TextPage (テキストページ)¶
このクラスは、文書ページに表示されるテキストと画像を表します。すべての MuPDF document types がサポートされています。
テキストページを作成する通常の方法は、DisplayList.get_textpage() および Page.get_textpage() です。このクラスにはメソッドのセットが制限されているため、Page (ページ) 内にはより使いやすいラッパーが存在します。この表の最後の列には、対応する Page (ページ) メソッドが示されています。
このクラスに関する詳細な説明については、付録2を参照してください。
メソッド |
説明 |
page get_textまたはsearchメソッド |
|---|---|---|
プレーンテキストを抽出します |
"text" |
|
前述の同義語 |
"text" |
|
ブロックにグループ化されたプレーンテキスト |
"blocks" |
|
すべての単語とそのバウンディングボックス |
"words" |
|
HTML形式のページコンテンツ |
"html" |
|
XHTML形式のページコンテンツ |
"xhtml" |
|
XML形式のページテキスト |
"xml" |
|
辞書 形式のページコンテンツ |
"dict" |
|
JSON形式のページコンテンツ |
"json" |
|
辞書 形式のページコンテンツ |
"rawdict" |
|
JSON形式のページコンテンツ |
"rawjson" |
|
ページ内の文字列を検索します |
クラスAPI
- class TextPage¶
- extractText(sort=False)¶
- extractTEXT(sort=False)¶
ページの完全なテキストの文字列を返します。テキストはUTF-8ユニコードで、文書作成時に指定された順序と同じです。
- パラメータ:
sort (bool) -- (new in v1.19.1) sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order.
- 戻り値の型:
str
- extractBLOCKS()¶
テキストページの内容を、ブロックごとにグループ化されたテキスト行のリストとして返します。各リストアイテムは次のようになります:
``(x0, y0, x1, y1, "lines in the block", block_no, block_type)``
The first four entries are the block's bbox coordinates, block_type is 1 for an image block, 3 for a vector block, and 0 for text. block_no is the block sequence number. Multiple text lines are joined via line breaks.
For an image block, its bbox and a text line with some image meta information is included -- not the image content. Image blocks are included only if the extraction flag bit
TEXT_PRESERVE_IMAGESis set. An image block tuple will look like this:``(x0, y0, x1, y1, "<image: colorspace-name, w: width, h: height, bpc: bits_per_component>\n", block_no, 1)``
For a vector block, the following item will be included. Vector blocks are included only if the extraction flag bit
TEXT_COLLECT_VECTORSis set. A vector block tuple will look like this:``(x0, y0, x1, y1, "<vector stroked, color: #rrggbb, alpha: 255, is-rect: true, continues: false>\n", block_no, 3)``
The keyword "vector" is followed by either "stroked" or "filled". The color is given in HTML (hexadecimal RGB) format. Property
is-rectis true, if the vector is not a curve and parallel to the x- or y-axis. So in essence is either a real rectangle or a line segment. Propertycontinuesindicates whether the vector is part of a path (and not the first item).注釈
When no further details are needed (as provided by
Page.get_drawings()), then this is an inexpensive way to extract basic vector graphics information. Another major advantage is that all block types (text, images and vectors) are included in the output in the same order as they are present in the page'scontentsstream.これは、必要な読み取り順序でプレーンテキストを出力するのに十分な情報を持つ高速なメソッドです。
- 戻り値の型:
list
- extractWORDS(delimiters=None)¶
Changed in v1.23.5: added
delimitersparameter
テキストページの内容を、bbox情報を持つ単語のリストとして返します。このリストのアイテムは次のようになります:
(x0, y0, x1, y1, "word", block_no, line_no, word_no)
- パラメータ:
delimiters (str) -- (new in v1.23.5) use these characters as additional word separators. By default, all white spaces (including the non-breaking space
0xA0) indicate start and end of a word. Now you can specify more characters causing this. For instance, the default will return"john.doe@outlook.com"as one word. If you specifydelimiters="@."then the four words"john","doe","outlook","com"will be returned. Other possible uses include ignoring punctuation charactersdelimiters=string.punctuation. The "word" strings will not contain any delimiting character.
This is a high-speed method which e.g. allows extracting text from within given areas or recovering the text reading sequence.
