoxの用語集を参照してください。- Type:
- artbox¶
- bleedbox¶
- trimbox¶
PDFのページの/ArtBox、/BleedBox、/TrimBoxです。指定されていない場合、
Page.cropboxにデフォルトで設定されます。- Type:
- mediabox_size¶
PDFのページの
Page.mediaboxの幅と高さを含みます。それ以外の場合、Page.rectの右下の座標です。- Type:
- mediabox¶
PDFのページの
mediabox、それ以外の場合はPage.rectです。- Type:
注釈
ほとんどのPDF文書および他のすべてのドキュメントタイプに対して、
page.rect == page.cropbox == page.mediaboxが真です。ただし、一部のPDFでは、表示ページが v の真の部分集合である場合があります。また、ページが回転している場合、Page.rectはPage.cropboxと等しくないかもしれません。これらの場合、上記の属性はページの要素を正しく位置付けるのに役立ちます。
- transformation_matrix¶
この行列は、PDF空間からMuPDF空間への座標の変換に使用されます。たとえば、PDFの
/Rect [x0 y0 x1 y1]では、ペア(x0、y0)が矩形の左下の点を指定します。これはMuPDFのシステムとは異なり、ここでは(x0、y0)は左上を指定します。PDF座標をこの行列で掛け算すると、(Py-)MuPDF矩形バージョンが得られます。明らかに、逆行列は再びPDF矩形を返します。- Type:
- rotation_matrix¶
- derotation_matrix¶
これらの行列は、回転したPDFページの取り扱いに使用できます。PDFページに何かを追加/挿入する際、回転していない ページの座標が常に使用されます。これらの行列は、2つの状態間での変換を支援します。例:ページが90度回転した場合、A4ページの左上のPoint(0, 0)の座標は何になりますか?
>>> page.set_rotation(90) # rotate an ISO A4 page >>> page.rect Rect(0.0, 0.0, 842.0, 595.0) >>> p = pymupdf.Point(0, 0) # where did top-left point land? >>> p * page.rotation_matrix Point(842.0, 0.0) >>>
- Type:
- first_link¶
ページの最初の Link (リンク) を含みます(または
None)。- Type:
- first_annot¶
ページの最初の Annot (注釈) を含みます(または
None)。- Type:
- first_widget¶
ページの最初の Widget (ウィジェット) を含みます(または
None)。- Type:
- number¶
ページ番号。
- Type:
int
- parent¶
所属するドキュメントオブジェクト。
- Type:
- rect¶
ページの矩形を含みます。
Page.bound()の結果と同じです。- Type:
get_links() エントリの説明¶
Page.get_links() リストの各エントリは、以下のキーを持つ辞書です:
kind:(必須)リンクの種類を示す整数。LINK_NONE、LINK_GOTO、LINK_GOTOR、LINK_LAUNCH、または LINK_URI のいずれかです。
from:(必須)ページの可視な表現上の「ホットスポット」の場所を示す Rect (矩形) (通常、カーソルが手のイメージに変わる場所です)。
page:宛先ページを示す0ベースの整数。LINK_GOTO*および *LINK_GOTOR の場合に必要ですが、それ以外の場合は無視されます。
to:宛先ページ上の宛先場所を指定する pymupdf.Point、デフォルトは pymupdf.Point(0, 0)、またはシンボリック(間接)名です。間接名が指定された場合、page = -1 が必要で、名前はPDFで定義されている必要があります。LINK_GOTO および LINK_GOTOR の場合に必要ですが、それ以外の場合は無視されます。
file:宛先ファイルを指定する文字列。LINK_GOTORおよびLINK_LAUNCHの場合に必要ですが、それ以外の場合は無視されます。
uri: LINK_URI用に指定された、インターネットリソースの宛先を示す文字列。LINK_URI の場合に必要で、それ以外の場合は無視されます。この文字列は、
"http://"、"https://"、"file://"、"ftp://"、"mailto:"など、URLのサブタイプを識別する明確なサブストリングで始めるようにしてください。そうしないと、ブラウザがテキストを解釈し、意図しない/予期しない結論に達する可能性があります。xref: リンクオブジェクトのPDFxrefを指定する整数。このエントリを何らかの方法で変更しないでください。リンクの削除と更新に必要で、それ以外の場合は無視されます。非PDFドキュメントの場合、このエントリには -1 が含まれます。また、MuPDFがサポートしていないリンクがある場合、get_links() リストのすべてのエントリに対しても-1になります。詳細については以下の注釈を参照してください。
リンクのサポートに関する注記¶
v1.10a 以降、MuPDFのリンクサポートが変更されました。これらの変更は LINK_GOTO および LINK_GOTOR というリンクタイプに影響を与えます。
読み取り get_links() メソッドおよび*first_link* プロパティチェーンに関連)¶
MuPDFが別のファイルへのリンクを検出する場合、LINK_GOTOR または LINK_LAUNCH リンクの種類を提供します。LINK_GOTOR の場合、宛先の詳細はページ番号(位置情報を含むことがある)または間接的な宛先として指定できます。
間接的な宛先が指定された場合、page = -1で示され、link.dest.dest にこの名前が含まれます。 get_links() リスト内の辞書には、この情報がto値として含まれます。
内部リンクは常にLINK_GOTOの種類です。内部リンクが間接的な宛先を指定した場合、常に解決され、結果の直接的な宛先が返されます。内部リンクには名前は返されず、未定義の宛先はリンクが無視される原因になります。
書き込み¶
PyMuPDFはリンクを構築して適切なPDFオブジェクト ソース を書き込むことにより、リンクを書き込み(更新、挿入)します。これにより、 LINK_GOTOR および LINK_GOTO リンク種別に対して間接的な宛先を指定できます(PDF 1.2 ファイル形式以前はサポートされていません)。
警告
LINK_GOTO の間接的な宛先が未定義の名前を指定した場合、このリンクは後でMuPDF / PyMuPDFで再び見つけることはできません。ただし、他のリーダーはそれを検出し、エラーとしてフラグ付けます。
一般的な注意: 間接的な LINK_GOTOR の宛先は一般的に有効性を確認できないため、常に受け入れられます。
例: 同じドキュメント内の別のページを指すリンクを挿入する方法
リンクを配置する現在のページの矩形を決定します。これは画像または一部のテキストのbboxである場合があります。
ターゲットページ番号(0から始まる)と、リンクを指定するためのそのページ上の Point (ポイント) を決定します。
辞書
d = {"kind": pymupdf.LINK_GOTO, "page": pno, "from": bbox, "to": point}を作成します。page.insert_link(d)を実行します。
Document (ドキュメント) と Page (ページ) の同様のメソッドに関する説明です。¶
これは、Document (ドキュメント) と Page (ページ) レベルでの同様のメソッドの概要です。
Document Level(ドキュメントレベル) |
Page Level(ページレベル) |
|---|---|
注釈
多くのドキュメントメソッド(左側の列)は利便性のために存在し、Document[pno].<page method> のラッパーであるだけで、各実行でページを読み込んで破棄します。
However, the first two methods work differently. They only need a page's object definition statement - the page itself will not be loaded. So e.g. Page.get_fonts() is a wrapper the other way round and defined as follows: page.get_fonts == page.parent.get_page_fonts(page.number).
When calling the Document (ドキュメント) equivalent methods then the page number is sent through as a parameter, e.g.:
Document.get_page_images(pno) or Document.get_page_text(pno)
Tip
The page number parameter, pno, is a 0-based integer -∞ < pno < page_count.