PyMuPDF Layout#
PyMuPDF Layout は、PyMuPDF 用の軽量なレイアウト解析拡張機能で、最小限のセットアップで PDF をクリーンで構造化されたデータに変換します。高速で正確かつ効率的であり、GPU を必要としません。
これは PyMuPDF ライブラリへのオプションですが推奨される追加機能であり、特により正確な意味情報を持つ構造化データの抽出が必要な場合に有用です。
インストール#
PyPI からインストールするには:
pip install pymupdf-layout
使用方法#
簡単に言えば、PyMuPDF Layout は抽出するレイアウトを検出しますが、API インターフェースには PyMuPDF4LLM が必要です。これにより、ドキュメントコンテンツを Markdown、JSON、または TXT として抽出するオプションが提供されます。
それでは、始めるために Python コーディング環境をセットアップし、PDF を開いてから、セマンティックデータ抽出に進みましょう。
パッケージを登録して PDF を開く#
まず、ライブラリをインポートしてサンプルドキュメントを開きましょう:
import pymupdf.layout
import pymupdf4llm
doc = pymupdf.open("sample.pdf")
上記のコードでは、PyMuPDF Layout は示されているようにインポートする必要があり、PyMuPDF のレイアウト機能を有効にして PyMuPDF4LLM で利用可能にするために、PyMuPDF4LLM をインポートする前にインポートする必要があることに注意してください。
最初の行を省略すると、レイアウト機能なしの標準 PyMuPDF4LLM が実行されます!
構造化データを抽出する#
PyMuPDF Layout ライブラリを有効にし、ドキュメントを読み込みました。次に構造化データを抽出しましょう。これは、Layout がバックグラウンドでヒューリスティックと機械学習を組み合わせて動作する、標準 PyMuPDF4LLM の強化版のようなもので、より良い抽出結果が得られます。
Markdown として抽出#
md = pymupdf4llm.to_markdown(doc)
JSON として抽出#
json = pymupdf4llm.to_json(doc)
TXT として抽出#
txt = pymupdf4llm.to_text(doc)
注釈
詳細については、完全な PyMuPDF4LLM API を参照してください。
最後に、次のように出力を外部ファイルに保存できます
from pathlib import Path
suffix = ".md" # or ".json" or ".txt"
Path(doc.name).with_suffix(suffix).write_bytes(md.encode())