- 戻り値の型:
list
- extractHTML()¶
HTML形式の文字列としてのテキストページの内容を返します。このバージョンには完全なフォーマットと位置情報が含まれています。画像も含まれており(base64文字列としてエンコードされています)、Pythonで出力を解釈するためにはHTMLパッケージが必要です。インターネットブラウザはこの情報を適切に表示できるはずですが、HTML出力の品質の制御 を参照してください。
- 戻り値の型:
str
- extractDICT(sort=False)¶
TextPageの内容をPythonの辞書として取得します。HTMLと同じ情報の詳細を提供します。構造については以下を参照してください。
- パラメータ:
sort (bool) -- (new in v1.19.1) sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order.
- 戻り値の型:
dict
- extractJSON(sort=False)¶
TextPageの内容をJSON形式の文字列として取得します。
json.dumps(TextPage.extractDICT())によって作成されます。これは過去の互換性のために含まれています。おそらく、結果をファイルに出力する際にのみこのメソッドを使用するでしょう。このメソッドはバイナリ画像データを検出し、それらをBase64エンコードされた文字列に変換します。- パラメータ:
sort (bool) -- (new in v1.19.1) sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order.
- 戻り値の型:
str
- extractXHTML()¶
TextPageの内容をXHTML形式の文字列として取得します。テキスト情報の詳細は
extractTEXT()と比較できますが、画像も含まれます(Base64エンコードされています)。このメソッドは元の視覚的な外観を再作成しようとしません。- 戻り値の型:
str
- extractXML()¶
TextPageの内容をXML形式の文字列として取得します。これにはページ上の各文字に関する完全なフォーマット情報が含まれています:フォント、サイズ、行、段落、位置、色など。画像は含まれていません。Pythonで出力を解釈するにはXMLパッケージが必要です。
- 戻り値の型:
str
- extractRAWDICT(sort=False)¶
TextPageの内容をPythonの辞書として取得します。技術的には
extractDICT()と類似しており、その情報をサブセットとして含みます(画像も含まれます)。詳細については以下を参照してください。- パラメータ:
sort (bool) -- (new in v1.19.1) sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order.
- 戻り値の型:
dict
- extractRAWJSON(sort=False)¶
TextPageの内容をJSON形式の文字列として取得します。
json.dumps(TextPage.extractRAWDICT())によって作成されます。おそらく、結果をファイルに出力する際にのみこのメソッドを使用するでしょう。このメソッドはバイナリ画像データを検出し、それらをBase64エンコードされた文字列に変換します。- パラメータ:
sort (bool) -- (new in v1.19.1) sort the output by vertical, then horizontal coordinates. In many cases, this should suffice to generate a "natural" reading order.
- 戻り値の型:
str
- search(needle, quads=False)¶
変更内容 v1.18.2
文字列 を検索し、見つかった位置のリストを返します。
- パラメータ:
needle (str) -- 検索対象の文字列。ASCII文字だけで構成されている場合、大文字と小文字はすべて一致します。これはまだ、例えば "Ä" と "ä" のような場合には機能しません。
quads (bool) -- 長方形の代わりに四辺形を返すかどうか。
- 戻り値の型:
list
- 戻り値:
見つかった needle の出現箇所を囲む Rect (矩形) または Quad (クアッド) オブジェクトのリスト。検索文字列にはスペースが含まれる可能性があるため、その部分が異なる行に存在することがあります。この場合、複数の長方形(または四辺形)が返されます (v1.18.2 で変更) 。このメソッドは 今ではハイフネーションに対応しており 、例えば "method" が "meth-" と "od" という2つの部分に分かれている場合でも、"meth"(ハイフンなし)と "od" の2つの長方形が含まれます。
注釈
v1.18.2 での変更内容の概要:
hit_maxパラメータが削除され、すべてのヒットが常に返されます。TextPage (テキストページ) の Rect (矩形) パラメータが尊重され、この領域内のテキストのみが検査されます。完全に含まれる bboxes を持つ文字のみが考慮されます。
Page.search_for()のラッパーメソッドも対応するクリップパラメータをサポートしています。ハイフネーションされた単語 も見つかります。
同じ行内の 重複する長方形 は自動的に結合されます。このような分割は、同じ検索対象の一部を含む複数のマークコンテンツグループによって作成されたアーティファクトと仮定されます。
例:Quad 対 Rect:needle "pymupdf" を検索する場合、対応するエントリは青い長方形であるか、quads が指定された場合は四辺形 Quad(ul, ur, ll, lr) になります。

- rect¶
テキストページに関連付けられた矩形。これは、作成ページの矩形または
Page.get_textpage()およびテキスト抽出/検索メソッドのclipパラメーターと一致する場合があります。注釈
テキスト検索およびほとんどのテキスト抽出の出力は この矩形に制限されます。ただし、(X)HTMLおよびXMLの出力は常にフルページを抽出します。
辞書出力の構造¶
TextPage.extractDICT()、TextPage.extractJSON() 、TextPage.extractRAWDICT() 、TextPage.extractRAWJSON() は、ページのテキストおよび画像コンテンツを含む辞書を返します。これらの4つのメソッドの辞書構造はほぼ同じです。これらは、ブロック、行、スパン、文字の情報階層をテキストページにできるだけ正確にマップし、各要素を独自のサブ辞書で表現することを目指しています。
ページ は ブロック辞書 のリストから構成されます。
(テキスト) ブロック は、行辞書 のリストから構成されます。
行 は、スパン辞書 のリストから構成されます。
スパン は、テキスト自体またはRAWバリアントの場合、文字辞書 のリストから構成されます。
RAWバリアント:文字 はその起源、bbox、およびUnicodeの辞書です。
ここでのすべてのPyMuPDFジオメトリオブジェクト(ポイント、矩形、行列)は、rect_like タプル の形式で Rect (矩形) などの代わりに使用されます。これは、パフォーマンスとメモリの考慮事項からです。
このコードはCで書かれており、Pythonタプルは簡単に生成できます。一方、ジオメトリオブジェクトはPythonソースでのみ定義されています。 各Pythonタプルを対応するジオメトリオブジェクトに変換することは、実行時間を大幅に(かつ不必要に)増加させるでしょう。