機能の拡張#
PyMuPDF Pro との使用#
PyMuPDF Layout を PyMuPDF Pro と連携させることで機能を拡張し、Office ドキュメントを入力ファイルとして提供できるようにすることで能力を向上させることができます。この場合、PyMuPDF Pro のインポートを追加してロックを解除するだけです:
import pymupdf.layout
import pymupdf4llm
import pymupdf.pro
pymupdf.pro.unlock()
これで、次のように Office ファイルを読み込んで変換できます:
md = pymupdf4llm.to_markdown("sample.docx")
OCR サポート#
新しいレイアウト対応の PyMuPDF4LLM バージョンは、ページに OCR を適用することが有益かどうかも評価します。ヒューリスティックがこの結論に達した場合、組み込みの Tesseract-OCR モジュールが自動的に呼び出されます。その結果は、通常のページコンテンツと同様に処理されます。
ページにテキストがほとんど含まれていないが、画像や多数の文字サイズのベクターで覆われている場合、OpenCV を使用して、ページ上でテキストが検出可能かどうかをチェックします。これは、画像ベースのテキストを通常の写真などの画像と区別するために行われます。
ページにテキストが含まれているものの、読み取り不可能な文字(「�����」など)が多すぎる場合、OCR も実行されますが、影響を受けるテキスト領域のみが対象となり、ページ全体ではありません。これにより、既存のテキストや画像やベクターなどの他のコンテンツが失われるのを防ぎます。
これらのヒューリスティックが機能するには、 Tesseract installation のインストールと Python 環境での OpenCV の利用可能性の両方が必要です。どちらか一方が欠けている場合、OCR はまったく試行されません。
OCRが実際に使用されるかどうかの決定木は、以下に依存します
PyMuPDF Layoutがインポートされている
PyMuPDF4LLM API で
use_ocrが有効になっている(これはデフォルトでTrueに設定されています)OpenCV がPython環境で利用可能である
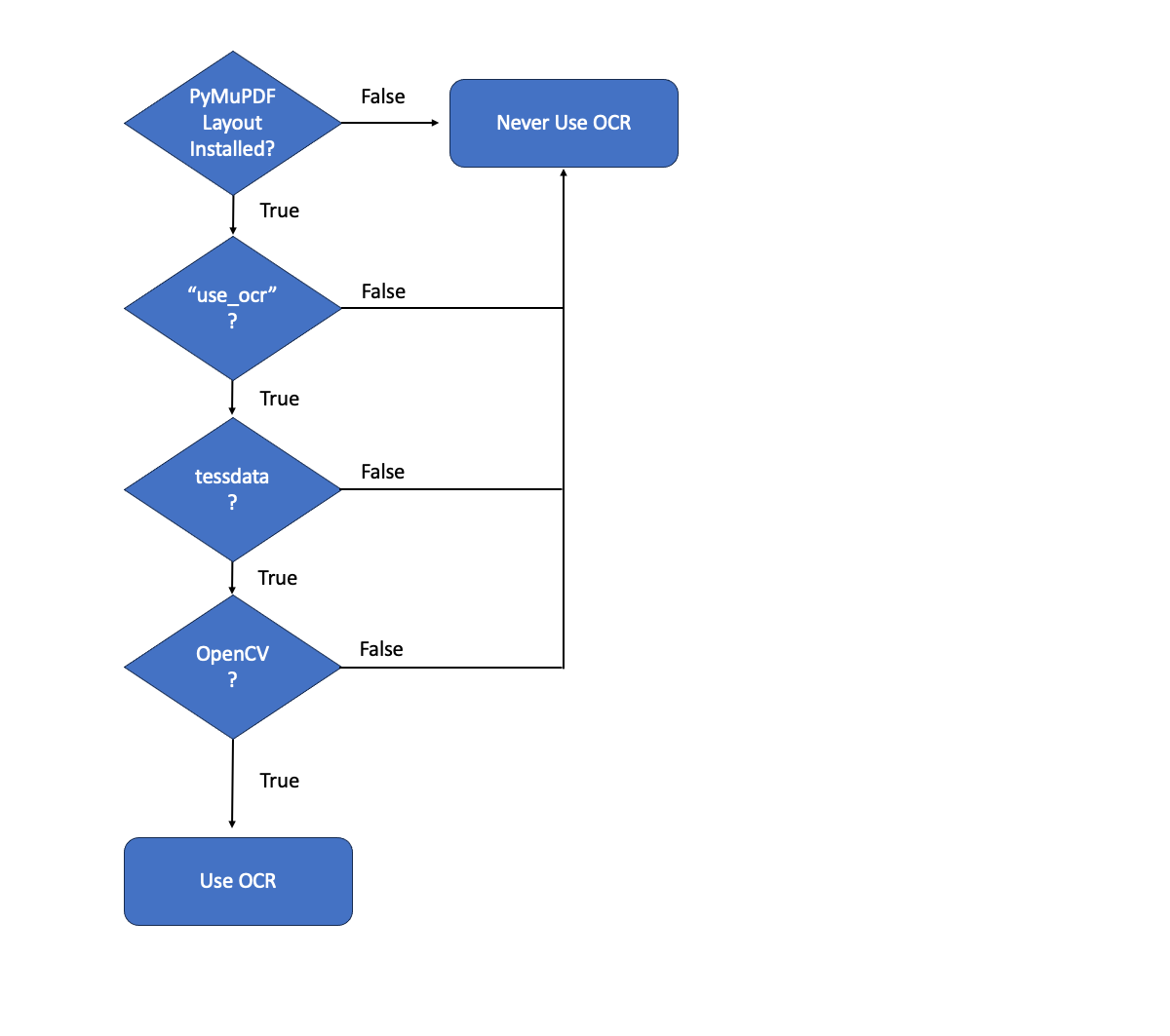
PyMuPDF Layout と PyMuPDF4LLM のパラメータに関する注意事項#
pymupdf.layout をインポートした場合、PyMuPDF4LLM はさまざまな領域でその動作を大幅に変更します。新しいメソッドが利用可能になり、一部の機能はサポートされなくなります。変更の詳細については、このサイト を参照してください。このウェブサイトは、改善作業を続けながら最新の状態に保たれています。