4つのタプルは約168バイト、対応する Rect (矩形) は472バイトです - サイズのほぼ3倍です。テキストが豊富なページの「dict」辞書には300以上のbboxオブジェクトが含まれているため、これらは4タプルとして約50 KBのストレージを必要としますが、Rect (矩形) オブジェクトでは約140 KBです。このようなページの「rawdict」出力は、4,000から5,000 のbboxを含む場合がありますので、この場合は750 KB対2 MBとなります。
また、注意してください。 bboxes (rect_like 4タプル)のみが返され、TextPage (テキストページ) には 完全な位置情報 が含まれていることです - Quad形式で。これはメモリの考慮事項です。quad_like には488バイト(rect_like の3倍のサイズ)が必要です。言及した数の生成されたbboxを考えると、quad_like 情報を返すことは重大な影響を与えるでしょう。
ほとんどの場合、水平テキストのみ を扱っており、bboxは十分な情報を提供します。
さらに、フルクワッド情報は失われていません。必要に応じて、以下のリストから適切な関数を使用して行、スパン、および文字のクワッド情報を回復できます:
recover_quad()– 完全なスパンのクワッドrecover_span_quad()– スパンの一部の文字のクワッドrecover_line_quad()– 行のクワッドrecover_char_quad()– 文字のクワッド
前述のように、これらの関数を使用する必要があるのは、テキストが 水平に書かれていない 場合 - line["dir"] != (1, 0) - およびテキストマーカーアノテーション(Page.add_highlight_annot() など)でクワッドが必要な場合のみです。
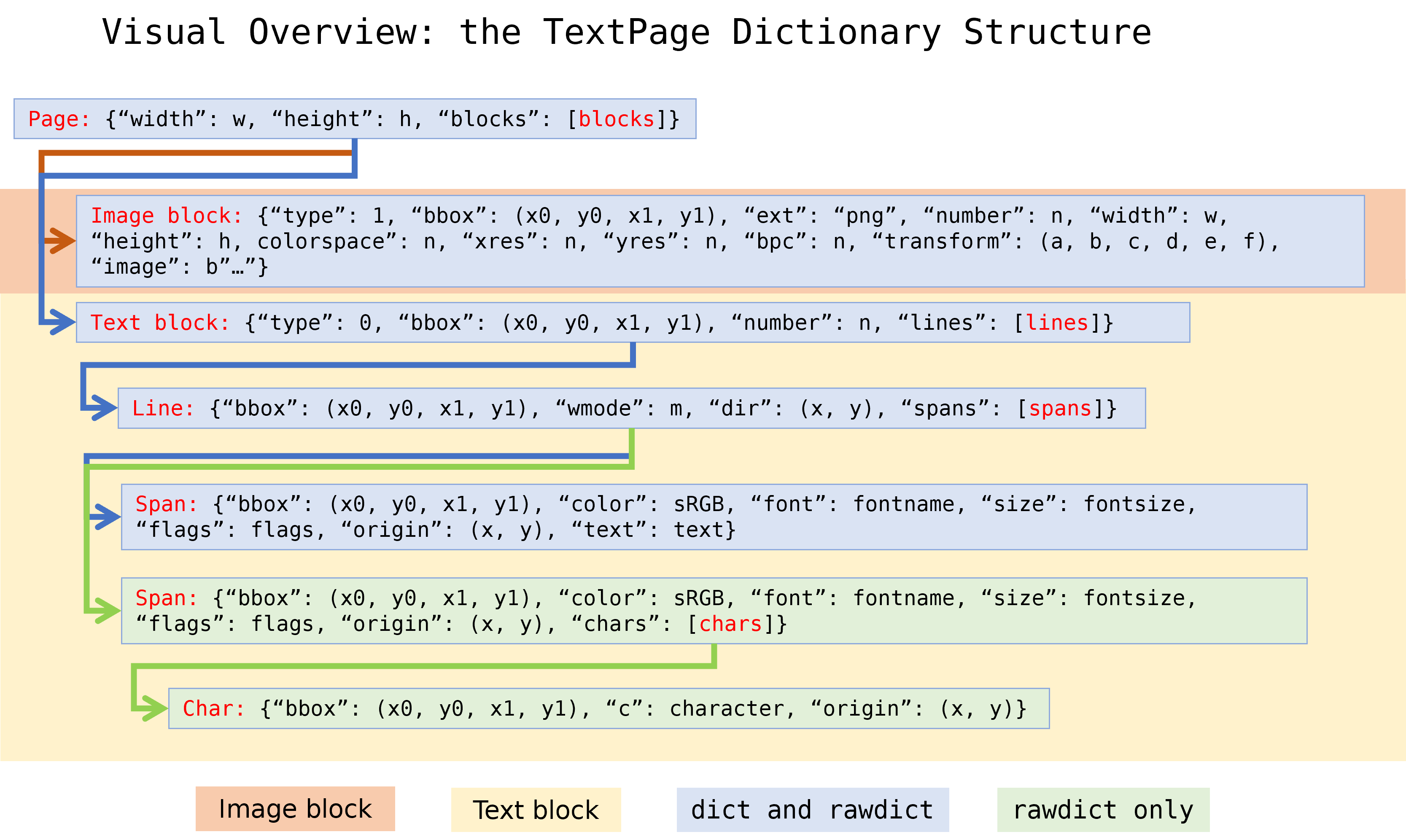
ページ辞書¶
キー |
値 |
|---|---|
width |
|
height |
|
blocks |
ブロック辞書の list |
ブロック辞書¶
Block dictionaries come in different formats for vector blocks, image blocks and text blocks. Vector blocks are included only if the extraction flag bit TEXT_COLLECT_VECTORS is set. Image blocks are included only if the extraction flag bit TEXT_PRESERVE_IMAGES is set.
Vector block:
キー |
値 |
|---|---|
type |
3 = vector ( |
bbox |
vector bbox on page ( |
number |
block count ( |
stroked |
either stroked ( |
isrect |
whether the vector is axis-parallel ( |
continues |
whether the vector is (not the last) part of a sequence of vectors in a path ( |
color |
sRGB integer, e.g. 0xRRGGBB ( |
alpha |
Transparency, a value in |
This information is a true subset of the output of Page.get_drawings(). Its advantage is its speed (because it is extracted alongside one TextPage (テキストページ) creation) and the fact that vector blocks are included in the overall page content sequence together with text and images.
画像ブロック:
キー |
値 |
|---|---|
type |
1 = image ( |
bbox |
ページ上の画像の境界ボックス( |
number |
block count ( |
ext |
image type ( |
width |
original image width ( |
height |
original image height ( |
colorspace |
colorspace component count ( |
xres |
resolution in x-direction ( |
yres |
resolution in y-direction ( |
bpc |
bits per component ( |
transform |
画像矩形を境界ボックスに変換する行列( |
size |
size of the image in bytes ( |
image |
image content ( |
mask |
image mask content ( |
"ext"キーの可能な値は、"bmp"、"gif"、"jpeg"、"jpx"(JPEG 2000)、"jxr"(JPEG XR)、"png"、"pnm"、および "tiff" です。
注釈
ページ上の すべての画像 が画像ブロックとして生成されます。したがって、画像が異なる場所で表示される場合、重複が発生する可能性があります。
TextPage (テキストページ) および対応するメソッド
Page.get_text()は すべてのドキュメントタイプ で利用可能です。PDFドキュメントの場合、Document.get_page_images()/Page.get_images()は画像リストに関する機能が一部重複しています。ただし、これらのリストは同じアイテムを 含むかどうかは必ずしも保証されません。違いがある場合、その原因はおそらく次のいずれかです。PDFページの「インライン」画像(Adobe PDFリファレンス のページ214を参照)はテキストページに含まれていますが、
Page.get_images()には 表示されません。アノテーションにも画像が含まれることがあります。これらは
Page.get_images()には 表示されません。テキストページの画像ブロックは、画像の場所 ごとに 生成されます。重複があるかどうかに関係なくです。これは、
Page.get_images()では各画像が1回だけリストされる(参照名ごとに)のとは対照的です。ページの
object定義で言及されている画像は、常にPage.get_images()に表示されます [1]。ただし、ページのcontentsに「表示」コマンドがない場合、画像はテキストページに表示されません。
画像の「変換行列」は、
bbox / transform == pymupdf.Rect(0, 0, 1, 1)という式が真である場合の行列です。詳細はこちらを参照してください: 画像変換行列。A transparent image may be accompanied by a mask image. This is stored under key
"mask"and has the format of aDeviceGrayPNG image. Otherwise the value of this key isNone. If present, you may be able to recover (an equivalent of) the original image -- i.e. with transparency -- by creating Pixmap objects from the "image", respectively "mask" values and overlay them. This is not guaranteed to always work because mask images come in multiple formats, of which not all qualify for the conditions under which overlaying Pixmaps are supported. Here is a code snippet:
>>> base = pymupdf.Pixmap(block["image"])
>>> mask = pymupdf.Pixmap(block["mask"])
>>> result = pymupdf.Pixmap(base, mask)
テキストブロック:
キー |
値 |
|---|---|
type |
0 = テキスト (int) |
bbox |
ブロックの矩形、 |
number |
ブロック数 (int) |
lines |
テキスト行の辞書の list |
Line Dictionary¶
キー |
値 |
|---|---|
bbox |
行の矩形、 |
wmode |
書き込みモード (int):0 = 水平、1 = 垂直 |
dir |
書き込み方向、 |
spans |
スパン辞書の list |
The value of key "dir" is the unit vector dir = (cosine, -sine) of the angle, which the text has relative to the x-axis [2]. See the following picture: The word in each quadrant (counter-clockwise from top-right to bottom-right) is rotated by 30, 120, 210 and 300 degrees respectively.

Span Dictionary¶
スパンには実際のテキストが含まれています。フォントのプロパティが異なるテキストを含む場合を除き、1行には複数のスパンが含まれます。
バージョン1.14.17で変更されました:スパンには bbox キーが含まれています(再び)。
バージョン1.17.6で変更されました:スパンには origin キーも含まれています。
キー |
値 |
|---|---|
bbox |
スパンの矩形、 |
origin |
最初の文字の原点、 |
font |
フォント名 (str) |
ascender |
フォントのアセンダー (float) |
descender |
フォントのディセンダー (float) |
size |
フォントサイズ (float) |
flags |
フォントの特性 (int) |
char_flags |
char characteristics (int) |
color |
text color in sRGB format 0xRRGGBB (int). |
alpha |
text opacity 0..255 (int). |
text |
( |
chars |
( |
Show/hide history
(New in version 1.25.3.0): Added "alpha" item.
バージョン1.16.0で新しく追加された項目:. 「color」 はsRGB(int)形式でエンコードされたテキストカラーで、例えば赤の場合は0xFF0000です。この整数をフォーマット(r、g、b)(PDFでは0から1の範囲の浮動小数点値) sRGB_to_pdf() または(R、G、B)、sRGB_to_rgb() (整数値で0から255の範囲)に変換するための関数があります。
バージョン1.18.5で新しく追加された項目: 「ascender」 と 「descender」 は、フォントのプロパティで、 fontsize 1に対して提供されます。ディセンダーは負の値であることに注意してください。以下の画像は、他の値やプロパティとの関係を示しています。

これらの数字は、文字(またはスパン)の最小の高さを計算するために使用できます。これは、実際には行の高さを表す「bbox」値ではなく、フォントサイズに完全に合わせるための高さを表します。次のコードは、スパンのbboxを、内部のテキストに完全に合わせる高さが フォントサイズ となるように再計算します:
>>> a = span["ascender"]
>>> d = span["descender"]
>>> r = pymupdf.Rect(span["bbox"])
>>> o = pymupdf.Point(span["origin"]) # its y-value is the baseline
>>> r.y1 = o.y - span["size"] * d / (a - d)
>>> r.y0 = r.y1 - span["size"]
>>> # r now is a rectangle of height 'fontsize'
注意
上記の計算は、より大きな 高さをもたらす可能性があります。これは、OCRedドキュメントなどで発生する可能性があります。MuPDFは、PDFに存在する fontsize から独立して、適切なbboxの高さを見つけ出そうとします。したがって、span["bbox"] の高さが span["size"] よりも大きいことを確認してください。
注釈
PyMuPDFに対して、pymupdf.TOOLS.set_small_glyph_heights(True) を実行して、上記のすべてを自動的に実行するように依頼することができます。これは、すべての後続のテキスト検索とテキスト抽出が、縮小されたグリフの高さを基に行われるようにするためのグローバルパラメータを設定します。
以下は、元のspanの矩形を赤で、再計算された高さを持つ矩形を青で示しています。

"flags" は、フォントのプロパティを表す整数で、最初のビット 0 を除いて次のように解釈されます:
bit 0: superscripted (
TEXT_FONT_SUPERSCRIPT) -- not a font property, detected by MuPDF code.bit 1: italic (
TEXT_FONT_ITALIC)bit 2: serifed (
TEXT_FONT_SERIFED)bit 3: monospaced (
TEXT_FONT_MONOSPACED)bit 4: bold (
TEXT_FONT_BOLD)
これらの特性は、次のようにテストできます:
>>> if flags & pymupdf.TEXT_FONT_BOLD & pymupdf.TEXT_FONT_ITALIC:
print(f"{span['text']=} is bold and italic")
ビット1からビット4までがフォントのプロパティであり、つまりフォントプログラムにエンコードされています。 ただし、この情報は必ずしも正確または完全ではないことに注意してください。フォントにはしばしば誤ったデータが含まれていることがあります。
"char_flags" is an integer, which represents extra character properties:
bit 0: strikeout.
bit 1: underline.
bit 2: synthetic (always 0, see char dictionary).
bit 3: filled.
bit 4: stroked.
bit 5: clipped.
For example if not filled and not stroked (if not (char_flags & 2**3 & 2**4):
...) then the text will be invisible.
(char_flags is new in v1.25.2.)
文字のディクショナリ、extractRAWDICT()¶
キー |
値 |
|---|---|
origin |
文字の左ベースラインポイント、 |
bbox |
文字の矩形、 |
synthetic |
bool. |
c |
文字(ユニコード) |
(synthetic is new in v1.25.3.)
この画像は、文字のbboxとそのquadの関係を示しています:
脚注